Paano i-interpret ang halaga ng chi-square test ni Pearson? Pagsubok ng mga simpleng hypotheses ng chi-square test ni Pearson sa MS EXCEL.
Isaalang-alang ang pamamahagi ng chi-squared. Gamit ang MS EXCEL functionCHI2.DIST() gagawa kami ng mga graph ng distribution function at probability density, ipapaliwanag namin ang aplikasyon ng distribution na ito para sa mga layunin ng mathematical statistics.
Pamamahagi ng Chi-square (X 2, XI2, InglesChi- parisukatpamamahagi) inilapat sa iba't ibang pamamaraan mga istatistika ng matematika:
- kapag nagtatayo;
- sa ;
- sa (kung ang empirical data ay pare-pareho sa aming palagay tungkol sa theoretical distribution function o hindi, eng. Goodness-of-fit)
- sa (ginamit upang matukoy ang kaugnayan sa pagitan ng dalawang kategoryang variable, eng. Chi-square test of association).
Kahulugan: Kung ang x 1 , x 2 , …, x n ay mga independiyenteng random na variable na ipinamamahagi sa N(0;1), kung gayon ang distribusyon ng random variable Y=x 1 2 + x 2 2 +…+ x n 2 ay may pamamahagi X 2 na may n antas ng kalayaan.
Pamamahagi X 2 depende sa isang parameter na tinatawag antas ng kalayaan (df, degreesngkalayaan). Halimbawa, kapag nagtatayo bilang ng antas ng kalayaan ay katumbas ng df=n-1, kung saan ang n ay ang laki mga sample.
Densidad ng pamamahagi X 2
ipinahayag ng formula:
Mga Function na Graph
Pamamahagi X 2 ay may asymmetric na hugis, katumbas ng n, katumbas ng 2n.
SA halimbawa ng file sa sheet Graph binigay mga plot ng density ng pamamahagi probabilidad at integral distribution function.
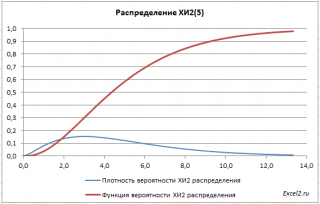
Kapaki-pakinabang na ari-arian mga pamamahagi ng chi2
Hayaang ang x 1 , x 2 , …, x n ay independiyenteng mga random na variable na ibinahagi sa ibabaw normal na batas na may parehong mga parameter μ at σ, at X cf ay isang ibig sabihin ng aritmetika ang mga halagang ito x.
Pagkatapos random na halaga y pantay
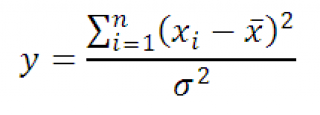
Mayroon itong X 2 -pamahagi na may n-1 na antas ng kalayaan. Gamit ang kahulugan, ang expression sa itaas ay maaaring muling isulat tulad ng sumusunod:
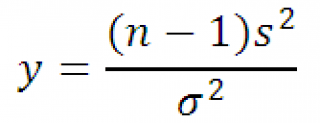
Dahil dito, sampling distribution mga istatistika y, na may sampling mula sa normal na pamamahagi , Mayroon itong X 2 -pamahagi na may n-1 na antas ng kalayaan.
Kakailanganin namin ang ari-arian na ito para sa . kasi pagpapakalat pwede lang positibong numero, ngunit X 2 -pamahagi ginamit upang suriin ito y d.b. >0, gaya ng nakasaad sa kahulugan.
Pamamahagi ng HI2 sa MS EXCEL
Sa MS EXCEL, simula sa bersyon 2010, para sa X 2 -pamamahagi mayroong isang espesyal na function XI2.DIST() , pamagat sa Ingles– CHISQ.DIST(), na nagbibigay-daan sa iyong kalkulahin density ng posibilidad(tingnan ang formula sa itaas) at (probability na ang isang random variable X ay may XI2-pamamahagi, kumukuha ng value na mas mababa sa o katumbas ng x, P(X<= x}).
Tandaan: Dahil pamamahagi ng chi2 ay isang espesyal na kaso, pagkatapos ay ang formula =GAMMA.DIST(x,n/2,2,TRUE) para sa isang positibong integer n nagbabalik ng parehong resulta bilang formula =XI2.DIST(x, n, TRUE) o =1-XI2.DIST.X(x;n) . At ang formula =GAMMA.DIST(x,n/2,2,FALSE) ibinabalik ang parehong resulta ng formula =XI2.DIST(x, n, FALSE), ibig sabihin. density ng posibilidad Mga pamamahagi ng XI2.
Ang CH2.DIST.RT() function ay bumabalik function ng pamamahagi, mas tiyak, ang kanang kamay na posibilidad, i.e. P(X > x). Ito ay malinaw na ang pagkakapantay-pantay
=CHI2.DIST.X(x;n)+ CHI2.DIST(x;n;TRUE)=1
kasi kinakalkula ng unang termino ang posibilidad na P(X > x), at ang pangalawang P(X<= x}.
Bago ang MS EXCEL 2010, ang EXCEL ay mayroon lamang HI2DIST() function, na nagbibigay-daan sa iyong kalkulahin ang right-hand probability, i.e. P(X > x). Ang mga kakayahan ng bagong MS EXCEL 2010 ay nagpapagana ng CHI2.DIST() at CHI2.DIST.RT() sa mga kakayahan ng function na ito. Ang HI2DIST() function ay naiwan sa MS EXCEL 2010 para sa compatibility.
Ang CHI2.DIST() ay ang tanging function na bumabalik probability density ng distribusyon ng chi2(Dapat MALI ang ikatlong argumento). Ang natitirang mga function ay bumalik integral distribution function, ibig sabihin. ang posibilidad na ang isang random na variable ay kukuha ng isang halaga mula sa tinukoy na hanay: P(X<= x}.
Ang mga function sa itaas ng MS EXCEL ay ibinigay sa.
Mga halimbawa
Hanapin ang posibilidad na ang random variable na X ay kukuha ng halagang mas mababa sa o katumbas ng ibinigay x: P(X<= x}. Это можно сделать несколькими функциями:
CHI2.DIST(x, n, TRUE)
=1-CHI2.DIST.RP(x; n)
=1-CHI2DIST(x; n)
Ang function na XI2.DIST.X() ay nagbabalik ng probabilidad na P(X > x), ang tinatawag na right-handed probability, upang mahanap ang P(X<= x}, необходимо вычесть ее результат от 1.
Hanapin natin ang posibilidad na ang random variable na X ay magkakaroon ng halagang mas malaki kaysa sa ibinigay x: P(X > x). Magagawa ito sa maraming mga pag-andar:
1-CHI2.DIST(x, n, TRUE)
=XI2.DIST.RP(x; n)
=CHI2DIST(x, n)
Inverse chi2 distribution function
Ang inverse function ay ginagamit upang makalkula alpha- , ibig sabihin. upang makalkula ang mga halaga x para sa isang ibinigay na posibilidad alpha, at X dapat matugunan ang ekspresyong P(X<= x}=alpha.
Ang CH2.INV() function ay ginagamit upang kalkulahin mga agwat ng kumpiyansa ng normal na pagkakaiba-iba ng pamamahagi.
Ang XI2.INV.RT() function ay ginagamit upang kalkulahin ang , ibig sabihin. kung ang isang antas ng kahalagahan ay tinukoy bilang isang argument ng function, halimbawa, 0.05, ibabalik ng function ang ganoong halaga ng random variable na x, kung saan ang P(X>x)=0.05. Bilang paghahambing: ang function na XI2.INV() ay magbabalik ng ganoong halaga ng random variable x, kung saan ang P(X<=x}=0,05.
Sa MS EXCEL 2007 at mas maaga, sa halip na XI2.INV.PX(), ginamit ang function na XI2OBR().
Ang mga function sa itaas ay maaaring palitan, bilang ang mga sumusunod na formula ay nagbabalik ng parehong resulta:
=CHI.OBR(alpha,n)
=XI2.INV.RT(1-alpha;n)
\u003d XI2OBR (1-alpha; n)
Ang ilang mga halimbawa ng pagkalkula ay ibinigay sa halimbawa ng file sa Functions sheet.
MS EXCEL functions gamit ang chi2 distribution
Nasa ibaba ang mga sulat sa pagitan ng mga pangalan ng function na Russian at English:
HI2.DIST.PH() - eng. pangalan CHISQ.DIST.RT, ibig sabihin. CHI-SQuared DISTRIBUtion Right Tail, ang right-tailed Chi-square(d) distribution
XI2.OBR () - Ingles. pangalan CHISQ.INV, ibig sabihin. CHI-Squared distribution INVerse
HI2.PH.OBR() - English. pangalan CHISQ.INV.RT, ibig sabihin. CHI-SQuared distribution INVerse Right Tail
HI2DIST() - eng. pangalan CHIDIST, function na katumbas ng CHISQ.DIST.RT
HI2OBR() - eng. ang pangalang CHIINV, i.e. CHI-Squared distribution INVerse
Pagtatantya ng mga parameter ng pamamahagi
kasi kadalasan pamamahagi ng chi2 ginagamit para sa mga layunin ng matematikal na istatistika (pagkalkula agwat ng kumpiyansa, pagsubok ng hypothesis, atbp.) at halos hindi kailanman para sa pagbuo ng mga modelo ng mga tunay na halaga, kung gayon para sa pamamahagi na ito ang talakayan ng pagtatantya ng mga parameter ng pamamahagi ay hindi isinasagawa dito.
Pagtataya ng XI2 distribution sa pamamagitan ng normal na distribution
Sa bilang ng mga antas ng kalayaan n>30 pamamahagi X 2 mahusay na tinatayang normal na pamamahagi co karaniwanμ=n at pagpapakalat σ=2*n (tingnan halimbawa ng file sheet Approximation).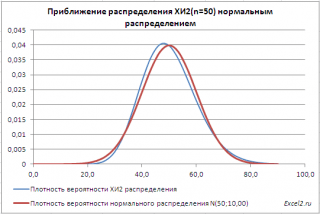
Chi-square na pagsubok.
Ang chi-square test, hindi tulad ng z test, ay ginagamit upang ihambing ang anumang bilang ng mga pangkat.
Paunang data: contingency table.
Ang isang halimbawa ng isang talahanayan ng contingency na may pinakamababang dimensyon na 2*2 ay ibinigay sa ibaba. A, B, C, D - ang tinatawag na real frequency.
| Tampok 1 | Tampok 2 | Kabuuan | |
| Pangkat 1 | A | B | A+B |
| Pangkat 2 | C | D | C+D |
| Kabuuan | A+C | B+D | A+B+C+D |
Ang pagkalkula ng criterion ay batay sa isang paghahambing ng mga tunay na frequency at inaasahang frequency, na kung saan ay kinakalkula sa pag-aakalang walang magkaparehong impluwensya ng mga inihambing na tampok sa bawat isa. Kaya, kung ang aktwal at inaasahang mga frequency ay sapat na malapit sa isa't isa, kung gayon walang impluwensya at, samakatuwid, ang mga palatandaan ay ipapamahagi nang humigit-kumulang pantay sa mga grupo.
Ang paunang data para sa aplikasyon ng pamamaraang ito ay dapat na maipasok sa isang talahanayan ng contingency, ang mga haligi at hilera kung saan ay nagpapahiwatig ng mga pagpipilian para sa mga halaga ng mga pinag-aralan na katangian. Ang mga numero sa talahanayang ito ay tatawaging tunay o pang-eksperimentong mga frequency. Susunod, kinakailangang kalkulahin ang inaasahang mga frequency batay sa pag-aakalang ang mga inihambing na grupo ay ganap na pantay-pantay sa mga tuntunin ng pamamahagi ng mga tampok. Sa kasong ito, ang mga proporsyon para sa kabuuang row o column na "kabuuan" ay dapat na mapanatili sa anumang row at column. Batay dito, ang mga inaasahang frequency ay tinutukoy (tingnan ang halimbawa).
Pagkatapos, ang halaga ng criterion ay kinakalkula bilang kabuuan sa lahat ng mga cell ng contingency table ng ratio ng square ng pagkakaiba sa pagitan ng aktwal na dalas at ang inaasahang dalas sa inaasahang dalas:
nasaan ang tunay na dalas sa cell; ay ang inaasahang dalas sa cell.
 , saan N = A + B + C + D.
, saan N = A + B + C + D.
Kapag kinakalkula ayon sa pangunahing formula para sa talahanayan 2 * 2 ( para lang sa table na ito ), kinakailangan ding ilapat ang pagwawasto ng Yates para sa pagpapatuloy:
 .
.
Ang kritikal na halaga ng criterion ay tinutukoy mula sa talahanayan (tingnan ang Appendix), na isinasaalang-alang ang bilang ng mga antas ng kalayaan at ang antas ng kahalagahan. Ang antas ng kahalagahan ay kinuha bilang pamantayan: 0.05; 0.01 o 0.001. Ang bilang ng mga antas ng kalayaan ay tinukoy bilang ang produkto ng bilang ng mga hilera at column ng talahanayan ng contingency, bawat isa ay binabawasan ng isa:
![]() ,
,
saan r- ang bilang ng mga linya (ang bilang ng mga gradasyon ng isang tampok), mula sa– bilang ng mga column (bilang ng gradations ng isa pang feature). Ito kritikal na halaga maaaring matukoy sa isang Microsoft Excel spreadsheet gamit ang function na =x2inv( a, f), kung saan sa halip na isang kailangan mong ipasok ang antas ng kahalagahan, at sa halip na f ay ang bilang ng mga antas ng kalayaan.
Kung ang halaga ng chi-square test ay mas malaki kaysa sa kritikal na halaga, kung gayon ang hypothesis ng pagsasarili ng mga tampok ay tinanggihan at maaari silang ituring na nakasalalay sa napiling antas ng kahalagahan.
Ang pamamaraang ito ay may limitasyon sa kakayahang magamit: ang inaasahang mga frequency ay dapat na 5 o higit pa (para sa isang 2*2 na talahanayan). Para sa isang arbitrary na talahanayan, ang paghihigpit na ito ay hindi gaanong mahigpit: lahat ng inaasahang frequency ay dapat 1 o higit pa, at ang proporsyon ng mga cell na may inaasahang frequency na mas mababa sa 5 ay hindi dapat lumampas sa 20%.
Mula sa contingency table ng mataas na dimensyon, maaari mong "ihiwalay" ang mga talahanayan ng mas mababang dimensyon at kalkulahin ang halaga ng criterion c 2 para sa kanila. Ang mga ito ay talagang maraming paghahambing, katulad ng mga inilarawan para sa pagsusulit ng Estudyante. Sa kasong ito, kinakailangan ding maglapat ng pagwawasto para sa maraming paghahambing depende sa kanilang bilang.
Upang subukan ang isang hypothesis gamit ang criterion c 2 sa mga spreadsheet ng Microsoft Excel, maaari mong ilapat ang sumusunod na function:
CHI2TEST(actual_interval; expected_interval).
Dito, ang actual_interval ay ang orihinal na talahanayan ng contingency na may mga tunay na frequency (tanging ang mga cell na may mga frequency mismo ang ipinahiwatig nang walang mga header at "kabuuan"); expected_interval ay isang hanay ng mga inaasahang frequency. Samakatuwid, ang inaasahang mga frequency ay dapat kalkulahin nang nakapag-iisa.
Halimbawa:
Nagkaroon ng pagsiklab ng isang nakakahawang sakit sa isang partikular na lungsod. May isang pagpapalagay na ang pinagmulan ng impeksyon ay inuming tubig. Napagpasyahan na subukan ang palagay na ito sa tulong ng isang sample na survey ng populasyon ng lunsod, ayon sa kung saan kinakailangan upang maitatag kung ang dami ng tubig na lasing ay nakakaapekto sa bilang ng mga kaso.
Ang paunang data ay ibinibigay sa sumusunod na talahanayan:
Kalkulahin natin ang mga inaasahang frequency. Ang proporsyon para sa lahat ay dapat na mapanatili sa loob ng mesa. Samakatuwid, kinakalkula namin, halimbawa, kung anong proporsyon ang kabuuan para sa mga linya sa kabuuang bilang, nakakakuha kami ng isang koepisyent para sa bawat linya. Ang parehong bahagi ay dapat nasa bawat cell ng kaukulang linya, samakatuwid, upang kalkulahin ang inaasahang dalas sa cell, pinarami namin ang koepisyent sa kabuuan sa kaukulang hanay.

Ang bilang ng mga antas ng kalayaan ay (3-1)*(2-1)=2. Kritikal na halaga ng criterion ![]() .
.
Ang pang-eksperimentong halaga ay mas malaki kaysa sa kritikal na halaga (61.5>13.816), ibig sabihin. ang hypothesis na walang epekto ng dami ng tubig na nainom sa morbidity ay tinanggihan na may error probability na mas mababa sa 0.001. Kaya naman, maaaring pagtalunan na ang tubig ang naging pinagmulan ng sakit.
Pareho sa mga inilarawang pamantayan ay may mga limitasyon na karaniwang hindi natutugunan kung ang bilang ng mga obserbasyon ay maliit o ang mga indibidwal na gradasyon ng mga tampok ay bihira. Sa kasong ito, gamitin Eksaktong pagsubok ni Fisher . Ito ay batay sa enumeration ng lahat ng posibleng opsyon para sa pagpuno sa contingency table para sa isang naibigay na bilang ng mga grupo. Samakatuwid, ang manu-manong pagkalkula nito ay medyo kumplikado. Upang kalkulahin ito, maaari mong gamitin ang mga pakete ng software sa istatistika.
Ang z-test ay kahalintulad sa pagsusulit ng Estudyante, ngunit ginagamit upang ihambing ang mga katangian ng husay. Ang pang-eksperimentong halaga ng criterion ay kinakalkula bilang ratio ng pagkakaiba sa mga bahagi sa karaniwang error magbahagi ng mga pagkakaiba.
Ang kritikal na halaga ng z criterion ay katumbas ng mga kaukulang punto ng normalized na normal na distribution: ![]() ,
, ![]() ,
, ![]() .
.
Ang chi-square test ay ginagamit upang ihambing ang anumang bilang ng mga pangkat ayon sa mga halaga ng mga katangian ng husay. Ang paunang data ay dapat ipakita sa anyo ng isang talahanayan ng contingency. Ang pang-eksperimentong halaga ng criterion ay kinakalkula bilang kabuuan ng lahat ng mga cell ng contingency table ng ratio ng parisukat ng pagkakaiba sa pagitan ng aktwal na dalas at inaasahang dalas sa inaasahang dalas. Ang mga inaasahang frequency ay kinakalkula sa ilalim ng pagpapalagay na ang mga pinaghahambing na feature ay pantay sa lahat ng grupo. Ang mga kritikal na halaga ay tinutukoy mula sa mga talahanayan ng pamamahagi ng chi-square.
PANITIKAN.
Glantz S. - Kabanata 5.
Rebrova O.Yu. - Kabanata 10.11.
Lakin G.F. - mula sa. 120-123
Mga tanong para sa pagsusuri sa sarili ng mga mag-aaral.
1. Sa anong mga kaso maaaring ilapat ang z criterion?
2. Ano ang batayan ng pagkalkula ng pang-eksperimentong halaga ng z criterion?
3. Paano mahahanap ang kritikal na halaga ng z criterion?
4. Sa anong mga kaso maaaring ilapat ang criterion c 2?
5. Ano ang batayan para sa pagkalkula ng pang-eksperimentong halaga ng criterion c 2 ?
6. Paano mahahanap ang kritikal na halaga ng criterion c 2 ?
7. Ano pa ang maaaring gamitin upang ihambing ang mga katangian ng husay, kung ang pamantayang z at c 2 ay hindi mailalapat dahil sa mga limitasyon?
Mga gawain.
Ang χ 2 criterion ni Pearson ay nonparametric na pamamaraan, na nagbibigay-daan sa iyo upang masuri ang kahalagahan ng mga pagkakaiba sa pagitan ng aktwal (ibinunyag bilang resulta ng pag-aaral) na bilang ng mga kinalabasan o mga katangian ng husay ng sample na nabibilang sa bawat kategorya, at ang teoretikal na bilang na maaaring asahan sa mga pinag-aralan na grupo kung totoo ang null hypothesis. Sa mas simpleng mga termino, ang pamamaraan ay nagpapahintulot sa isa na tantyahin istatistikal na kahalagahan mga pagkakaiba sa pagitan ng dalawa o higit pang mga kamag-anak na tagapagpahiwatig (mga frequency, pagbabahagi).
1. Kasaysayan ng pagbuo ng χ 2 criterion
Ang chi-square test para sa pagsusuri ng mga contingency table ay binuo at iminungkahi noong 1900 ng isang English mathematician, statistician, biologist at philosopher, ang founder ng mathematical statistics at isa sa mga founder ng biometrics. Karl Pearson(1857-1936).
2. Para saan ginagamit ang χ2 criterion ng Pearson?
Ang chi-square test ay maaaring ilapat sa pagsusuri mga talahanayan ng contingency naglalaman ng impormasyon tungkol sa dalas ng mga kinalabasan depende sa pagkakaroon ng panganib na kadahilanan. Halimbawa, four-field contingency table tulad ng sumusunod:
| Ang Exodo ay (1) | Walang labasan (0) | Kabuuan | |
| May panganib na kadahilanan (1) | A | B | A+B |
| Walang panganib na kadahilanan (0) | C | D | C+D |
| Kabuuan | A+C | B+D | A+B+C+D |
Paano punan ang naturang contingency table? Isaalang-alang natin ang isang maliit na halimbawa.
Ang isang pag-aaral ay isinasagawa sa epekto ng paninigarilyo sa panganib ng pagkakaroon ng arterial hypertension. Para dito, dalawang grupo ng mga paksa ang napili - ang una ay may kasamang 70 tao na naninigarilyo ng hindi bababa sa 1 pakete ng sigarilyo araw-araw, ang pangalawa - 80 hindi naninigarilyo sa parehong edad. Sa unang grupo, 40 katao ang may mataas na presyon ng dugo. Sa pangalawa - ang arterial hypertension ay sinusunod sa 32 katao. Alinsunod dito, ang normal na presyon ng dugo sa grupo ng mga naninigarilyo ay nasa 30 tao (70 - 40 = 30) at sa grupo ng mga hindi naninigarilyo - sa 48 (80 - 32 = 48).
Pinupuno namin ang talahanayan ng contingency na may apat na larangan ng paunang data:
Sa resultang talahanayan ng contingency, ang bawat linya ay tumutugma sa isang partikular na grupo ng mga paksa. Mga Column - ipakita ang bilang ng mga taong may arterial hypertension o may normal na presyon ng dugo.
Ang hamon para sa mananaliksik ay: mayroon bang mga makabuluhang pagkakaiba sa istatistika sa pagitan ng dalas ng mga taong may presyon ng dugo sa mga naninigarilyo at hindi naninigarilyo? Masasagot mo ang tanong na ito sa pamamagitan ng pagkalkula ng chi-square test ng Pearson at paghahambing ng resultang halaga sa kritikal na isa.
3. Mga kundisyon at paghihigpit sa paggamit ng chi-square test ni Pearson
- Ang mga maihahambing na tagapagpahiwatig ay dapat masukat sa nominal na sukat(halimbawa, ang kasarian ng pasyente - lalaki o babae) o sa ordinal(halimbawa, ang antas ng arterial hypertension, kumukuha ng mga halaga mula 0 hanggang 3).
- Ang pamamaraang ito nagbibigay-daan sa pagsusuri hindi lamang sa mga talahanayan ng apat na larangan, kapag ang salik at ang kinalabasan ay binary variable, iyon ay, mayroon lamang silang dalawang posibleng halaga (halimbawa, lalaki o babae, ang pagkakaroon o kawalan ng isang tiyak na sakit. sa Kasaysayan ...). Ang chi-square test ng Pearson ay maaari ding gamitin sa kaso ng pagsusuri ng mga multi-field na talahanayan, kapag ang kadahilanan at (o) kinalabasan ay tumagal ng tatlo o higit pang mga halaga.
- Ang mga tugmang pangkat ay dapat na independyente, ibig sabihin, ang chi-square na pagsubok ay hindi dapat gamitin kapag naghahambing ng bago-pagkatapos na mga obserbasyon. Pagsusulit sa McNemar(kapag naghahambing ng dalawang magkaugnay na populasyon) o kinakalkula Q-test Cochran(sa kaso ng paghahambing ng tatlo o higit pang mga grupo).
- Kapag sinusuri ang mga talahanayan ng apat na larangan inaasahang halaga sa bawat isa sa mga cell ay dapat na hindi bababa sa 10. Kung sakaling sa hindi bababa sa isang cell ang inaasahang phenomenon ay tumatagal ng halaga mula 5 hanggang 9, ang chi-square test ay dapat kalkulahin sa pagwawasto ni Yates. Kung sa hindi bababa sa isang cell ang inaasahang phenomenon ay mas mababa sa 5, dapat gamitin ang pagsusuri Eksaktong pagsubok ni Fisher.
- Sa kaso ng pagsusuri ng mga multi-field na talahanayan, ang inaasahang bilang ng mga obserbasyon ay hindi dapat kumuha ng mga halaga na mas mababa sa 5 sa higit sa 20% ng mga cell.
4. Paano makalkula ang chi-square test ni Pearson?
Upang kalkulahin ang chi-square test, kailangan mong:

Naaangkop ang algorithm na ito para sa parehong apat na field at multi-field na talahanayan.
5. Paano i-interpret ang halaga ng chi-square test ni Pearson?
Kung sakaling ang nakuha na halaga ng criterion χ 2 ay mas malaki kaysa sa kritikal, napagpasyahan namin na mayroong istatistikal na kaugnayan sa pagitan ng pinag-aralan na kadahilanan ng panganib at ang kinalabasan sa naaangkop na antas ng kahalagahan.
6. Isang halimbawa ng pagkalkula ng Pearson chi-square test
Alamin natin ang istatistikal na kahalagahan ng impluwensya ng kadahilanan ng paninigarilyo sa saklaw ng arterial hypertension ayon sa talahanayan sa itaas:
- Kinakalkula namin ang mga inaasahang halaga para sa bawat cell:
- Hanapin ang halaga ng chi-square test ni Pearson:
χ 2 \u003d (40-33.6) 2 / 33.6 + (30-36.4) 2 / 36.4 + (32-38.4) 2 / 38.4 + (48-41.6) 2 / 41.6 \u003d 4.396.
- Ang bilang ng mga antas ng kalayaan f = (2-1)*(2-1) = 1. Nakikita namin ang kritikal na halaga ng chi-square test ni Pearson mula sa talahanayan, na nasa antas ng kahalagahan na p=0.05 at ang bilang ng grado ng kalayaan 1 ay 3.841.
- Inihambing namin ang nakuha na halaga ng chi-square na pagsubok sa kritikal na isa: 4.396 > 3.841, samakatuwid, ang pag-asa sa saklaw ng arterial hypertension sa pagkakaroon ng paninigarilyo ay makabuluhan sa istatistika. Ang antas ng kahalagahan ng relasyong ito ay tumutugma sa p<0.05.
). Ang tiyak na pormulasyon ng hypothesis na sinusuri ay mag-iiba sa bawat kaso.
Sa post na ito, ilalarawan ko kung paano gumagana ang pagsubok na \(\chi^2\) gamit ang isang (hypothetical) na halimbawa mula sa immunology. Isipin na nagsagawa kami ng isang eksperimento upang matukoy ang pagiging epektibo ng pagsugpo sa pagbuo ng isang sakit na microbial kapag ang naaangkop na mga antibodies ay ipinakilala sa katawan. Sa kabuuan, 111 mice ang kasangkot sa eksperimento, na hinati namin sa dalawang grupo, kabilang ang 57 at 54 na hayop, ayon sa pagkakabanggit. Ang unang pangkat ng mga daga ay na-injected ng pathogenic bacteria, na sinundan ng pagpapakilala ng blood serum na naglalaman ng mga antibodies laban sa mga bacteria na ito. Ang mga hayop mula sa pangalawang grupo ay nagsilbing mga kontrol - nakatanggap lamang sila ng mga bacterial injection. Matapos ang ilang oras ng pagpapapisa ng itlog, lumabas na 38 mice ang namatay, at 73 ang nakaligtas. Sa mga patay, 13 ang kabilang sa unang grupo, at 25 ang kabilang sa pangalawa (kontrol). Ang null hypothesis na nasubok sa eksperimentong ito ay maaaring mabalangkas tulad ng sumusunod: ang pangangasiwa ng serum na may mga antibodies ay walang epekto sa kaligtasan ng mga daga. Sa madaling salita, pinagtatalunan namin na ang mga naobserbahang pagkakaiba sa kaligtasan ng mga daga (77.2% sa unang pangkat kumpara sa 53.7% sa pangalawang pangkat) ay ganap na random at hindi nauugnay sa pagkilos ng mga antibodies.
Ang data na nakuha sa eksperimento ay maaaring ipakita sa anyo ng isang talahanayan:
Kabuuan |
|||
Bakterya + suwero |
|||
Bakterya lamang |
|||
Kabuuan |
Ang mga table na tulad nito ay tinatawag na contingency table. Sa halimbawang ito, ang talahanayan ay may sukat na 2x2: mayroong dalawang klase ng mga bagay ("Bacteria + serum" at "Bacteria lamang"), na sinusuri ayon sa dalawang pamantayan ("Patay" at "Nakaligtas"). Ito ang pinakasimpleng kaso ng isang contingency table: siyempre, parehong ang bilang ng mga klase sa ilalim ng pag-aaral at ang bilang ng mga tampok ay maaaring mas malaki.
Upang subukan ang null hypothesis na nabuo sa itaas, kailangan nating malaman kung ano ang magiging sitwasyon kung ang mga antibodies ay talagang walang epekto sa kaligtasan ng mga daga. Sa madaling salita, kailangan mong kalkulahin inaasahang frequency para sa kaukulang mga cell ng contingency table. Paano ito gagawin? Isang kabuuang 38 na daga ang namatay sa eksperimento, na 34.2% ng kabuuang bilang ng mga hayop na kasangkot. Kung ang pagpapakilala ng mga antibodies ay hindi nakakaapekto sa kaligtasan ng mga daga, ang parehong porsyento ng dami ng namamatay ay dapat na sundin sa parehong mga eksperimentong grupo, lalo na 34.2%. Ang pagkalkula kung magkano ang 34.2% ng 57 at 54, makakakuha tayo ng 19.5 at 18.5. Ito ang mga inaasahang dami ng namamatay sa aming mga pang-eksperimentong grupo. Ang inaasahang mga rate ng kaligtasan ay kinakalkula sa katulad na paraan: dahil may kabuuang 73 na daga ang nakaligtas, o 65.8% ng kanilang kabuuang bilang, ang inaasahang mga rate ng kaligtasan ay 37.5 at 35.5. Gumawa tayo ng bagong contingency table, ngayon na may inaasahang frequency:
patay |
Mga nakaligtas |
Kabuuan |
|
Bakterya + suwero |
|||
Bakterya lamang |
|||
Kabuuan |
Tulad ng nakikita mo, ang mga inaasahang frequency ay medyo naiiba mula sa mga naobserbahan, i.e. Ang pangangasiwa ng mga antibodies ay tila may epekto sa kaligtasan ng mga daga na nahawaan ng pathogen. Masusukat natin ang impression na ito gamit ang goodness-of-fit test ni Pearson \(\chi^2\):
\[\chi^2 = \sum_()\frac((f_o - f_e)^2)(f_e),\]
kung saan ang \(f_o\) at \(f_e\) ay ang naobserbahan at inaasahang frequency, ayon sa pagkakabanggit. Ang pagsusuma ay ginagawa sa lahat ng mga cell ng talahanayan. Kaya, para sa halimbawang isinasaalang-alang, mayroon kami
\[\chi^2 = (13 – 19.5)^2/19.5 + (44 – 37.5)^2/37.5 + (25 – 18.5)^2/18.5 + (29 – 35.5)^2/35.5 = \]
Ang \(\chi^2\) ba ay sapat na malaki upang tanggihan ang null hypothesis? Upang masagot ang tanong na ito, kinakailangan upang mahanap ang kaukulang kritikal na halaga ng criterion. Ang bilang ng mga antas ng kalayaan para sa \(\chi^2\) ay kinakalkula bilang \(df = (R - 1)(C - 1)\), kung saan ang \(R\) at \(C\) ay ang numero ng mga row at column sa table conjugacy. Sa aming kaso \(df = (2 -1)(2 - 1) = 1\). Alam ang bilang ng mga antas ng kalayaan, madali na nating malalaman ang kritikal na halaga \(\chi^2\) gamit ang karaniwang R-function qchisq() :
Kaya, para sa isang antas ng kalayaan, ang halaga ng criterion \(\chi^2\) ay lumampas sa 3.841 lamang sa 5% ng mga kaso. Ang halaga na nakuha namin, 6.79, ay makabuluhang lumampas sa kritikal na halaga na ito, na nagbibigay sa amin ng karapatang tanggihan ang null hypothesis tungkol sa kawalan ng isang relasyon sa pagitan ng pangangasiwa ng mga antibodies at ang kaligtasan ng mga nahawaang daga. Ang pagtanggi sa hypothesis na ito, nanganganib tayong magkamali sa posibilidad na mas mababa sa 5%.
Dapat tandaan na ang formula sa itaas para sa criterion \(\chi^2\) ay nagbibigay ng medyo overestimated na mga halaga kapag nagtatrabaho sa mga contingency table na may sukat na 2x2. Ang dahilan ay ang distribusyon ng \(\chi^2\) criterion mismo ay tuloy-tuloy, habang ang mga frequency ng binary features ("namatay" / "nakaligtas") ay discrete ayon sa kahulugan. Sa pagsasaalang-alang na ito, kapag kinakalkula ang pamantayan, kaugalian na ipakilala ang tinatawag na. pagwawasto ng pagpapatuloy, o Susog ni Yates :
\[\chi^2_Y = \sum_()\frac((|f_o - f_e| - 0.5)^2)(f_e).\]
"s Chi-squared test with Yates" continuity correction data : mice X-squared = 5.7923 , df = 1 , p-value = 0.0161
Gaya ng nakikita mo, awtomatikong inilalapat ng R ang pagwawasto ng Yates para sa pagpapatuloy ( Pearson's Chi-squared test kasama ang continuity correction ni Yates). Ang halagang \(\chi^2\) na kinakalkula ng programa ay 5.79213. Maaari naming tanggihan ang null hypothesis ng walang epekto ng antibody sa panganib na magkamali sa posibilidad na higit sa 1% lamang (p-value = 0.0161).
Ministri ng Edukasyon at Agham ng Russian Federation
Federal Agency for Education ng lungsod ng Irkutsk
Baikal State University of Economics and Law
Kagawaran ng Informatics at Cybernetics
Chi-squared distribution at ang aplikasyon nito
Kolmykova Anna Andreevna
2nd year student
pangkat IS-09-1
Irkutsk 2010
Panimula
1. Chi-square distribution
Apendise
Konklusyon
Bibliograpiya
Panimula
Paano ginagamit ang mga diskarte, ideya at resulta ng probability theory sa ating buhay?
Ang base ay isang probabilistikong modelo ng isang tunay na kababalaghan o proseso, i.e. isang mathematical model kung saan ang mga layunin na relasyon ay ipinahayag sa mga tuntunin ng probability theory. Ang mga probabilidad ay pangunahing ginagamit upang ilarawan ang mga kawalan ng katiyakan na dapat isaalang-alang kapag gumagawa ng mga desisyon. Ito ay tumutukoy sa parehong hindi kanais-nais na mga pagkakataon (mga panganib) at mga kaakit-akit ("masuwerteng pagkakataon"). Minsan ang randomness ay sadyang ipinakilala sa sitwasyon, halimbawa, kapag gumuhit ng maraming, random na pagpili ng mga yunit para sa kontrol, pagsasagawa ng mga lottery o mga survey ng consumer.
Ang teorya ng probabilidad ay nagpapahintulot sa isa na kalkulahin ang iba pang mga probabilidad na interesado sa mananaliksik.
Ang isang probabilistikong modelo ng isang phenomenon o proseso ay ang pundasyon ng matematikal na istatistika. Dalawang magkatulad na serye ng mga konsepto ang ginagamit - ang mga nauugnay sa teorya (isang probabilistikong modelo) at ang mga nauugnay sa pagsasanay (isang sample ng mga resulta ng pagmamasid). Halimbawa, ang teoretikal na posibilidad ay tumutugma sa dalas na natagpuan mula sa sample. Ang mathematical expectation (theoretical series) ay tumutugma sa sample na arithmetic mean (practical series). Bilang isang tuntunin, ang mga sample na katangian ay mga pagtatantya ng mga teoretikal. Kasabay nito, ang mga dami na nauugnay sa teoretikal na serye "ay nasa isip ng mga mananaliksik", ay tumutukoy sa mundo ng mga ideya (ayon sa sinaunang pilosopong Griyego na si Plato), ay hindi magagamit para sa direktang pagsukat. Ang mga mananaliksik ay may pumipili lamang na data, sa tulong kung saan sinusubukan nilang itatag ang mga katangian ng isang teoretikal na probabilistikong modelo na interesado sa kanila.
Bakit kailangan natin ng probabilistikong modelo? Ang katotohanan ay sa tulong lamang nito posible na ilipat ang mga katangian na itinatag ng mga resulta ng pagsusuri ng isang partikular na sample sa iba pang mga sample, pati na rin sa buong tinatawag na pangkalahatang populasyon. Ang terminong "populasyon" ay ginagamit upang tumukoy sa isang malaki ngunit may hangganang populasyon ng mga yunit na pinag-aaralan. Halimbawa, tungkol sa kabuuan ng lahat ng residente ng Russia o ang kabuuan ng lahat ng mga mamimili ng instant na kape sa Moscow. Ang layunin ng marketing o sociological survey ay ilipat ang mga pahayag na natanggap mula sa sample ng daan-daan o libu-libong tao sa pangkalahatang populasyon ng ilang milyong tao. Sa kontrol sa kalidad, isang batch ng mga produkto ang kumikilos bilang isang pangkalahatang populasyon.
Upang ilipat ang mga hinuha mula sa isang sample patungo sa isang mas malaking populasyon, kailangan ang ilang mga pagpapalagay tungkol sa kaugnayan ng mga katangian ng sample sa mga katangian ng mas malaking populasyon na ito. Ang mga pagpapalagay na ito ay batay sa isang naaangkop na probabilistikong modelo.
Siyempre, posibleng iproseso ang sample na data nang hindi gumagamit ng isa o ibang probabilistikong modelo. Halimbawa, maaari mong kalkulahin ang sample na arithmetic mean, kalkulahin ang dalas ng katuparan ng ilang mga kundisyon, atbp. Gayunpaman, ang mga resulta ng mga kalkulasyon ay malalapat lamang sa isang partikular na sample; ang paglilipat ng mga konklusyon na nakuha sa kanilang tulong sa anumang iba pang hanay ay hindi tama. Ang aktibidad na ito ay minsang tinutukoy bilang "data analysis". Kung ikukumpara sa probabilistic-statistical na pamamaraan, ang data analysis ay may limitadong cognitive value.
Kaya, ang paggamit ng mga probabilistic na modelo batay sa pagtatantya at pagsubok ng mga hypotheses sa tulong ng mga sample na katangian ay ang kakanyahan ng probabilistic-statistical na mga pamamaraan sa paggawa ng desisyon.
Chi-squared distribution
Ang normal na distribusyon ay tumutukoy sa tatlong distribusyon na ngayon ay karaniwang ginagamit sa pagpoproseso ng istatistikal na data. Ito ang mga distribusyon ng Pearson ("chi - square"), Student at Fisher.
Tutuon tayo sa pamamahagi
("chi - parisukat"). Ang pamamahagi na ito ay unang pinag-aralan ng astronomer na si F. Helmert noong 1876. Kaugnay ng teorya ng Gaussian ng mga pagkakamali, pinag-aralan niya ang mga kabuuan ng mga parisukat ng n independiyenteng pamantayan na karaniwang ipinamamahagi ng mga random na variable. Kalaunan ay pinangalanan ni Karl Pearson ang distribution function na "chi-square". At ngayon ang pamamahagi ay nagdala ng kanyang pangalan.Dahil sa malapit na koneksyon nito sa normal na distribusyon, ang pamamahagi ng χ2 ay gumaganap ng isang mahalagang papel sa teorya ng posibilidad at mga istatistika ng matematika. Ang pamamahagi ng χ2, at maraming iba pang mga distribusyon na tinukoy ng distribusyon ng χ2 (hal. t-distribusyon ng Mag-aaral), naglalarawan ng mga sample na pamamahagi ng iba't ibang mga function mula sa mga obserbasyon na karaniwang ipinamamahagi at ginagamit upang bumuo ng mga pagitan ng kumpiyansa at mga istatistikal na pagsusulit.
Pamamahagi ng Pearson
(chi - squared) – distribusyon ng isang random na variable, kung saan ang X1, X2,…, Xn ay normal na independiyenteng random variable, at ang matematikal na inaasahan ng bawat isa sa kanila ay zero, at ang standard deviation ay isa.Kabuuan ng mga parisukat
itinalaga ng batas
("chi - parisukat").Sa kasong ito, ang bilang ng mga termino, i.e. n, ay tinatawag na "bilang ng mga antas ng kalayaan" ng chi-squared distribution. Habang tumataas ang bilang ng mga antas ng kalayaan, dahan-dahang lumalapit sa normal ang pamamahagi.
Ang density ng pamamahagi na ito

Kaya, ang pamamahagi χ2 ay nakasalalay sa isang parameter n - ang bilang ng mga antas ng kalayaan.
Ang distribution function χ2 ay may anyo:

kung χ2≥0. (2.7.)
Ang Figure 1 ay nagpapakita ng isang graph ng probability density at χ2 distribution function para sa iba't ibang antas ng kalayaan.

Larawan 1 Ang dependence ng probability density φ (x) sa distribution χ2 (chi - squared) para sa ibang bilang ng degree ng kalayaan.
Mga sandali ng pamamahagi ng "chi-square":
Ginagamit ang chi-squared distribution sa variance estimation (gamit ang confidence interval), sa pagsubok ng mga hypotheses ng kasunduan, homogeneity, independence, pangunahin para sa qualitative (nakategorya) na variable na kumukuha ng limitadong bilang ng mga value, at sa maraming iba pang gawain ng statistical data pagsusuri.
2. "Chi-square" sa mga problema sa pagtatasa ng istatistikal na data
Ang mga pamamaraan ng istatistika ng pagsusuri ng data ay ginagamit sa halos lahat ng mga lugar ng aktibidad ng tao. Ginagamit ang mga ito sa tuwing kinakailangan upang makuha at patunayan ang anumang mga paghuhusga tungkol sa isang grupo (mga bagay o paksa) na may ilang panloob na heterogeneity.
Ang modernong yugto ng pag-unlad ng mga pamamaraan ng istatistika ay mabibilang mula 1900, nang itinatag ng Englishman na si K. Pearson ang journal na "Biometrika". Unang ikatlong bahagi ng ika-20 siglo naipasa sa ilalim ng tanda ng parametric statistics. Ang mga pamamaraan batay sa pagsusuri ng data mula sa parametric na pamilya ng mga distribusyon na inilarawan ng mga kurba ng pamilya Pearson ay pinag-aralan. Ang pinakasikat ay ang normal na pamamahagi. Ang pamantayan ng Pearson, Student, at Fisher ay ginamit upang subukan ang mga hypotheses. Ang maximum na posibilidad na paraan, pagsusuri ng pagkakaiba ay iminungkahi, at ang mga pangunahing ideya para sa pagpaplano ng eksperimento ay binuo.
Ang pamamahagi ng chi-square ay isa sa pinakamalawak na ginagamit sa mga istatistika para sa pagsubok ng mga istatistikal na hypotheses. Sa batayan ng pamamahagi ng "chi-square", isa sa pinakamakapangyarihang goodness-of-fit na mga pagsubok, ang "chi-square" na pagsubok ni Pearson, ay binuo.
Ang goodness-of-fit test ay isang criterion para sa pagsubok ng hypothesis tungkol sa iminungkahing batas ng hindi kilalang pamamahagi.
Ang χ2 ("chi-square") na pagsubok ay ginagamit upang subukan ang hypothesis ng iba't ibang distribusyon. Ito ang kanyang merito.
Ang formula ng pagkalkula ng criterion ay katumbas ng

kung saan ang m at m' ay ang empirical at theoretical frequency, ayon sa pagkakabanggit
pamamahagi na isinasaalang-alang;
n ay ang bilang ng mga antas ng kalayaan.
Para sa pag-verify, kailangan nating ihambing ang empirical (naobserbahan) at teoretikal (kinakalkula sa ilalim ng pagpapalagay ng isang normal na distribusyon) na mga frequency.
Kung ang mga empirical frequency ay ganap na tumutugma sa mga frequency na kinakalkula o inaasahan, S (E - T) = 0 at ang criterion χ2 ay magiging katumbas din ng zero. Kung ang S (E - T) ay hindi katumbas ng zero, ito ay magsasaad ng pagkakaiba sa pagitan ng mga nakalkulang frequency at ng mga empirical na frequency ng serye. Sa ganitong mga kaso, kinakailangan upang suriin ang kahalagahan ng χ2 criterion, na theoretically ay maaaring mag-iba mula sa zero hanggang infinity. Ginagawa ito sa pamamagitan ng paghahambing ng aktwal na nakuhang halaga ng χ2ph sa kritikal na halaga nito (χ2st). hanggang χ2st para sa tinatanggap na antas ng kahalagahan (a) at bilang ng mga antas ng kalayaan (n).



