The dispersion is calculated as a difference. Dispersion of a discrete random variable
Mathematical expectation (average value) random variable X , given on a discrete probability space, is called the number m =M[X]=∑x i p i , if the series converges absolutely.
Service assignment. With an online service calculated expected value, variance and standard deviation(see example). In addition, a graph of the distribution function F(X) is plotted.
Properties of the mathematical expectation of a random variable
- The mathematical expectation of a constant value is equal to itself: M[C]=C , C is a constant;
- M=C M[X]
- The mathematical expectation of the sum of random variables is equal to the sum of their mathematical expectations: M=M[X]+M[Y]
- The mathematical expectation of the product of independent random variables is equal to the product of their mathematical expectations: M=M[X] M[Y] if X and Y are independent.
Dispersion Properties
- The dispersion of a constant value is equal to zero: D(c)=0.
- The constant factor can be taken out from under the dispersion sign by squaring it: D(k*X)= k 2 D(X).
- If random variables X and Y are independent, then the variance of the sum is equal to the sum of the variances: D(X+Y)=D(X)+D(Y).
- If random variables X and Y are dependent: D(X+Y)=DX+DY+2(X-M[X])(Y-M[Y])
- For the variance, the computational formula is valid:
D(X)=M(X 2)-(M(X)) 2
Example. The mathematical expectations and variances of two independent random variables X and Y are known: M(x)=8 , M(Y)=7 , D(X)=9 , D(Y)=6 . Find the mathematical expectation and variance of the random variable Z=9X-8Y+7 .
Decision. Based on the properties of mathematical expectation: M(Z) = M(9X-8Y+7) = 9*M(X) - 8*M(Y) + M(7) = 9*8 - 8*7 + 7 = 23 .
Based on the dispersion properties: D(Z) = D(9X-8Y+7) = D(9X) - D(8Y) + D(7) = 9^2D(X) - 8^2D(Y) + 0 = 81*9 - 64*6 = 345
Algorithm for calculating the mathematical expectation
Properties of discrete random variables: all their values can be renumbered natural numbers; Assign each value a non-zero probability.- Multiply the pairs one by one: x i by p i .
- We add the product of each pair x i p i .
For example, for n = 4: m = ∑x i p i = x 1 p 1 + x 2 p 2 + x 3 p 3 + x 4 p 4
Example #1.
| x i | 1 | 3 | 4 | 7 | 9 |
| pi | 0.1 | 0.2 | 0.1 | 0.3 | 0.3 |
The mathematical expectation is found by the formula m = ∑x i p i .
Mathematical expectation M[X].
M[x] = 1*0.1 + 3*0.2 + 4*0.1 + 7*0.3 + 9*0.3 = 5.9
The dispersion is found by the formula d = ∑x 2 i p i - M[x] 2 .
Dispersion D[X].
D[X] = 1 2 *0.1 + 3 2 *0.2 + 4 2 *0.1 + 7 2 *0.3 + 9 2 *0.3 - 5.9 2 = 7.69
Standard deviation σ(x).
σ = sqrt(D[X]) = sqrt(7.69) = 2.78
Example #2. A discrete random variable has the following distribution series:
| X | -10 | -5 | 0 | 5 | 10 |
| R | a | 0,32 | 2a | 0,41 | 0,03 |
Decision. The value a is found from the relationship: Σp i = 1
Σp i = a + 0.32 + 2 a + 0.41 + 0.03 = 0.76 + 3 a = 1
0.76 + 3 a = 1 or 0.24=3 a , whence a = 0.08
Example #3. Determine the distribution law of a discrete random variable if its variance is known, and x 1
p 1 =0.3; p2=0.3; p3=0.1; p 4 \u003d 0.3
d(x)=12.96
Decision.
Here you need to make a formula for finding the variance d (x) :
d(x) = x 1 2 p 1 +x 2 2 p 2 +x 3 2 p 3 +x 4 2 p 4 -m(x) 2
where expectation m(x)=x 1 p 1 +x 2 p 2 +x 3 p 3 +x 4 p 4
For our data
m(x)=6*0.3+9*0.3+x 3 *0.1+15*0.3=9+0.1x 3
12.96 = 6 2 0.3+9 2 0.3+x 3 2 0.1+15 2 0.3-(9+0.1x 3) 2
or -9/100 (x 2 -20x+96)=0
Accordingly, it is necessary to find the roots of the equation, and there will be two of them.
x 3 \u003d 8, x 3 \u003d 12
We choose the one that satisfies the condition x 1
Distribution law of a discrete random variable
x 1 =6; x2=9; x 3 \u003d 12; x4=15
p 1 =0.3; p2=0.3; p3=0.1; p 4 \u003d 0.3
Dispersion is a measure of dispersion that describes the relative deviation between data values and the mean. It is the most commonly used measure of dispersion in statistics, calculated by summing, squared, the deviation of each data value from the mean. The formula for calculating the variance is shown below:
![]()
s 2 - sample variance;
x cf is the mean value of the sample;
n — sample size (number of data values),
(x i – x cf) is the deviation from the mean value for each value of the data set.
To better understand the formula, let's look at an example. I don't really like cooking, so I rarely do it. However, in order not to die of hunger, from time to time I have to go to the stove to implement the plan to saturate my body with proteins, fats and carbohydrates. The data set below shows how many times Renat cooks food each month:
The first step in calculating the variance is to determine the sample mean, which in our example is 7.8 times a month. The remaining calculations can be facilitated with the help of the following table.

The final phase of calculating the variance looks like this:
![]()
For those who like to do all the calculations in one go, the equation will look like this:
Using the raw count method (cooking example)
There is a more efficient way to calculate the variance, known as the "raw counting" method. Although at first glance the equation may seem quite cumbersome, in fact it is not so scary. You can verify this, and then decide which method you like best.

is the sum of each data value after squaring,
is the square of the sum of all data values.
Don't lose your mind right now. Let's put it all in the form of a table, and then you will see that there are fewer calculations here than in the previous example.


As you can see, the result is the same as when using the previous method. The advantages of this method become apparent as the sample size (n) grows.
Calculating variance in Excel
As you probably already guessed, Excel has a formula that allows you to calculate the variance. Moreover, starting from Excel 2010, you can find 4 varieties of the dispersion formula:
1) VAR.V - Returns the variance of the sample. Boolean values and text are ignored.
2) VAR.G - Returns the population variance. Boolean values and text are ignored.
3) VASP - Returns the sample variance, taking into account boolean and text values.
4) VARP - Returns the variance of the population, taking into account logical and text values.
First, let's look at the difference between a sample and a population. The purpose of descriptive statistics is to summarize or display data in such a way as to quickly get a big picture, so to speak, an overview. Statistical inference allows you to make inferences about a population based on a sample of data from this population. The population represents all possible outcomes or measurements that are of interest to us. A sample is a subset of a population.
For example, we are interested in the totality of a group of students from one of the Russian universities and we need to determine the average score of the group. We can calculate the average performance of students, and then the resulting figure will be a parameter, since the whole population will be involved in our calculations. However, if we want to calculate the GPA of all students in our country, then this group will be our sample.
The difference in the formula for calculating the variance between the sample and the population is in the denominator. Where for the sample it will be equal to (n-1), and for the general population only n.
Now let's deal with the functions of calculating the variance with endings BUT, in the description of which it is said that the calculation takes into account text and logical values. In this case, when calculating the variance of a specific data set where non-numeric values occur, Excel will interpret text and false booleans as 0, and true booleans as 1.
So, if you have an array of data, it will not be difficult to calculate its variance using one of the Excel functions listed above.

The main generalizing indicators of variation in statistics are dispersion and standard deviation.
Dispersion it arithmetic mean squared deviations of each feature value from the total mean. The variance is usually called the mean square of the deviations and is denoted 2 . Depending on the initial data, the variance can be calculated from the arithmetic mean, simple or weighted:
unweighted (simple) dispersion;
 weighted variance.
weighted variance.
Standard deviation is a generalizing characteristic of absolute dimensions variations trait in the aggregate. It is expressed in the same units as the sign (in meters, tons, percent, hectares, etc.).
The standard deviation is the square root of the variance and is denoted by :
 unweighted standard deviation;
unweighted standard deviation;
 weighted standard deviation.
weighted standard deviation.
The standard deviation is a measure of the reliability of the mean. The smaller the standard deviation, the better the arithmetic mean reflects the entire represented population.
The calculation of the standard deviation is preceded by the calculation of the variance.
The procedure for calculating the weighted variance is as follows:
1) determine the arithmetic weighted average:
2) calculate the deviations of the options from the average:
3) square the deviation of each option from the mean:
4) multiply squared deviations by weights (frequencies):
5) summarize the received works:
![]()
6) the resulting amount is divided by the sum of the weights:

Example 2.1

Calculate the arithmetic weighted average:

The values of deviations from the mean and their squares are presented in the table. Let's define the variance:

The standard deviation will be equal to:

If the source data is presented as an interval distribution series , then you first need to determine the discrete value of the feature, and then apply the method described.
Example 2.2
Let us show the calculation of the variance for the interval series on the data on the distribution of the sown area of the collective farm by wheat yield.

The arithmetic mean is:

Let's calculate the variance:

6.3. Calculation of the dispersion according to the formula for individual data
Calculation technique dispersion complex, and for large values of options and frequencies can be cumbersome. Calculations can be simplified using the dispersion properties.
The dispersion has the following properties.
1. A decrease or increase in the weights (frequencies) of a variable feature by a certain number of times does not change the dispersion.
2. Decreasing or increasing each feature value by the same constant value BUT dispersion does not change.
3. Decreasing or increasing each feature value by a certain number of times k respectively reduces or increases the variance in k 2 times standard deviation in k once.
4. The variance of a feature relative to an arbitrary value is always greater than the variance relative to the arithmetic mean by the square of the difference between the average and arbitrary values:
![]()
If a BUT 0, then we arrive at the following equality:
i.e., the variance of a feature is equal to the difference between the mean square of the feature values and the square of the mean.
Each property can be used alone or in combination with others when calculating the variance.
The procedure for calculating the variance is simple:
1) determine arithmetic mean :
2) square the arithmetic mean:

3) square the deviation of each variant of the series:
X i 2 .
4) find the sum of squares of options:
5) divide the sum of squares of options by their number, i.e. determine the average square:
6) determine the difference between the mean square of the feature and the square of the mean:
Example 3.1 We have the following data on the productivity of workers:

Let's make the following calculations:
![]()
However, this characteristic alone is not yet sufficient for the study of a random variable. Imagine two shooters who are shooting at a target. One shoots accurately and hits close to the center, and the other ... just having fun and not even aiming. But what's funny is that average the result will be exactly the same as the first shooter! This situation is conditionally illustrated by the following random variables:
The "sniper" mathematical expectation is equal to , however, for the "interesting person": - it is also zero!
Thus, there is a need to quantify how far scattered bullets (values of a random variable) relative to the center of the target (expectation). well and scattering translated from Latin only as dispersion .
Let's see how this numerical characteristic is determined in one of the examples of the 1st part of the lesson: 
There we found a disappointing mathematical expectation of this game, and now we have to calculate its variance, which denoted through .
Let's find out how far the wins/losses are "scattered" relative to the average value. Obviously, for this we need to calculate differences between values of a random variable and her mathematical expectation:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Now it seems to be necessary to sum up the results, but this way is not good - for the reason that the oscillations to the left will cancel each other out with the oscillations to the right. So, for example, the "amateur" shooter (example above) the differences will be ![]() , and when added they will give zero, so we will not get any estimate of the scattering of his shooting.
, and when added they will give zero, so we will not get any estimate of the scattering of his shooting.
To get around this annoyance, consider modules differences, but for technical reasons, the approach has taken root when they are squared. It is more convenient to arrange the solution in a table: 
And here it begs to calculate weighted average the value of the squared deviations. What is it? It's theirs expected value, which is the measure of scattering:
![]() – definition dispersion. It is immediately clear from the definition that variance cannot be negative- take note for practice!
– definition dispersion. It is immediately clear from the definition that variance cannot be negative- take note for practice!
Let's remember how to find the expectation. Multiply the squared differences by the corresponding probabilities (Table continuation):
- figuratively speaking, this is "traction force",
and summarize the results:
Don't you think that against the background of winnings, the result turned out to be too big? That's right - we were squaring, and in order to return to the dimension of our game, we need to take the square root. This value is called standard deviation
and is denoted by the Greek letter "sigma":
Sometimes this meaning is called standard deviation .
What is its meaning? If we deviate from the mathematical expectation to the left and to the right by the standard deviation: ![]()
– then the most probable values of the random variable will be “concentrated” on this interval. What we are actually seeing:
However, it so happened that in the analysis of scattering almost always operate with the concept of dispersion. Let's see what it means in relation to games. If in the case of shooters we are talking about the "accuracy" of hits relative to the center of the target, then here the dispersion characterizes two things:
First, it is obvious that as the rates increase, the variance also increases. So, for example, if we increase by 10 times, then the mathematical expectation will increase by 10 times, and the variance will increase by 100 times (as soon as it is a quadratic value). But note that the rules of the game have not changed! Only the rates have changed, roughly speaking, we used to bet 10 rubles, now 100.
The second, more interesting point is that the variance characterizes the style of play. Mentally fix the game rates at some certain level, and see what's what here:
A low variance game is a cautious game. The player tends to choose the most reliable schemes, where he does not lose/win too much at one time. For example, the red/black system in roulette (see Example 4 of the article random variables) .
High variance game. She is often called dispersion game. This is an adventurous or aggressive style of play where the player chooses "adrenaline" schemes. Let's at least remember "Martingale", in which the sums at stake are orders of magnitude greater than the “quiet” game of the previous paragraph.
The situation in poker is indicative: there are so-called tight players who tend to be cautious and "shake" with their game funds (bankroll). Not surprisingly, their bankroll does not fluctuate much (low variance). Conversely, if a player has high variance, then it is the aggressor. He often takes risks, makes large bets and can both break a huge bank and go to pieces.
The same thing happens in Forex, and so on - there are a lot of examples.
Moreover, in all cases it does not matter whether the game is for a penny or for thousands of dollars. Every level has its low and high variance players. Well, for the average win, as we remember, "responsible" expected value.
You probably noticed that finding the variance is a long and painstaking process. But mathematics is generous:
Formula for finding the variance
This formula is derived directly from the definition of variance, and we immediately put it into circulation. I will copy the plate with our game from above: 
and the found expectation .
We calculate the variance in the second way. First, let's find the mathematical expectation - the square of the random variable . By definition of mathematical expectation:
In this case:
Thus, according to the formula:
As they say, feel the difference. And in practice, of course, it is better to apply the formula (unless the condition requires otherwise).
We master the technique of solving and designing:
Example 6

Find its mathematical expectation, variance and standard deviation.
This task is found everywhere, and, as a rule, goes without a meaningful meaning.
You can imagine several light bulbs with numbers that light up in a madhouse with certain probabilities :)
Decision: It is convenient to summarize the main calculations in a table. First, we write the initial data in the top two lines. Then we calculate the products, then and finally the sums in the right column: 
Actually, almost everything is ready. In the third line, a ready-made mathematical expectation was drawn: ![]() .
.
The dispersion is calculated by the formula:
And finally, the standard deviation:
- personally, I usually round to 2 decimal places.
All calculations can be carried out on a calculator, and even better - in Excel:
It's hard to go wrong here :)
Answer:
Those who wish can simplify their lives even more and take advantage of my calculator (demo), which not only instantly solves this problem, but also builds thematic graphics (come soon). The program can download in the library– if you have downloaded at least one study material, or receive another way. Thanks for supporting the project!
A couple of tasks for independent solution:
Example 7
Calculate the variance of the random variable of the previous example by definition.
And a similar example:
Example 8
A discrete random variable is given by its own distribution law:

Yes, the values of the random variable can be quite large (example from real work), and here, if possible, use Excel. As, by the way, in Example 7 - it is faster, more reliable and more pleasant.
Solutions and answers at the bottom of the page.
In conclusion of the 2nd part of the lesson, we will analyze one more typical task, one might even say a small rebus:
Example 9
A discrete random variable can take only two values: and , and . The probability, mathematical expectation and variance are known.
Decision: Let's start with an unknown probability. Since a random variable can take only two values, then the sum of the probabilities of the corresponding events:
and since , then .
It remains to find ..., easy to say :) But oh well, it started. By definition of mathematical expectation: ![]() - substitute the known values:
- substitute the known values:
![]() - and nothing more can be squeezed out of this equation, except that you can rewrite it in the usual direction:
- and nothing more can be squeezed out of this equation, except that you can rewrite it in the usual direction: ![]()

or: ![]()
About further actions, I think you can guess. Let's create and solve the system: 
Decimals are, of course, a complete disgrace; multiply both equations by 10: 
and divide by 2: 
That's much better. From the 1st equation we express: ![]() (this is the easier way)- substitute in the 2nd equation:
(this is the easier way)- substitute in the 2nd equation:
![]()
We are building squared and make simplifications: 
We multiply by: 
As a result, quadratic equation, find its discriminant:
- perfect!
and we get two solutions:
1) if ![]() , then
, then ![]() ;
;
2) if ![]() , then .
, then .
The first pair of values satisfies the condition. With a high probability, everything is correct, but, nevertheless, we write down the distribution law: 
and perform a check, namely, find the expectation:
Along with the study of the variation of a trait throughout the entire population as a whole, it is often necessary to trace the quantitative changes in the trait in groups into which the population is divided, as well as between groups. This study of variation is achieved by calculating and analyzing various kinds of variance.
Distinguish between total, intergroup and intragroup dispersion.
Total variance σ 2 measures the variation of a trait over the entire population under the influence of all the factors that caused this variation, .
Intergroup variance (δ) characterizes systematic variation, i.e. differences in the magnitude of the trait under study, arising under the influence of the trait-factor underlying the grouping. It is calculated by the formula: 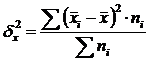 .
.
Within-group variance (σ) reflects random variation, i.e. part of the variation that occurs under the influence of unaccounted for factors and does not depend on the trait-factor underlying the grouping. It is calculated by the formula: 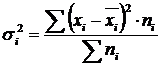 .
.
Average of within-group variances:  .
.
There is a law linking 3 types of dispersion. The total variance is equal to the sum of the average of the intragroup and intergroup variances: ![]() .
.
This ratio is called variance addition rule.
In the analysis, a measure is widely used, which is the proportion of between-group variance in the total variance. It bears the name empirical coefficient of determination (η 2): .
The square root of the empirical coefficient of determination is called empirical correlation ratio (η):
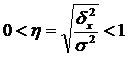 .
.
It characterizes the influence of the attribute underlying the grouping on the variation of the resulting attribute. The empirical correlation ratio varies from 0 to 1.
We will show its practical use in the following example (Table 1).
Example #1. Table 1 - Labor productivity of two groups of workers of one of the workshops of NPO "Cyclone"
Calculate the total and group averages and variances:
The initial data for calculating the average of the intragroup and intergroup dispersion are presented in Table. 2.
table 2
Calculation and δ 2 for two groups of workers.
|
Worker groups | Number of workers, pers. | Average, det./shift. | Dispersion |
| Passed technical training | 5 | 95 | 42,0 |
| Not technically trained | 5 | 81 | 231,2 |
| All workers | 10 | 88 | 185,6 |
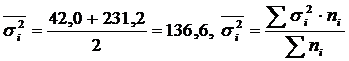 .
.
Intergroup variance
Total variance:
Thus, the empirical correlation ratio: .
Along with the variation of quantitative traits, a variation of qualitative traits can also be observed. This study of variation is achieved by calculating the following types of variances:
The intra-group variance of the share is determined by the formula
where n i– the number of units in separate groups.The proportion of the studied trait in the entire population, which is determined by the formula:
The three types of dispersion are related to each other as follows:
This ratio of variances is called the feature share variance addition theorem.



