Ang pagpapakalat ay kinakalkula bilang isang pagkakaiba. Pagpapakalat ng isang discrete random variable
Pag-asa sa matematika (average na halaga) random variable Ang X , na ibinigay sa isang discrete probability space, ay tinatawag na bilang m =M[X]=∑x i p i , kung ang serye ay ganap na nagtatagpo.
Pagtatalaga ng serbisyo. Gamit ang isang online na serbisyo kalkulado inaasahang halaga, pagkakaiba at karaniwang paglihis(tingnan ang halimbawa). Bilang karagdagan, ang isang graph ng distribution function na F(X) ay naka-plot.
Mga katangian ng inaasahan sa matematika ng isang random na variable
- Ang mathematical na inaasahan ng isang pare-parehong halaga ay katumbas ng sarili nito: M[C]=C , C ay isang pare-pareho;
- M=C M[X]
- Ang inaasahan sa matematika ng kabuuan ng mga random na variable ay katumbas ng kabuuan ng kanilang mga inaasahan sa matematika: M=M[X]+M[Y]
- Ang mathematical expectation ng produkto ng independent random variables ay katumbas ng product ng kanilang mathematical expectations: M=M[X] M[Y] kung ang X at Y ay independyente.
Mga Katangian ng Dispersion
- Ang dispersion ng isang pare-parehong halaga ay katumbas ng zero: D(c)=0.
- Ang constant factor ay maaaring alisin mula sa ilalim ng dispersion sign sa pamamagitan ng pag-square nito: D(k*X)= k 2 D(X).
- Kung ang mga random na variable na X at Y ay independyente, kung gayon ang pagkakaiba ng kabuuan ay katumbas ng kabuuan ng mga pagkakaiba: D(X+Y)=D(X)+D(Y).
- Kung ang mga random na variable X at Y ay nakasalalay: D(X+Y)=DX+DY+2(X-M[X])(Y-M[Y])
- Para sa pagkakaiba, valid ang computational formula:
D(X)=M(X 2)-(M(X)) 2
Halimbawa. Ang mga inaasahan at pagkakaiba sa matematika ng dalawang independiyenteng random na variable X at Y ay kilala: M(x)=8 , M(Y)=7 , D(X)=9 , D(Y)=6 . Hanapin ang mathematical expectation at variance ng random variable Z=9X-8Y+7 .
Desisyon. Batay sa mga katangian ng inaasahan sa matematika: M(Z) = M(9X-8Y+7) = 9*M(X) - 8*M(Y) + M(7) = 9*8 - 8*7 + 7 = 23 .
Batay sa mga katangian ng pagpapakalat: D(Z) = D(9X-8Y+7) = D(9X) - D(8Y) + D(7) = 9^2D(X) - 8^2D(Y) + 0 = 81*9 - 64*6 = 345
Algorithm para sa pagkalkula ng inaasahan sa matematika
Mga katangian ng mga discrete random variable: ang lahat ng kanilang mga halaga ay maaaring muling bilangin natural na mga numero; Italaga ang bawat halaga ng isang hindi zero na posibilidad.- I-multiply nang paisa-isa ang mga pares: x i sa p i .
- Idinaragdag namin ang produkto ng bawat pares x i p i .
Halimbawa, para sa n = 4: m = ∑x i p i = x 1 p 1 + x 2 p 2 + x 3 p 3 + x 4 p 4
Halimbawa #1.
| x i | 1 | 3 | 4 | 7 | 9 |
| pi | 0.1 | 0.2 | 0.1 | 0.3 | 0.3 |
Ang mathematical expectation ay matatagpuan sa pamamagitan ng formula m = ∑x i p i .
Pag-asa sa matematika M[X].
M[x] = 1*0.1 + 3*0.2 + 4*0.1 + 7*0.3 + 9*0.3 = 5.9
Ang dispersion ay matatagpuan sa pamamagitan ng formula d = ∑x 2 i p i - M[x] 2 .
Dispersion D[X].
D[X] = 1 2 *0.1 + 3 2 *0.2 + 4 2 *0.1 + 7 2 *0.3 + 9 2 *0.3 - 5.9 2 = 7.69
Standard deviation σ(x).
σ = sqrt(D[X]) = sqrt(7.69) = 2.78
Halimbawa #2. Ang isang discrete random variable ay may sumusunod na serye ng pamamahagi:
| X | -10 | -5 | 0 | 5 | 10 |
| R | a | 0,32 | 2a | 0,41 | 0,03 |
Desisyon. Ang halaga a ay matatagpuan mula sa relasyon: Σp i = 1
Σp i = a + 0.32 + 2 a + 0.41 + 0.03 = 0.76 + 3 a = 1
0.76 + 3 a = 1 o 0.24=3 a , kung saan a = 0.08
Halimbawa #3. Tukuyin ang batas ng pamamahagi ng isang discrete random variable kung ang pagkakaiba nito ay kilala, at x 1
p 1 =0.3; p2=0.3; p3=0.1; p 4 \u003d 0.3
d(x)=12.96
Desisyon.
Dito kailangan mong gumawa ng formula para sa paghahanap ng variance d (x):
d(x) = x 1 2 p 1 +x 2 2 p 2 +x 3 2 p 3 +x 4 2 p 4 -m(x) 2
kung saan inaasahan m(x)=x 1 p 1 +x 2 p 2 +x 3 p 3 +x 4 p 4
Para sa aming data
m(x)=6*0.3+9*0.3+x 3 *0.1+15*0.3=9+0.1x 3
12.96 = 6 2 0.3+9 2 0.3+x 3 2 0.1+15 2 0.3-(9+0.1x 3) 2
o -9/100 (x 2 -20x+96)=0
Alinsunod dito, kinakailangan upang mahanap ang mga ugat ng equation, at magkakaroon ng dalawa sa kanila.
x 3 \u003d 8, x 3 \u003d 12
Pinipili namin ang isa na nakakatugon sa kundisyon x 1
Batas sa pamamahagi ng isang discrete random variable
x 1 =6; x2=9; x 3 \u003d 12; x4=15
p 1 =0.3; p2=0.3; p3=0.1; p 4 \u003d 0.3
Ang dispersion ay isang sukatan ng dispersion na naglalarawan ng kamag-anak na paglihis sa pagitan ng mga halaga ng data at ang ibig sabihin. Ito ang pinakakaraniwang ginagamit na sukat ng dispersion sa mga istatistika, na kinakalkula sa pamamagitan ng pagsusuma, squared, ang paglihis ng bawat halaga ng data mula sa mean. Ang formula para sa pagkalkula ng pagkakaiba ay ipinapakita sa ibaba:
![]()
s 2 - sample na pagkakaiba-iba;
x cf ay ang ibig sabihin ng halaga ng sample;
n — laki ng sample (bilang ng mga halaga ng data),
(x i – x cf) ay ang paglihis mula sa mean na halaga para sa bawat halaga ng set ng data.
Upang mas maunawaan ang formula, tingnan natin ang isang halimbawa. Hindi naman ako mahilig magluto kaya bihira lang ako. Gayunpaman, upang hindi mamatay sa gutom, paminsan-minsan ay kailangan kong pumunta sa kalan upang ipatupad ang plano na ibabad ang aking katawan sa mga protina, taba at carbohydrates. Ipinapakita ng set ng data sa ibaba kung gaano karaming beses nagluluto ng pagkain si Renat bawat buwan:
Ang unang hakbang sa pagkalkula ng pagkakaiba ay upang matukoy ang sample mean, na sa aming halimbawa ay 7.8 beses sa isang buwan. Ang natitirang mga kalkulasyon ay maaaring mapadali sa tulong ng sumusunod na talahanayan.

Ang huling yugto ng pagkalkula ng pagkakaiba ay ganito ang hitsura:
![]()
Para sa mga gustong gawin ang lahat ng mga kalkulasyon nang sabay-sabay, ang equation ay magiging ganito:
Gamit ang paraan ng raw count (halimbawa ng pagluluto)
Mayroong mas mahusay na paraan upang kalkulahin ang pagkakaiba, na kilala bilang ang "raw counting" na paraan. Bagaman sa unang sulyap ang equation ay maaaring mukhang medyo masalimuot, sa katunayan hindi ito nakakatakot. Maaari mong i-verify ito, at pagkatapos ay magpasya kung aling paraan ang pinakagusto mo.

ay ang kabuuan ng bawat halaga ng data pagkatapos i-squaring,
ay ang parisukat ng kabuuan ng lahat ng mga halaga ng data.
Huwag masiraan ng isip ngayon. Ilagay natin ang lahat sa anyo ng isang talahanayan, at pagkatapos ay makikita mo na mayroong mas kaunting mga kalkulasyon dito kaysa sa nakaraang halimbawa.


Tulad ng nakikita mo, ang resulta ay pareho sa paggamit ng nakaraang pamamaraan. Ang mga bentahe ng pamamaraang ito ay nagiging maliwanag habang lumalaki ang laki ng sample (n).
Pagkalkula ng pagkakaiba-iba sa Excel
Tulad ng malamang na nahulaan mo na, ang Excel ay may formula na nagbibigay-daan sa iyong kalkulahin ang pagkakaiba. Bukod dito, simula sa Excel 2010, makakahanap ka ng 4 na uri ng dispersion formula:
1) VAR.V - Ibinabalik ang variance ng sample. Binabalewala ang mga halaga at teksto ng Boolean.
2) VAR.G - Ibinabalik ang pagkakaiba-iba ng populasyon. Binabalewala ang mga halaga at teksto ng Boolean.
3) VASP - Ibinabalik ang sample na variance, na isinasaalang-alang ang mga halaga ng boolean at text.
4) VARP - Ibinabalik ang pagkakaiba ng populasyon, na isinasaalang-alang ang lohikal at mga halaga ng teksto.
Una, tingnan natin ang pagkakaiba sa pagitan ng isang sample at isang populasyon. Ang layunin ng mga deskriptibong istatistika ay upang buod o magpakita ng data sa paraang mabilis na makakuha ng isang malaking larawan, kumbaga, isang pangkalahatang-ideya. Nagbibigay-daan sa iyo ang statistic inference na gumawa ng mga inferences tungkol sa isang populasyon batay sa isang sample ng data mula sa populasyon na ito. Kinakatawan ng populasyon ang lahat ng posibleng resulta o sukat na interesante sa atin. Ang sample ay isang subset ng isang populasyon.
Halimbawa, interesado kami sa kabuuan ng isang pangkat ng mga mag-aaral mula sa isa sa mga unibersidad ng Russia at kailangan naming matukoy ang average na marka ng grupo. Maaari naming kalkulahin ang average na pagganap ng mga mag-aaral, at pagkatapos ay ang resultang figure ay magiging isang parameter, dahil ang buong populasyon ay kasangkot sa aming mga kalkulasyon. Gayunpaman, kung gusto nating kalkulahin ang GPA ng lahat ng mga mag-aaral sa ating bansa, ang grupong ito ang magiging sample natin.
Ang pagkakaiba sa formula para sa pagkalkula ng pagkakaiba sa pagitan ng sample at populasyon ay nasa denominator. Kung saan para sa sample ito ay magiging katumbas ng (n-1), at para sa pangkalahatang populasyon lamang n.
Ngayon ay haharapin natin ang mga pag-andar ng pagkalkula ng pagkakaiba-iba sa mga pagtatapos PERO, sa paglalarawan kung saan sinasabing ang pagkalkula ay isinasaalang-alang ang teksto at mga lohikal na halaga. Sa kasong ito, kapag kinakalkula ang pagkakaiba-iba ng isang partikular na set ng data kung saan nangyayari ang mga hindi numeric na halaga, bibigyang-kahulugan ng Excel ang text at false boolean bilang 0, at true boolean bilang 1.
Kaya, kung mayroon kang hanay ng data, hindi magiging mahirap na kalkulahin ang pagkakaiba nito gamit ang isa sa mga function ng Excel na nakalista sa itaas.

Ang mga pangunahing tagapagpahiwatig ng pag-generalize ng pagkakaiba-iba sa mga istatistika ay dispersion at standard deviation.
Pagpapakalat ito ibig sabihin ng aritmetika squared deviations ng bawat feature value mula sa kabuuang mean. Ang variance ay karaniwang tinatawag na mean square ng mga deviations at ito ay denoted 2 . Depende sa paunang data, ang pagkakaiba ay maaaring kalkulahin mula sa arithmetic mean, simple o weighted:
walang timbang (simple) pagpapakalat;
 may timbang na pagkakaiba.
may timbang na pagkakaiba.
Karaniwang lihis Ang ay isang pangkalahatang katangian ng ganap na sukat mga pagkakaiba-iba katangian sa pinagsama-samang. Ito ay ipinahayag sa parehong mga yunit ng sign (sa metro, tonelada, porsyento, ektarya, atbp.).
Ang karaniwang paglihis ay ang square root ng variance at tinutukoy ng :
 walang timbang na karaniwang paglihis;
walang timbang na karaniwang paglihis;
 weighted standard deviation.
weighted standard deviation.
Ang standard deviation ay isang sukatan ng pagiging maaasahan ng mean. Kung mas maliit ang standard deviation, mas maganda ang arithmetic mean na sumasalamin sa buong kinakatawan na populasyon.
Ang pagkalkula ng karaniwang paglihis ay nauuna sa pagkalkula ng pagkakaiba.
Ang pamamaraan para sa pagkalkula ng timbang na pagkakaiba ay ang mga sumusunod:
1) tukuyin ang arithmetic weighted average:
2) kalkulahin ang mga paglihis ng mga pagpipilian mula sa average:
3) parisukat ang paglihis ng bawat opsyon mula sa mean:
4) multiply squared deviations sa pamamagitan ng mga timbang (mga frequency):
5) ibuod ang mga natanggap na gawa:
![]()
6) ang nagresultang halaga ay hinati sa kabuuan ng mga timbang:

Halimbawa 2.1

Kalkulahin ang arithmetic weighted average:

Ang mga halaga ng mga paglihis mula sa mean at ang kanilang mga parisukat ay ipinakita sa talahanayan. Tukuyin natin ang pagkakaiba:

Ang karaniwang paglihis ay magiging katumbas ng:

Kung ang pinagmulan ng data ay ipinakita bilang isang pagitan serye ng pamamahagi , pagkatapos ay kailangan mo munang matukoy ang discrete value ng feature, at pagkatapos ay ilapat ang pamamaraang inilarawan.
Halimbawa 2.2
Ipakita natin ang pagkalkula ng pagkakaiba-iba para sa serye ng pagitan sa data sa pamamahagi ng nahasik na lugar ng kolektibong sakahan sa pamamagitan ng ani ng trigo.

Ang ibig sabihin ng arithmetic ay:

Kalkulahin natin ang pagkakaiba:

6.3. Pagkalkula ng dispersion ayon sa formula para sa indibidwal na data
Teknik sa pagkalkula pagpapakalat kumplikado, at para sa malalaking halaga ng mga opsyon at frequency ay maaaring maging mahirap. Ang mga kalkulasyon ay maaaring gawing simple gamit ang mga katangian ng pagpapakalat.
Ang dispersion ay may mga sumusunod na katangian.
1. Ang pagbaba o pagtaas sa mga timbang (frequencies) ng isang variable na feature sa isang tiyak na bilang ng beses ay hindi nagbabago sa dispersion.
2. Pagbaba o pagtaas ng bawat halaga ng tampok sa pamamagitan ng parehong pare-parehong halaga PERO hindi nagbabago ang dispersion.
3. Pagbaba o pagtaas ng bawat halaga ng tampok sa isang tiyak na bilang ng beses k ayon sa pagkakabanggit ay binabawasan o pinapataas ang pagkakaiba sa k 2 beses karaniwang lihis sa k minsan.
4. Ang pagkakaiba-iba ng isang tampok na nauugnay sa isang arbitrary na halaga ay palaging mas malaki kaysa sa pagkakaiba-iba na nauugnay sa arithmetic mean sa pamamagitan ng parisukat ng pagkakaiba sa pagitan ng average at arbitrary na mga halaga:
![]()
Kung ang PERO 0, pagkatapos ay dumating tayo sa sumusunod na pagkakapantay-pantay:
ibig sabihin, ang pagkakaiba-iba ng isang tampok ay katumbas ng pagkakaiba sa pagitan ng mean square ng mga halaga ng tampok at ang square ng mean.
Ang bawat property ay maaaring gamitin nang mag-isa o kasama ng iba kapag kinakalkula ang pagkakaiba.
Ang pamamaraan para sa pagkalkula ng pagkakaiba ay simple:
1) matukoy ibig sabihin ng aritmetika :
2) parisukat ang arithmetic mean:

3) parisukat ang paglihis ng bawat variant ng serye:
X i 2 .
4) hanapin ang kabuuan ng mga parisukat ng mga opsyon:
5) hatiin ang kabuuan ng mga parisukat ng mga opsyon sa kanilang numero, ibig sabihin, matukoy ang average na parisukat:
6) tukuyin ang pagkakaiba sa pagitan ng mean square ng feature at square ng mean:
Halimbawa 3.1 Mayroon kaming sumusunod na data sa pagiging produktibo ng mga manggagawa:

Gawin natin ang mga sumusunod na kalkulasyon:
![]()
Gayunpaman, ang katangiang ito lamang ay hindi pa sapat para sa pag-aaral ng isang random na variable. Isipin ang dalawang shooters na bumaril sa isang target. Ang isa ay nag-shoot nang tumpak at tumama malapit sa gitna, at ang isa pa ... nagsasaya lang at hindi man lang nagpuntirya. Pero ang nakakatuwa dun karaniwan ang resulta ay eksaktong kapareho ng unang tagabaril! Ang sitwasyong ito ay may kondisyong inilalarawan ng mga sumusunod na random na variable:
Ang "sniper" na inaasahan sa matematika ay katumbas ng , gayunpaman, para sa "kawili-wiling tao": - ito ay zero din!
Kaya, mayroong pangangailangan upang mabilang kung gaano kalayo nakakalat bullet (mga halaga ng isang random na variable) na may kaugnayan sa gitna ng target (inaasahan). mabuti at nakakalat isinalin mula sa Latin lamang bilang pagpapakalat .
Tingnan natin kung paano tinutukoy ang numerical na katangiang ito sa isa sa mga halimbawa ng unang bahagi ng aralin: 
Doon ay natagpuan namin ang isang nakakabigo na pag-asa sa matematika ng larong ito, at ngayon kailangan naming kalkulahin ang pagkakaiba nito, na ipinapahiwatig sa pamamagitan ng .
Alamin natin kung gaano kalayo ang "scattered" ng mga panalo/talo sa average na halaga. Malinaw, para dito kailangan nating kalkulahin pagkakaiba sa pagitan mga halaga ng isang random na variable at siya inaasahan sa matematika:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Ngayon ay tila kinakailangan upang buod ang mga resulta, ngunit ang paraang ito ay hindi maganda - sa kadahilanang ang mga oscillations sa kaliwa ay magkakansela sa isa't isa sa mga oscillations sa kanan. Kaya, halimbawa, ang "amateur" na tagabaril (halimbawa sa itaas) ang mga pagkakaiba ay magiging ![]() , at kapag idinagdag ay magbibigay sila ng zero, kaya hindi kami makakakuha ng anumang pagtatantya ng pagkalat ng kanyang pagbaril.
, at kapag idinagdag ay magbibigay sila ng zero, kaya hindi kami makakakuha ng anumang pagtatantya ng pagkalat ng kanyang pagbaril.
Upang makayanan ang inis na ito, isaalang-alang mga module mga pagkakaiba, ngunit para sa mga teknikal na kadahilanan, ang diskarte ay nag-ugat kapag ang mga ito ay kuwadrado. Ito ay mas maginhawa upang ayusin ang solusyon sa isang talahanayan: 
At dito ito nagmamakaawa na kalkulahin weighted average ang halaga ng mga squared deviations. Ano ito? sa kanila ito inaasahang halaga, na siyang sukatan ng pagkakalat:
![]() – kahulugan pagpapakalat. Ito ay kaagad na malinaw mula sa kahulugan na hindi maaaring negatibo ang pagkakaiba- tandaan para sa pagsasanay!
– kahulugan pagpapakalat. Ito ay kaagad na malinaw mula sa kahulugan na hindi maaaring negatibo ang pagkakaiba- tandaan para sa pagsasanay!
Tandaan natin kung paano hanapin ang inaasahan. I-multiply ang mga squared differences sa mga katumbas na probabilities (Pagpapatuloy ng talahanayan):
- sa matalinghagang pagsasalita, ito ay "traction force",
at ibuod ang mga resulta:
Hindi mo ba naisip na laban sa background ng mga panalo, ang resulta ay naging napakalaki? Iyan ay tama - kami ay nag-squaring, at upang bumalik sa dimensyon ng aming laro, kailangan naming kunin ang square root. Ang halagang ito ay tinatawag karaniwang lihis
at tinutukoy ng letrang Griyego na "sigma":
Minsan ang kahulugan na ito ay tinatawag karaniwang lihis .
Ano ang kahulugan nito? Kung lumihis tayo mula sa inaasahan sa matematika sa kaliwa at kanan sa pamamagitan ng karaniwang paglihis: ![]()
– kung gayon ang pinaka-malamang na mga halaga ng random na variable ay magiging "puro" sa pagitan na ito. Ano talaga ang nakikita natin:
Gayunpaman, nangyari na sa pagsusuri ng scattering halos palaging gumana sa konsepto ng dispersion. Tingnan natin kung ano ang ibig sabihin nito kaugnay ng mga laro. Kung sa kaso ng mga shooter ay pinag-uusapan natin ang "katumpakan" ng mga hit na nauugnay sa gitna ng target, kung gayon narito ang pagpapakalat ng dalawang bagay:
Una, malinaw na habang tumataas ang mga rate, tumataas din ang pagkakaiba. Kaya, halimbawa, kung tataas tayo ng 10 beses, ang inaasahan sa matematika ay tataas ng 10 beses, at ang pagkakaiba ay tataas ng 100 beses (sa sandaling ito ay isang quadratic na halaga). Ngunit tandaan na ang mga patakaran ng laro ay hindi nagbago! Ang mga rate lang ang nagbago, halos nagsasalita, dati kaming tumaya ng 10 rubles, ngayon ay 100.
Ang pangalawa, mas kawili-wiling punto ay ang pagkakaiba-iba ay nagpapakilala sa estilo ng paglalaro. Ayusin sa isip ang mga rate ng laro sa ilang tiyak na antas, at tingnan kung ano dito:
Ang isang mababang pagkakaiba ng laro ay isang maingat na laro. Ang manlalaro ay may posibilidad na pumili ng pinaka-maaasahang mga scheme, kung saan hindi siya matatalo/manalo ng sobra sa isang pagkakataon. Halimbawa, ang pula/itim na sistema sa roulette (tingnan ang Halimbawa 4 ng artikulo mga random na variable) .
Mataas na pagkakaiba ng laro. Madalas siyang tinatawag pagpapakalat laro. Ito ay isang adventurous o agresibong istilo ng paglalaro kung saan pinipili ng manlalaro ang mga "adrenaline" scheme. Alalahanin man lang natin "Martingale", kung saan ang mga sums na nakataya ay mga order ng magnitude na mas malaki kaysa sa "tahimik" na laro ng nakaraang talata.
Ang sitwasyon sa poker ay indicative: may mga tinatawag na masikip mga manlalaro na may posibilidad na maging maingat at "iiling" sa kanilang mga pondo sa laro (bankroll). Hindi nakakagulat, ang kanilang bankroll ay hindi masyadong nagbabago (mababa ang pagkakaiba-iba). Sa kabaligtaran, kung ang isang manlalaro ay may mataas na pagkakaiba, kung gayon ito ang aggressor. Madalas siyang nakipagsapalaran, gumagawa ng malalaking taya at maaaring masira ang isang malaking bangko at magkawatak-watak.
Ang parehong bagay ay nangyayari sa Forex, at iba pa - mayroong maraming mga halimbawa.
Bukod dito, sa lahat ng pagkakataon ay hindi mahalaga kung ang laro ay para sa isang sentimos o para sa libu-libong dolyar. Ang bawat antas ay may mababa at mataas na pagkakaiba-iba ng mga manlalaro. Well, para sa average na panalo, tulad ng naaalala natin, "responsable" inaasahang halaga.
Marahil ay napansin mo na ang paghahanap ng pagkakaiba ay isang mahaba at maingat na proseso. Ngunit ang matematika ay mapagbigay:
Formula para sa paghahanap ng pagkakaiba
Ang pormula na ito ay direktang hinango mula sa kahulugan ng pagkakaiba, at agad naming inilagay ito sa sirkulasyon. Kokopyahin ko ang plato sa aming laro mula sa itaas: 
at ang nahanap na inaasahan.
Kinakalkula namin ang pagkakaiba-iba sa pangalawang paraan. Una, hanapin natin ang mathematical na inaasahan - ang parisukat ng random variable . Sa pamamagitan ng kahulugan ng inaasahan sa matematika:
Sa kasong ito:
Kaya, ayon sa formula:
Sabi nga nila, feel the difference. At sa pagsasagawa, siyempre, mas mahusay na ilapat ang formula (maliban kung ang kundisyon ay nangangailangan ng iba).
Kabisado namin ang pamamaraan ng paglutas at pagdidisenyo:
Halimbawa 6

Hanapin ang mathematical expectation, variance at standard deviation nito.
Ang gawaing ito ay matatagpuan sa lahat ng dako, at, bilang isang panuntunan, napupunta nang walang makabuluhang kahulugan.
Maaari mong isipin ang ilang mga bombilya na may mga numero na lumiliwanag sa isang baliw na may ilang mga posibilidad :)
Desisyon: Ito ay maginhawa upang ibuod ang mga pangunahing kalkulasyon sa isang talahanayan. Una, isinusulat namin ang paunang data sa dalawang nangungunang linya. Pagkatapos ay kinakalkula namin ang mga produkto, pagkatapos at sa wakas ang mga kabuuan sa kanang hanay: 
Actually, halos handa na ang lahat. Sa ikatlong linya, ang isang handa na pag-asa sa matematika ay iginuhit: ![]() .
.
Ang pagpapakalat ay kinakalkula ng formula:
At sa wakas, ang karaniwang paglihis:
- Sa personal, karaniwan kong iniikot sa 2 decimal na lugar.
Ang lahat ng mga kalkulasyon ay maaaring isagawa sa isang calculator, at kahit na mas mahusay - sa Excel:
Mahirap magkamali dito :)
Sagot:
Ang mga nagnanais ay mas pasimplehin ang kanilang buhay at samantalahin ang aking calculator (demo), na hindi lamang agad na malulutas ang problemang ito, ngunit bumubuo rin pampakay na graphics (malapit na). Ang programa ay maaaring download sa library– kung nag-download ka ng kahit isang materyal sa pag-aaral, o nakatanggap ibang paraan. Salamat sa pagsuporta sa proyekto!
Ang ilang mga gawain para sa independiyenteng solusyon:
Halimbawa 7
Kalkulahin ang pagkakaiba ng random variable ng nakaraang halimbawa sa pamamagitan ng kahulugan.
At isang katulad na halimbawa:
Halimbawa 8
Ang isang discrete random variable ay ibinibigay ng sarili nitong batas sa pamamahagi:

Oo, ang mga halaga ng random na variable ay maaaring masyadong malaki (halimbawa mula sa totoong trabaho), at dito, kung maaari, gamitin ang Excel. Bilang, sa pamamagitan ng paraan, sa Halimbawa 7 - ito ay mas mabilis, mas maaasahan at mas kaaya-aya.
Mga solusyon at sagot sa ibaba ng pahina.
Sa pagtatapos ng ika-2 bahagi ng aralin, susuriin natin ang isa pang karaniwang gawain, maaaring sabihin ng isang maliit na rebus:
Halimbawa 9
Ang isang discrete random variable ay maaaring tumagal lamang ng dalawang halaga: at , at . Ang posibilidad, mathematical na inaasahan at pagkakaiba ay kilala.
Desisyon: Magsimula tayo sa hindi kilalang posibilidad. Dahil ang isang random na variable ay maaaring tumagal lamang ng dalawang halaga, kung gayon ang kabuuan ng mga probabilidad ng mga kaukulang kaganapan:
at simula noon .
Ito ay nananatiling mahanap ..., madaling sabihin :) Ngunit oh well, nagsimula ito. Sa pamamagitan ng kahulugan ng inaasahan sa matematika: ![]() - palitan ang mga kilalang halaga:
- palitan ang mga kilalang halaga:
![]() - at wala nang mapipiga sa equation na ito, maliban na maaari mong muling isulat ito sa karaniwang direksyon:
- at wala nang mapipiga sa equation na ito, maliban na maaari mong muling isulat ito sa karaniwang direksyon: ![]()

o: ![]()
Tungkol sa mga karagdagang aksyon, sa tingin ko maaari mong hulaan. Gawin at lutasin natin ang system: 
Ang mga desimal ay, siyempre, isang kumpletong kahihiyan; i-multiply ang parehong equation sa 10: 
at hatiin sa 2: 
Mas mabuti iyon. Mula sa 1st equation ipinapahayag namin: ![]() (ito ang mas madaling paraan)- kapalit sa 2nd equation:
(ito ang mas madaling paraan)- kapalit sa 2nd equation:
![]()
Nagtatayo kami parisukat at gumawa ng mga pagpapasimple: 
Kami ay nagpaparami sa: 
Ang resulta, quadratic equation, hanapin ang diskriminasyon nito:
- perpekto!
at nakakakuha kami ng dalawang solusyon:
1) kung ![]() , pagkatapos
, pagkatapos ![]() ;
;
2) kung ![]() , pagkatapos .
, pagkatapos .
Ang unang pares ng mga halaga ay nakakatugon sa kondisyon. Sa isang mataas na posibilidad, tama ang lahat, ngunit, gayunpaman, isinulat namin ang batas sa pamamahagi: 
at magsagawa ng tseke, ibig sabihin, hanapin ang inaasahan:
Kasabay ng pag-aaral ng pagkakaiba-iba ng isang katangian sa buong populasyon sa kabuuan, kadalasang kinakailangan na subaybayan ang dami ng mga pagbabago sa katangian sa mga pangkat kung saan nahahati ang populasyon, gayundin sa pagitan ng mga pangkat. Ang pag-aaral ng variation na ito ay nakakamit sa pamamagitan ng pagkalkula at pagsusuri ng iba't ibang uri ng variance.
Matukoy ang pagkakaiba sa pagitan ng kabuuang, intergroup at intragroup dispersion.
Kabuuang pagkakaiba σ 2 sinusukat ang pagkakaiba-iba ng isang katangian sa buong populasyon sa ilalim ng impluwensya ng lahat ng mga salik na naging sanhi ng pagkakaiba-iba na ito, .
Intergroup variance (δ) characterizes systematic variation, i.e. mga pagkakaiba sa laki ng katangiang pinag-aaralan, na nagmumula sa ilalim ng impluwensya ng trait-factor na pinagbabatayan ng pagpapangkat. Ito ay kinakalkula ng formula: 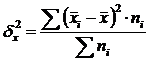 .
.
Pagkakaiba-iba sa loob ng pangkat (σ) sumasalamin sa random na pagkakaiba-iba, i.e. bahagi ng pagkakaiba-iba na nagaganap sa ilalim ng impluwensya ng hindi natukoy na mga salik at hindi nakadepende sa katangiang salik na pinagbabatayan ng pagpapangkat. Ito ay kinakalkula ng formula: 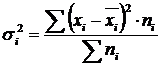 .
.
Average ng mga pagkakaiba-iba sa loob ng pangkat:  .
.
May batas na nag-uugnay sa 3 uri ng pagpapakalat. Ang kabuuang pagkakaiba ay katumbas ng kabuuan ng average ng mga pagkakaiba-iba ng intragroup at intergroup: ![]() .
.
Ang ratio na ito ay tinatawag panuntunan sa pagdaragdag ng pagkakaiba.
Sa pagsusuri, malawakang ginagamit ang isang panukat, na siyang proporsyon ng pagkakaiba-iba sa pagitan ng pangkat sa kabuuang pagkakaiba. Taglay nito ang pangalan empirical coefficient ng determinasyon (η 2): .
Ang square root ng empirical coefficient of determination ay tinatawag empirical correlation ratio (η):
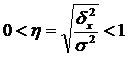 .
.
Inilalarawan nito ang impluwensya ng katangiang pinagbabatayan ng pagpapangkat sa pagkakaiba-iba ng nagresultang katangian. Ang empirical correlation ratio ay nag-iiba mula 0 hanggang 1.
Ipapakita namin ang praktikal na paggamit nito sa sumusunod na halimbawa (Talahanayan 1).
Halimbawa #1. Talahanayan 1 - Produktibidad ng paggawa ng dalawang grupo ng mga manggagawa ng isa sa mga workshop ng NPO "Cyclone"
Kalkulahin ang kabuuan at ang mga average at pagkakaiba-iba ng pangkat:
Ang paunang data para sa pagkalkula ng average ng intragroup at intergroup dispersion ay ipinakita sa Talahanayan. 2.
talahanayan 2
Pagkalkula at δ 2 para sa dalawang grupo ng mga manggagawa.
|
Mga grupo ng manggagawa | Bilang ng mga manggagawa, pers. | Karaniwan, det./shift. | Pagpapakalat |
| Nakapasa sa teknikal na pagsasanay | 5 | 95 | 42,0 |
| Hindi sinanay sa teknikal | 5 | 81 | 231,2 |
| Lahat ng manggagawa | 10 | 88 | 185,6 |
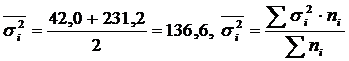 .
.
pagkakaiba-iba sa pagitan ng pangkat
Kabuuang pagkakaiba:
Kaya, ang empirical correlation ratio: .
Kasama ng variation ng quantitative traits, maaari ding obserbahan ang variation ng qualitative traits. Ang pag-aaral ng variation na ito ay nakakamit sa pamamagitan ng pagkalkula ng mga sumusunod na uri ng variances:
Ang pagkakaiba-iba ng intra-grupo ng bahagi ay tinutukoy ng formula
saan n i– ang bilang ng mga yunit sa magkakahiwalay na grupo.Ang proporsyon ng pinag-aralan na katangian sa buong populasyon, na tinutukoy ng formula:
Ang tatlong uri ng pagpapakalat ay nauugnay sa isa't isa tulad ng sumusunod:
Ang ratio na ito ng mga pagkakaiba ay tinatawag na feature share variance addition theorem.



