Mga istatistika ng agwat ng kumpiyansa. Mga pagitan ng kumpiyansa
Target– turuan ang mga mag-aaral ng algorithm para sa pagkalkula ng mga pagitan ng kumpiyansa istatistikal na mga parameter.
Sa panahon ng pagpoproseso ng istatistika ng data, ang kinakalkulang arithmetic mean, coefficient of variation, correlation coefficient, difference criteria at iba pang point statistics ay dapat makatanggap ng quantitative confidence limits, na nagpapahiwatig ng posibleng pagbabago ng indicator sa mas maliit at malaking bahagi sa loob ng agwat ng kumpiyansa.
Halimbawa 3.1
.
Ang pamamahagi ng calcium sa serum ng dugo ng mga unggoy, tulad ng dati nang itinatag, ay nailalarawan sa pamamagitan ng mga sumusunod na selektibong tagapagpahiwatig: = 11.94 mg%;  = 0.127 mg%; n= 100. Kinakailangang matukoy ang agwat ng kumpiyansa para sa pangkalahatang average (
= 0.127 mg%; n= 100. Kinakailangang matukoy ang agwat ng kumpiyansa para sa pangkalahatang average (  ) na may posibilidad na may kumpiyansa P
= 0,95.
) na may posibilidad na may kumpiyansa P
= 0,95.
Ang pangkalahatang average ay may tiyak na posibilidad sa pagitan:
 , saan
, saan 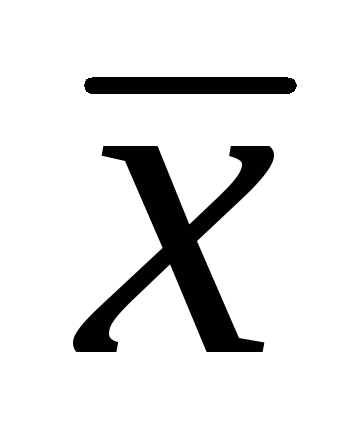 – sample na arithmetic mean; t- Pamantayan ng mag-aaral;
– sample na arithmetic mean; t- Pamantayan ng mag-aaral;  ay ang error ng arithmetic mean.
ay ang error ng arithmetic mean.
Ayon sa talahanayan na "Mga Halaga ng pamantayan ng Mag-aaral" nakita namin ang halaga
 na may antas ng kumpiyansa na 0.95 at ang bilang ng mga antas ng kalayaan k\u003d 100-1 \u003d 99. Ito ay katumbas ng 1.982. Kasama ang mga halaga ng arithmetic mean at statistical error, pinapalitan namin ito sa formula:
na may antas ng kumpiyansa na 0.95 at ang bilang ng mga antas ng kalayaan k\u003d 100-1 \u003d 99. Ito ay katumbas ng 1.982. Kasama ang mga halaga ng arithmetic mean at statistical error, pinapalitan namin ito sa formula:
o 11.69  12,19
12,19
Kaya, na may probabilidad na 95%, maaaring pagtalunan na ang pangkalahatang average ng normal na distribusyon na ito ay nasa pagitan ng 11.69 at 12.19 mg%.
Halimbawa 3.2
. Tukuyin ang mga hangganan ng 95% na agwat ng kumpiyansa para sa pangkalahatang pagkakaiba (  ) pamamahagi ng calcium sa dugo ng mga unggoy, kung ito ay kilala na
) pamamahagi ng calcium sa dugo ng mga unggoy, kung ito ay kilala na  = 1.60, na may n
= 100.
= 1.60, na may n
= 100.
Upang malutas ang problema, maaari mong gamitin ang sumusunod na formula:
saan  ay ang statistical error ng variance.
ay ang statistical error ng variance.
Hanapin ang sample na variance error gamit ang formula:  . Ito ay katumbas ng 0.11. Ibig sabihin t- criterion na may posibilidad na kumpiyansa na 0.95 at ang bilang ng mga antas ng kalayaan k= 100–1 = 99 ay kilala mula sa nakaraang halimbawa.
. Ito ay katumbas ng 0.11. Ibig sabihin t- criterion na may posibilidad na kumpiyansa na 0.95 at ang bilang ng mga antas ng kalayaan k= 100–1 = 99 ay kilala mula sa nakaraang halimbawa.
Gamitin natin ang formula at makuha ang:
o 1.38  1,82
1,82
Ang isang mas tumpak na agwat ng kumpiyansa para sa pangkalahatang pagkakaiba ay maaaring mabuo gamit  (chi-square) - Pagsubok ni Pearson. Ang mga kritikal na puntos para sa pamantayang ito ay ibinibigay sa isang espesyal na talahanayan. Kapag ginagamit ang pamantayan
(chi-square) - Pagsubok ni Pearson. Ang mga kritikal na puntos para sa pamantayang ito ay ibinibigay sa isang espesyal na talahanayan. Kapag ginagamit ang pamantayan  isang dalawang-panig na antas ng kahalagahan ay ginagamit upang bumuo ng isang pagitan ng kumpiyansa. Para sa lower bound, ang antas ng kahalagahan ay kinakalkula ng formula
isang dalawang-panig na antas ng kahalagahan ay ginagamit upang bumuo ng isang pagitan ng kumpiyansa. Para sa lower bound, ang antas ng kahalagahan ay kinakalkula ng formula  , para sa itaas
, para sa itaas  . Halimbawa, para sa antas ng kumpiyansa
. Halimbawa, para sa antas ng kumpiyansa  =
0,99
=
0,99 = 0,010,
= 0,010, = 0.990. Alinsunod dito, ayon sa talahanayan ng pamamahagi ng mga kritikal na halaga
= 0.990. Alinsunod dito, ayon sa talahanayan ng pamamahagi ng mga kritikal na halaga  , na may mga kinakalkula na antas ng kumpiyansa at bilang ng mga antas ng kalayaan k= 100 – 1= 99, hanapin ang mga halaga
, na may mga kinakalkula na antas ng kumpiyansa at bilang ng mga antas ng kalayaan k= 100 – 1= 99, hanapin ang mga halaga  at
at  . Nakukuha namin
. Nakukuha namin  katumbas ng 135.80, at
katumbas ng 135.80, at 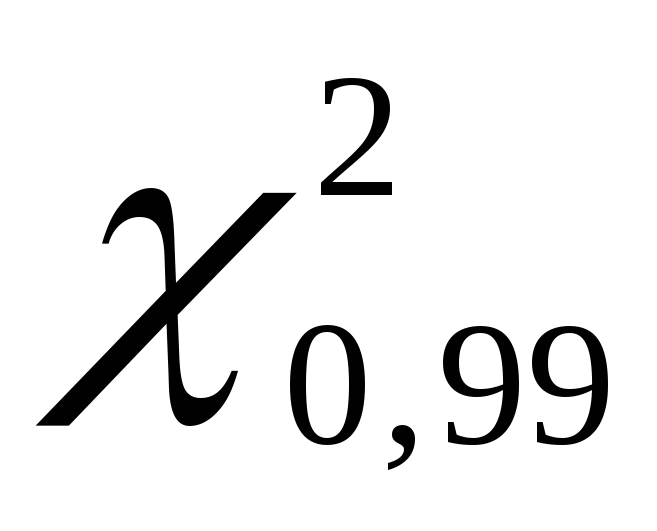 katumbas ng 70.06.
katumbas ng 70.06.
Upang mahanap ang mga limitasyon ng kumpiyansa ng pangkalahatang pagkakaiba gamit  ginagamit namin ang mga formula: para sa lower bound
ginagamit namin ang mga formula: para sa lower bound  , para sa upper bound
, para sa upper bound  . Palitan ang data ng gawain para sa mga nahanap na halaga
. Palitan ang data ng gawain para sa mga nahanap na halaga  sa mga formula:
sa mga formula:  =
1,17;
=
1,17; = 2.26. Kaya, na may antas ng kumpiyansa P= 0.99 o 99% ang pangkalahatang pagkakaiba ay nasa hanay mula 1.17 hanggang 2.26 mg% kasama.
= 2.26. Kaya, na may antas ng kumpiyansa P= 0.99 o 99% ang pangkalahatang pagkakaiba ay nasa hanay mula 1.17 hanggang 2.26 mg% kasama.
Halimbawa 3.3 . Sa 1000 buto ng trigo mula sa lote na dumating sa elevator, natagpuan ang 120 buto na nahawaan ng ergot. Ito ay kinakailangan upang matukoy ang posibleng mga hangganan ng kabuuang proporsyon ng mga nahawaang buto sa isang naibigay na batch ng trigo.
Ang mga limitasyon ng kumpiyansa para sa pangkalahatang bahagi para sa lahat ng posibleng halaga nito ay dapat matukoy ng formula:
 ,
,
saan n ay ang bilang ng mga obserbasyon; m ay ang ganap na bilang ng isa sa mga pangkat; t ay ang normalized deviation.
Ang sample na bahagi ng mga nahawaang buto ay katumbas ng  o 12%. Na may antas ng kumpiyansa R= 95% normalized deviation ( t-Ang pamantayan ng mag-aaral para sa k
=
o 12%. Na may antas ng kumpiyansa R= 95% normalized deviation ( t-Ang pamantayan ng mag-aaral para sa k
=
 )t
= 1,960.
)t
= 1,960.
Pinapalitan namin ang magagamit na data sa formula:
Samakatuwid, ang mga hangganan ng agwat ng kumpiyansa ay 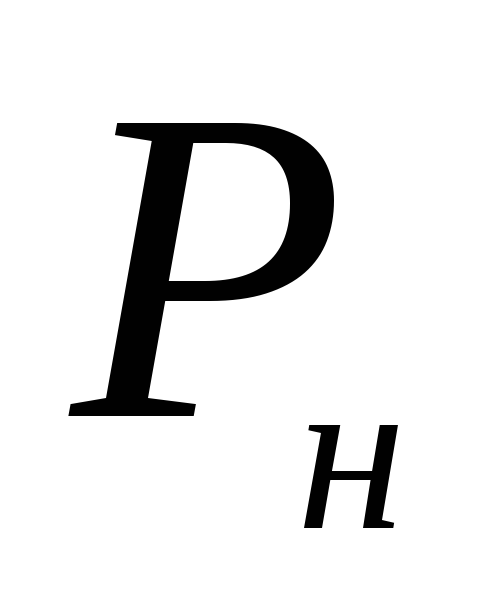 = 0.122–0.041 = 0.081, o 8.1%;
= 0.122–0.041 = 0.081, o 8.1%;  = 0.122 + 0.041 = 0.163, o 16.3%.
= 0.122 + 0.041 = 0.163, o 16.3%.
Kaya, kasama antas ng kumpiyansa 95% maaari itong mapagtatalunan na ang pangkalahatang proporsyon ng mga nahawaang buto ay nasa pagitan ng 8.1 at 16.3%.
Halimbawa 3.4 . Ang koepisyent ng pagkakaiba-iba, na nagpapakilala sa pagkakaiba-iba ng calcium (mg%) sa serum ng dugo ng mga unggoy, ay katumbas ng 10.6%. Laki ng sample n= 100. Kinakailangang matukoy ang mga hangganan ng 95% na agwat ng kumpiyansa para sa pangkalahatang parameter CV.
Mga limitasyon ng kumpiyansa para sa pangkalahatang koepisyent ng pagkakaiba-iba CV ay tinutukoy ng mga sumusunod na formula:
 at
at  , saan K
intermediate value na kinakalkula ng formula
, saan K
intermediate value na kinakalkula ng formula  .
.
Alam na may antas ng kumpiyansa R= 95% normalized deviation (T-test ng mag-aaral para sa k
=
 )t
= 1.960, paunang kalkulahin ang halaga SA:
)t
= 1.960, paunang kalkulahin ang halaga SA:
 .
.
 o 9.3%
o 9.3%
 o 12.3%
o 12.3%
Kaya, ang pangkalahatang koepisyent ng pagkakaiba-iba na may posibilidad ng kumpiyansa na 95% ay nasa saklaw mula 9.3 hanggang 12.3%. Sa paulit-ulit na mga sample, ang koepisyent ng variation ay hindi lalampas sa 12.3% at hindi bababa sa 9.3% sa 95 na mga kaso sa 100.
Mga tanong para sa pagpipigil sa sarili:

Mga gawain para sa malayang solusyon.
1. Ang average na porsyento ng taba sa gatas para sa paggagatas ng mga baka ng Kholmogory crosses ay ang mga sumusunod: 3.4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3.8; 3.4; 4.0; 3.3; 3.7; 3.5; 3.6; 3.4; 3.8. Magtakda ng mga pagitan ng kumpiyansa para sa pangkalahatang mean sa 95% na antas ng kumpiyansa (20 puntos).
2. Sa 400 halaman ng hybrid rye, ang mga unang bulaklak ay lumitaw sa average na 70.5 araw pagkatapos ng paghahasik. Ang karaniwang paglihis ay 6.9 araw. Tukuyin ang error ng mean at confidence interval para sa populasyong mean at variance sa isang significance level W= 0.05 at W= 0.01 (25 puntos).
3. Kapag pinag-aaralan ang haba ng mga dahon ng 502 specimens ng mga strawberry sa hardin, nakuha ang sumusunod na data:
 = 7.86 cm; σ = 1.32 cm,
= 7.86 cm; σ = 1.32 cm,  \u003d ± 0.06 cm Tukuyin ang mga pagitan ng kumpiyansa para sa arithmetic mean ng populasyon na may mga antas ng kabuluhan na 0.01; 0.02; 0.05. (25 puntos).
\u003d ± 0.06 cm Tukuyin ang mga pagitan ng kumpiyansa para sa arithmetic mean ng populasyon na may mga antas ng kabuluhan na 0.01; 0.02; 0.05. (25 puntos).
4. Kapag sinusuri ang 150 adultong lalaki, ang average na taas ay 167 cm, at σ \u003d 6 cm Ano ang mga limitasyon ng pangkalahatang average at pangkalahatang pagkakaiba na may posibilidad ng kumpiyansa na 0.99 at 0.95? (25 puntos).
5. Ang pamamahagi ng calcium sa serum ng dugo ng mga unggoy ay nailalarawan sa pamamagitan ng mga sumusunod na selektibong tagapagpahiwatig:
 = 11.94 mg%, σ
= 1,27, n
= 100. Mag-plot ng 95% na agwat ng kumpiyansa para sa ibig sabihin ng populasyon ng distribusyon na ito. Kalkulahin ang koepisyent ng pagkakaiba-iba (25 puntos).
= 11.94 mg%, σ
= 1,27, n
= 100. Mag-plot ng 95% na agwat ng kumpiyansa para sa ibig sabihin ng populasyon ng distribusyon na ito. Kalkulahin ang koepisyent ng pagkakaiba-iba (25 puntos).
6. Ang kabuuang nilalaman ng nitrogen sa plasma ng dugo ng mga albino rats sa edad na 37 at 180 araw ay pinag-aralan. Ang mga resulta ay ipinahayag sa gramo bawat 100 cm 3 ng plasma. Sa edad na 37 araw, 9 na daga ang may: 0.98; 0.83; 0.99; 0.86; 0.90; 0.81; 0.94; 0.92; 0.87. Sa edad na 180 araw, 8 daga ang may: 1.20; 1.18; 1.33; 1.21; 1.20; 1.07; 1.13; 1.12. Magtakda ng mga pagitan ng kumpiyansa para sa pagkakaiba na may antas ng kumpiyansa na 0.95 (50 puntos).
7. Tukuyin ang mga hangganan ng 95% agwat ng kumpiyansa para sa pangkalahatang pagkakaiba-iba ng pamamahagi ng calcium (mg%) sa serum ng dugo ng mga unggoy, kung para sa pamamahagi na ito ang laki ng sample n = 100, ang statistical error ng sample na pagkakaiba s σ 2 = 1.60 (40 puntos).
8. Tukuyin ang mga hangganan ng 95% na pagitan ng kumpiyansa para sa pangkalahatang pagkakaiba-iba ng distribusyon ng 40 spikelet ng trigo kasama ang haba (σ 2 = 40.87 mm 2). (25 puntos).
9. Ang paninigarilyo ay itinuturing na pangunahing salik na nagdudulot ng obstructive pulmonary disease. Ang passive smoking ay hindi itinuturing na isang kadahilanan. Kinuwestiyon ng mga siyentipiko ang kaligtasan ng passive smoking at sinuri ang daanan ng hangin sa mga non-smokers, passive at active smokers. Upang makilala ang estado ng respiratory tract, kinuha namin ang isa sa mga tagapagpahiwatig ng pag-andar ng panlabas na paghinga - ang maximum na volumetric velocity ng gitna ng pagbuga. Ang pagbaba sa tagapagpahiwatig na ito ay isang tanda ng kapansanan sa patency ng daanan ng hangin. Ang data ng survey ay ipinapakita sa talahanayan.
|
Bilang ng napagmasdan |
Maximum na mid-expiratory flow rate, l/s |
||
|
Karaniwang lihis |
|||
|
Mga hindi naninigarilyo |
|||
|
magtrabaho sa isang lugar na hindi naninigarilyo | |||
|
magtrabaho sa isang silid na puno ng usok | |||
|
mga naninigarilyo |
|||
|
ang mga naninigarilyo ay hindi malaking numero mga sigarilyo | |||
|
average na bilang ng mga naninigarilyo | |||
|
paninigarilyo ng malaking bilang ng sigarilyo | |||
Mula sa talahanayan, hanapin ang 95% na agwat ng kumpiyansa para sa pangkalahatang mean at pangkalahatang pagkakaiba para sa bawat isa sa mga pangkat. Ano ang mga pagkakaiba sa pagitan ng mga pangkat? Ipakita ang mga resulta nang grapiko (25 puntos).
10. Tukuyin ang mga hangganan ng 95% at 99% na agwat ng kumpiyansa para sa pangkalahatang pagkakaiba-iba ng bilang ng mga biik sa 64 na farrowing, kung ang istatistikal na error ng sample na pagkakaiba s σ 2 = 8.25 (30 puntos).
11. Ito ay kilala na ang average na timbang ng mga kuneho ay 2.1 kg. Tukuyin ang mga hangganan ng 95% at 99% na agwat ng kumpiyansa para sa pangkalahatang mean at pagkakaiba kapag n= 30, σ = 0.56 kg (25 puntos).
12. Sa 100 tainga, sinukat ang nilalaman ng butil ng tainga ( X), haba ng spike ( Y) at ang masa ng butil sa tainga ( Z). Maghanap ng mga agwat ng kumpiyansa para sa pangkalahatang mean at pagkakaiba para sa P 1
= 0,95, P 2
= 0,99, P 3
= 0.999 kung
 = 19, = 6.766 cm, = 0.554 g; σ x 2 = 29.153, σ y 2 = 2.111, σ z 2 = 0.064. (25 puntos).
= 19, = 6.766 cm, = 0.554 g; σ x 2 = 29.153, σ y 2 = 2.111, σ z 2 = 0.064. (25 puntos).
13. Sa random na piniling 100 tainga ng winter wheat, ang bilang ng mga spikelet ay binilang. Ang sample set ay nailalarawan sa pamamagitan ng mga sumusunod na tagapagpahiwatig:
 = 15 spikelet at σ = 2.28 pcs. Tukuyin ang katumpakan kung saan nakuha ang average na resulta (
= 15 spikelet at σ = 2.28 pcs. Tukuyin ang katumpakan kung saan nakuha ang average na resulta (  ) at i-plot ang confidence interval para sa kabuuang mean at variance sa 95% at 99% na antas ng kabuluhan (30 puntos).
) at i-plot ang confidence interval para sa kabuuang mean at variance sa 95% at 99% na antas ng kabuluhan (30 puntos).
14. Ang bilang ng mga tadyang sa mga shell ng isang fossil mollusk Mga Orthambonite calligramma:
Ito ay kilala na n = 19, σ = 4.25. Tukuyin ang mga hangganan ng agwat ng kumpiyansa para sa pangkalahatang mean at pangkalahatang pagkakaiba sa antas ng kahalagahan W = 0.01 (25 puntos).
15. Upang matukoy ang mga ani ng gatas sa isang komersyal na dairy farm, ang produktibidad ng 15 baka ay tinutukoy araw-araw. Ayon sa datos para sa taon, ang bawat baka ay nagbibigay sa karaniwan ng sumusunod na dami ng gatas bawat araw (l): 22; 19; 25; dalawampu; 27; 17; tatlumpu; 21; labing-walo; 24; 26; 23; 25; dalawampu; 24. I-plot ang mga pagitan ng kumpiyansa para sa pangkalahatang pagkakaiba at ang ibig sabihin ng arithmetic. Maaari ba nating asahan na ang average na taunang ani ng gatas bawat baka ay 10,000 litro? (50 puntos).
16. Upang matukoy ang average na ani ng trigo para sa sakahan, ang paggapas ay isinasagawa sa mga sample plot na 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 at 2 ha. Ang ani (c/ha) mula sa mga plot ay 39.4; 38; 35.8; 40; 35; 42.7; 39.3; 41.6; 33; 42; 29 ayon sa pagkakabanggit. I-plot ang mga pagitan ng kumpiyansa para sa pangkalahatang pagkakaiba at ang ibig sabihin ng arithmetic. Posible bang asahan na ang average na ani para sa negosyong pang-agrikultura ay magiging 42 c/ha? (50 puntos).
Mga pagitan ng kumpiyansa.
Ang pagkalkula ng agwat ng kumpiyansa ay batay sa average na error ng kaukulang parameter. Agwat ng kumpiyansa ipinapakita sa loob ng kung anong mga limitasyon na may posibilidad (1-a) ang tunay na halaga ng tinantyang parameter. Narito ang antas ng kabuluhan, (1-a) ay tinatawag ding antas ng kumpiyansa.
Sa unang kabanata, ipinakita namin na, halimbawa, para sa arithmetic mean, ang totoong populasyon na ibig sabihin ay nasa loob ng 2 mean error ng mean tungkol sa 95% ng oras. Kaya, ang mga hangganan ng 95% na agwat ng kumpiyansa para sa mean ay magiging dalawang beses na mas malayo sa sample mean. karaniwang error karaniwan, i.e. pinaparami natin ang mean error ng mean sa ilang kadahilanan na depende sa antas ng kumpiyansa. Para sa mean at pagkakaiba ng mga mean, ang koepisyent ng Estudyante ay kinuha ( kritikal na halaga Kriterya ng mag-aaral), para sa bahagi at pagkakaiba ng mga pagbabahagi, ang kritikal na halaga ng z kriterya. Ang produkto ng koepisyent at ang average na error ay maaaring tawaging marginal error ng parameter na ito, i.e. ang maximum na makukuha natin kapag sinusuri ito.
Agwat ng kumpiyansa para sa ibig sabihin ng aritmetika : .
Narito ang sample mean;
Average na error ng arithmetic mean;
s- sample standard deviation;
n
f = n-1 (Koepisyent ng mag-aaral).
Agwat ng kumpiyansa para sa pagkakaiba ng arithmetic means :
Narito, ang pagkakaiba sa pagitan ng sample na paraan;
 - ang average na error ng pagkakaiba ng arithmetic means;
- ang average na error ng pagkakaiba ng arithmetic means;
s 1 , s 2 - sample ibig sabihin standard deviations;
n1,n2
Kritikal na halaga ng pamantayan ng Mag-aaral para sa isang naibigay na antas ng kahalagahan a at ang bilang ng mga antas ng kalayaan f=n1 +n2-2 (Koepisyent ng mag-aaral).
Agwat ng kumpiyansa para sa pagbabahagi :
![]() .
.
Narito d ang sample share;
– average na error sa pagbabahagi;
n– laki ng sample (laki ng pangkat);
Agwat ng kumpiyansa para sa magbahagi ng mga pagkakaiba :
Narito, ang pagkakaiba sa pagitan ng mga sample share;
 ay ang mean error ng pagkakaiba sa pagitan ng arithmetic means;
ay ang mean error ng pagkakaiba sa pagitan ng arithmetic means;
n1,n2– mga laki ng sample (bilang ng mga grupo);
Ang kritikal na halaga ng criterion z sa isang naibigay na antas ng kahalagahan a ( , , ).
Sa pamamagitan ng pagkalkula ng mga agwat ng kumpiyansa para sa pagkakaiba sa mga tagapagpahiwatig, kami, una, direktang nakikita ang mga posibleng halaga ng epekto, at hindi lamang ang pagtatantya ng punto nito. Pangalawa, maaari tayong gumawa ng konklusyon tungkol sa pagtanggap o pagtanggi sa null hypothesis at, pangatlo, maaari tayong gumawa ng konklusyon tungkol sa kapangyarihan ng criterion.
Kapag sinusuri ang mga hypotheses gamit ang mga agwat ng kumpiyansa, dapat sundin ang sumusunod na panuntunan:
Kung ang 100(1-a)-porsiyento na agwat ng kumpiyansa ng average na pagkakaiba ay hindi naglalaman ng zero, kung gayon ang mga pagkakaiba ay makabuluhan ayon sa istatistika sa antas ng kahalagahan; sa kabaligtaran, kung ang pagitan na ito ay naglalaman ng zero, kung gayon ang mga pagkakaiba ay hindi makabuluhan ayon sa istatistika.
Sa katunayan, kung ang agwat na ito ay naglalaman ng zero, kung gayon, nangangahulugan ito na ang inihambing na tagapagpahiwatig ay maaaring higit pa o mas kaunti sa isa sa mga pangkat kumpara sa isa pa, i.e. ang mga naobserbahang pagkakaiba ay random.
Sa pamamagitan ng lugar kung saan matatagpuan ang zero sa loob ng agwat ng kumpiyansa, maaaring hatulan ng isa ang kapangyarihan ng pamantayan. Kung ang zero ay malapit sa mas mababa o itaas na limitasyon ng agwat, kung gayon marahil sa mas malaking bilang ng mga pinaghahambing na pangkat, ang mga pagkakaiba ay aabot sa istatistikal na kahalagahan. Kung ang zero ay malapit sa gitna ng agwat, nangangahulugan ito na ang pagtaas at pagbaba ng tagapagpahiwatig sa pang-eksperimentong pangkat ay pantay na posibilidad, at, marahil, talagang walang mga pagkakaiba.
Mga halimbawa:
Upang ihambing ang operational lethality kapag gumagamit ng dalawang magkaibang uri ng anesthesia: 61 tao ang inoperahan gamit ang unang uri ng anesthesia, 8 ang namatay, gamit ang pangalawa - 67 tao, 10 ang namatay.
d 1 \u003d 8/61 \u003d 0.131; d 2 \u003d 10/67 \u003d 0.149; d1-d2 = - 0.018.
Ang pagkakaiba sa lethality ng mga inihambing na pamamaraan ay nasa hanay (-0.018 - 0.122; -0.018 + 0.122) o (-0.14; 0.104) na may posibilidad na 100(1-a) = 95%. Ang pagitan ay naglalaman ng zero, i.e. hypothesis tungkol sa parehong dami ng namamatay sa dalawa iba't ibang uri hindi maitatanggi ang anesthesia.
Kaya, ang dami ng namamatay ay maaari at bababa sa 14% at tataas sa 10.4% na may posibilidad na 95%, i.e. Ang zero ay humigit-kumulang sa gitna ng agwat, kaya maaari itong maitalo na, malamang, ang dalawang pamamaraan na ito ay talagang hindi naiiba sa kabagsikan.
Sa halimbawang isinasaalang-alang kanina, ang average na oras ng pag-tap ay inihambing sa apat na grupo ng mga mag-aaral na naiiba sa kanilang mga marka ng pagsusulit. Kalkulahin natin ang mga pagitan ng kumpiyansa ng average na oras ng pagpindot para sa mga mag-aaral na nakapasa sa pagsusulit para sa 2 at 5 at ang pagitan ng kumpiyansa para sa pagkakaiba sa pagitan ng mga average na ito.
Ang mga koepisyent ng mag-aaral ay matatagpuan mula sa mga talahanayan ng pamamahagi ng Mag-aaral (tingnan ang Apendise): para sa unang pangkat: = t(0.05;48) = 2.011; para sa pangalawang pangkat: = t(0.05;61) = 2.000. Kaya, ang mga pagitan ng kumpiyansa para sa unang pangkat: = (162.19-2.011 * 2.18; 162.19 + 2.011 * 2.18) = (157.8; 166.6) , para sa pangalawang pangkat (156.55- 2.000*1.88 ; 1.800*1.88 ; 157.8; 166.6) ; 160.3). Kaya, para sa mga nakapasa sa pagsusulit para sa 2, ang average na oras ng pagpindot ay mula 157.8 ms hanggang 166.6 ms na may posibilidad na 95%, para sa mga nakapasa sa pagsusulit para sa 5 - mula 152.8 ms hanggang 160.3 ms na may posibilidad na 95% .
Maaari mo ring subukan ang null hypothesis gamit ang mga agwat ng kumpiyansa para sa mga paraan, at hindi lamang para sa pagkakaiba sa mga paraan. Halimbawa, tulad ng sa aming kaso, kung ang mga agwat ng kumpiyansa para sa mga paraan ay magkakapatong, kung gayon ang null hypothesis ay hindi maaaring tanggihan. Upang tanggihan ang isang hypothesis sa isang napiling antas ng kahalagahan, ang kaukulang mga pagitan ng kumpiyansa ay hindi dapat mag-overlap.
Hanapin natin ang confidence interval para sa pagkakaiba sa average na oras ng pagpindot sa mga pangkat na nakapasa sa pagsusulit para sa 2 at 5. Ang pagkakaiba sa mga average: 162.19 - 156.55 = 5.64. Koepisyent ng mag-aaral: \u003d t (0.05; 49 + 62-2) \u003d t (0.05; 109) \u003d 1.982. Ang mga karaniwang paglihis ng pangkat ay magiging katumbas ng: ; . Kinakalkula namin ang average na error ng pagkakaiba sa pagitan ng mga paraan: . Agwat ng kumpiyansa: \u003d (5.64-1.982 * 2.87; 5.64 + 1.982 * 2.87) \u003d (-0.044; 11.33).
Kaya, ang pagkakaiba sa average na oras ng pagpindot sa mga pangkat na nakapasa sa pagsusulit sa 2 at sa 5 ay nasa hanay mula -0.044 ms hanggang 11.33 ms. Kasama sa agwat na ito ang zero, i.e. ang average na oras ng pagpindot para sa mga nakapasa sa pagsusulit na may mahusay na mga resulta ay maaaring parehong tumaas at bumaba kumpara sa mga nakapasa sa pagsusulit nang hindi kasiya-siya, i.e. ang null hypothesis ay hindi maaaring tanggihan. Ngunit ang zero ay napakalapit sa mas mababang limitasyon, ang oras ng pagpindot ay mas malamang na bumaba para sa mahusay na mga pumasa. Kaya, maaari naming tapusin na may mga pagkakaiba pa rin sa average na oras ng pag-click sa pagitan ng mga nakapasa ng 2 at 5, hindi lang namin sila matukoy para sa isang partikular na pagbabago sa average na oras, ang pagkalat ng average na oras at mga laki ng sample.
Ang kapangyarihan ng pagsubok ay ang posibilidad na tanggihan ang isang maling null hypothesis, i.e. hanapin ang mga pagkakaiba kung nasaan talaga sila.
Ang kapangyarihan ng pagsubok ay tinutukoy batay sa antas ng kahalagahan, ang laki ng mga pagkakaiba sa pagitan ng mga grupo, ang pagkalat ng mga halaga sa mga grupo, at ang laki ng sample.
Para sa t-test ng Mag-aaral at pagsusuri ng pagkakaiba-iba maaari kang gumamit ng mga sensitivity chart.
Ang kapangyarihan ng criterion ay maaaring gamitin sa paunang pagpapasiya ng kinakailangang bilang ng mga grupo.
Ang agwat ng kumpiyansa ay nagpapakita sa loob ng kung ano ang naglilimita sa tunay na halaga ng tinantyang parameter ay nakasalalay sa isang ibinigay na posibilidad.
Sa tulong ng mga agwat ng kumpiyansa, maaari mong subukan ang mga istatistikal na hypotheses at gumawa ng mga konklusyon tungkol sa pagiging sensitibo ng mga pamantayan.
PANITIKAN.
Glantz S. - Kabanata 6.7.
Rebrova O.Yu. - p.112-114, p.171-173, p.234-238.
Sidorenko E. V. - pp. 32-33.
Mga tanong para sa pagsusuri sa sarili ng mga mag-aaral.
1. Ano ang kapangyarihan ng pamantayan?
2. Sa anong mga kaso kinakailangan na suriin ang kapangyarihan ng pamantayan?
3. Mga paraan para sa pagkalkula ng kapangyarihan.
6. Paano subukan ang isang istatistikal na hypothesis gamit ang isang agwat ng kumpiyansa?
7. Ano ang masasabi tungkol sa kapangyarihan ng criterion kapag kinakalkula ang agwat ng kumpiyansa?
Mga gawain.
Mga pagitan ng kumpiyansa ( Ingles Mga Pagitan ng Kumpiyansa) isa sa mga uri ng mga pagtatantya ng pagitan na ginagamit sa mga istatistika, na kinakalkula para sa isang partikular na antas ng kahalagahan. Pinapayagan nila ang assertion na ang tunay na halaga ng isang hindi kilalang istatistikal na parameter populasyon ay nasa nakuha na hanay ng mga halaga na may posibilidad na tinukoy ng napiling antas ng istatistikal na kahalagahan.
Normal na pamamahagi
Kapag ang pagkakaiba (σ 2 ) ng populasyon ng data ay kilala, ang isang z-score ay maaaring gamitin upang kalkulahin ang mga limitasyon ng kumpiyansa (mga boundary point ng confidence interval). Kung ikukumpara sa paggamit ng t-distribution, ang paggamit ng z-score ay hindi lamang bubuo ng mas makitid na agwat ng kumpiyansa, ngunit magbibigay din ng mas maaasahang mga pagtatantya. inaasahan sa matematika at standard deviation (σ), dahil ang Z-score ay batay sa isang normal na distribusyon.
Formula
Upang matukoy ang mga boundary point ng confidence interval, sa kondisyon na ang standard deviation ng populasyon ng data ay kilala, ang sumusunod na formula ay ginagamit
| L = X - Z α/2 | σ |
| √n |
Halimbawa
Ipagpalagay na ang sample size ay 25 observation, ang sample mean ay 15, at ang population standard deviation ay 8. Para sa significance level na α=5%, ang Z-score ay Z α/2 =1.96. Sa kasong ito, magiging mas mababa at itaas na limitasyon ng agwat ng kumpiyansa
| L = 15 - 1.96 | 8 | = 11,864 |
| √25 |
| L = 15 + 1.96 | 8 | = 18,136 |
| √25 |
Kaya, maaari nating sabihin na may posibilidad na 95% ang inaasahan ng matematika ng pangkalahatang populasyon ay mahuhulog sa hanay mula 11.864 hanggang 18.136.
Mga pamamaraan para sa pagpapaliit ng agwat ng kumpiyansa
Sabihin nating masyadong malawak ang saklaw para sa mga layunin ng ating pag-aaral. Mayroong dalawang paraan upang bawasan ang hanay ng agwat ng kumpiyansa.
- Bawasan ang antas ng istatistikal na kahalagahan α.
- Dagdagan ang laki ng sample.
Ang pagbabawas ng antas ng istatistikal na kahalagahan sa α=10%, makakakuha tayo ng Z-score na katumbas ng Z α/2 =1.64. Sa kasong ito, ang mas mababa at itaas na mga limitasyon ng pagitan ay magiging
| L = 15 - 1.64 | 8 | = 12,376 |
| √25 |
| L = 15 + 1.64 | 8 | = 17,624 |
| √25 |
At ang agwat ng kumpiyansa mismo ay maaaring isulat bilang
Sa kasong ito, maaari nating ipagpalagay na sa isang probabilidad na 90%, ang mathematical na inaasahan ng pangkalahatang populasyon ay mahuhulog sa hanay.
Kung gusto nating panatilihin ang antas ng istatistikal na kahalagahan α, kung gayon ang tanging alternatibo ay dagdagan ang laki ng sample. Ang pagtaas nito sa 144 na mga obserbasyon, nakuha namin ang mga sumusunod na halaga ng mga limitasyon ng kumpiyansa
| L = 15 - 1.96 | 8 | = 13,693 |
| √144 |
| L = 15 + 1.96 | 8 | = 16,307 |
| √144 |
Ang agwat ng kumpiyansa mismo ay magiging ganito:
Kaya, ang pagpapaliit ng agwat ng kumpiyansa nang hindi binabawasan ang antas ng istatistikal na kahalagahan ay posible lamang sa pamamagitan ng pagtaas ng laki ng sample. Kung hindi posible na dagdagan ang laki ng sample, kung gayon ang pagpapaliit ng agwat ng kumpiyansa ay maaaring makamit lamang sa pamamagitan ng pagbabawas ng antas ng istatistikal na kahalagahan.
Bumuo ng agwat ng kumpiyansa para sa isang hindi normal na pamamahagi
Kung karaniwang lihis hindi kilala ang populasyon o ang distribusyon ay hindi normal, ang t-distribution ay ginagamit upang bumuo ng isang confidence interval. Ang diskarteng ito ay mas konserbatibo, na ipinahayag sa mas malawak na mga agwat ng kumpiyansa, kumpara sa pamamaraan batay sa Z-score.
Formula
Ang mga sumusunod na formula ay ginagamit upang kalkulahin ang mas mababa at itaas na mga limitasyon ng agwat ng kumpiyansa batay sa t-distribution
| L = X - tα | σ |
| √n |
Ang pamamahagi ng mag-aaral o t-distribution ay nakasalalay lamang sa isang parameter - ang bilang ng mga antas ng kalayaan, na katumbas ng bilang ng mga indibidwal na halaga ng tampok (ang bilang ng mga obserbasyon sa sample). Ang halaga ng t-test ng Mag-aaral para sa isang naibigay na bilang ng mga antas ng kalayaan (n) at ang antas ng istatistikal na kahalagahan α ay makikita sa mga talahanayan ng paghahanap.
Halimbawa
Ipagpalagay na ang sample size ay 25 indibidwal na value, ang mean value ng sample ay 50, at ang standard deviation ng sample ay 28. Kailangan mong bumuo ng confidence interval para sa antas ng statistical significance α=5%.
Sa aming kaso, ang bilang ng mga antas ng kalayaan ay 24 (25-1), samakatuwid, ang katumbas na halaga ng tabular ng t-test ng Mag-aaral para sa antas ng istatistikal na kahalagahan α=5% ay 2.064. Samakatuwid, ang ibaba at itaas na mga hangganan ng pagitan ng kumpiyansa ay magiging
| L = 50 - 2.064 | 28 | = 38,442 |
| √25 |
| L = 50 + 2.064 | 28 | = 61,558 |
| √25 |
At ang agwat mismo ay maaaring isulat bilang
Kaya, maaari nating sabihin na may posibilidad na 95% ang mathematical na inaasahan ng pangkalahatang populasyon ay nasa hanay.
Ang paggamit ng t-distribution ay nagpapahintulot sa iyo na paliitin ang agwat ng kumpiyansa, alinman sa pamamagitan ng pagbabawas ng istatistikal na kahalagahan o sa pamamagitan ng pagtaas ng laki ng sample.
Ang pagbabawas ng istatistikal na kahalagahan mula 95% hanggang 90% sa mga kundisyon ng aming halimbawa, nakukuha namin ang katumbas na halaga ng tabular ng t-test ng Mag-aaral na 1.711.
| L = 50 - 1.711 | 28 | = 40,418 |
| √25 |
| L = 50 + 1.711 | 28 | = 59,582 |
| √25 |
Sa kasong ito, maaari nating sabihin na may posibilidad na 90% ang inaasahan ng matematika ng pangkalahatang populasyon ay nasa saklaw.
Kung ayaw nating bawasan ang istatistikal na kahalagahan, kung gayon ang tanging alternatibo ay dagdagan ang laki ng sample. Sabihin natin na ito ay 64 indibidwal na obserbasyon, at hindi 25 gaya ng sa orihinal na kondisyon halimbawa. Ang tabular value ng Student's t-test para sa 63 degrees of freedom (64-1) at ang antas ng statistical significance α=5% ay 1.998.
| L = 50 - 1.998 | 28 | = 43,007 |
| √64 |
| L = 50 + 1.998 | 28 | = 56,993 |
| √64 |
Nagbibigay ito sa amin ng pagkakataong igiit na may posibilidad na 95% ang mathematical na inaasahan ng pangkalahatang populasyon ay nasa hanay.
Malaking Sample
Ang mga malalaking sample ay mga sample mula sa pangkalahatang populasyon ng data, ang bilang ng mga indibidwal na obserbasyon kung saan lumampas sa 100. Istatistikong Pananaliksik ay nagpakita na ang mas malalaking sample ay karaniwang naipamahagi, kahit na ang distribusyon ng populasyon ay hindi normal. Bilang karagdagan, para sa mga naturang sample, ang paggamit ng z-score at t-distribution ay nagbibigay ng humigit-kumulang sa parehong mga resulta kapag gumagawa ng mga pagitan ng kumpiyansa. Kaya, para sa malalaking sample, katanggap-tanggap na gumamit ng z-score para sa isang normal na distribusyon sa halip na isang t-distribution.
Summing up
Agwat ng kumpiyansa
Agwat ng kumpiyansa- isang terminong ginamit sa mathematical statistics para sa interval (kumpara sa point) na pagtatantya ng mga parameter na istatistika, na mas mainam na may maliit na sample size. Ang agwat ng kumpiyansa ay ang agwat na sumasaklaw sa hindi kilalang parameter na may ibinigay na pagiging maaasahan.
Ang paraan ng mga pagitan ng kumpiyansa ay binuo ng Amerikanong istatistika na si Jerzy Neumann, batay sa mga ideya ng Ingles na istatistika na si Ronald Fischer.
Kahulugan
Parameter ng agwat ng kumpiyansa θ random variable distribution X may trust level 100 p%, na nabuo ng sample ( x 1 ,…,x n), ay tinatawag na isang pagitan na may mga hangganan ( x 1 ,…,x n) at ( x 1 ,…,x n) na mga pagsasakatuparan ng mga random na variable L(X 1 ,…,X n) at U(X 1 ,…,X n) ganyan
.Tinatawag ang mga boundary point ng confidence interval mga limitasyon ng kumpiyansa.
Ang interpretasyong batay sa intuwisyon ng agwat ng kumpiyansa ay: kung p ay malaki (sabihin nating 0.95 o 0.99), kung gayon ang agwat ng kumpiyansa ay halos tiyak na naglalaman ng tunay na halaga θ .
Isa pang interpretasyon ng konsepto ng isang agwat ng kumpiyansa: maaari itong ituring bilang isang pagitan ng mga halaga ng parameter θ tugma sa pang-eksperimentong data at hindi sumasalungat sa mga ito.
Mga halimbawa
- Agwat ng kumpiyansa para sa mathematical na inaasahan ng isang normal na sample;
- Agwat ng kumpiyansa para sa normal na pagkakaiba-iba ng sample.
Bayesian Confidence Interval
Sa mga istatistika ng Bayesian, mayroong isang kahulugan ng isang agwat ng kumpiyansa na magkatulad ngunit naiiba sa ilang mahahalagang detalye. Dito, ang tinantyang parameter mismo ay itinuturing na isang random na variable na may ilan na binigyan ng priori distribution (uniporme sa pinakasimpleng kaso), at ang sample ay naayos (sa mga klasikal na istatistika, lahat ay eksaktong kabaligtaran). Ang Bayesian-confidence interval ay ang agwat na sumasaklaw sa value ng parameter na may posterior probability:
.Sa pangkalahatan, magkaiba ang mga agwat ng kumpiyansa ng klasikal at Bayesian. Sa panitikan sa wikang Ingles, ang Bayesian confidence interval ay karaniwang tinatawag na termino mapagkakatiwalaang pagitan, at ang classic agwat ng kumpiyansa.
Mga Tala
Mga pinagmumulanWikimedia Foundation. 2010 .
- Baby (pelikula)
- Kolonista
Tingnan kung ano ang "Confidence Interval" sa ibang mga diksyunaryo:
Agwat ng kumpiyansa- ang agwat na kinakalkula mula sa sample na data, na may ibinigay na posibilidad (kumpiyansa) ay sumasaklaw sa hindi alam na totoong halaga ng tinantyang parameter ng pamamahagi. Pinagmulan: GOST 20522 96: Mga Lupa. Mga paraan ng pagpoproseso ng istatistika ng mga resulta ... Dictionary-reference na aklat ng mga tuntunin ng normatibo at teknikal na dokumentasyon
agwat ng kumpiyansa- para sa isang scalar parameter ng pangkalahatang populasyon, ito ay isang segment na malamang na naglalaman ng parameter na ito. Ang pariralang ito ay walang kahulugan nang walang karagdagang paglilinaw. Dahil ang mga hangganan ng agwat ng kumpiyansa ay tinatantya mula sa sample, natural na ... ... Diksyunaryo ng Sociological Statistics
PAGTITIWALA NG PAGTITIWALA ay isang paraan ng pagtatantya ng parameter na naiiba sa pagtatantya ng punto. Hayaang magbigay ng sample x1, . . ., xn mula sa isang distribusyon na may probability density f(x, α), at a*=a*(x1, . . ., xn) ay ang pagtatantya na α, g(a*, α) ay ang probability density ng tantiyahin. Naghahanap ng…… Geological Encyclopedia
PAGTITIWALA NG PAGTITIWALA- (confidence interval) Ang agwat kung saan ang kumpiyansa ng isang parameter value para sa isang populasyon na hinango mula sa isang sample na survey ay may isang tiyak na antas ng posibilidad, gaya ng 95%, dahil sa mismong sample. Lapad…… Diksyonaryo ng ekonomiya
agwat ng kumpiyansa- ay ang pagitan kung saan matatagpuan ang tunay na halaga ng natukoy na dami na may ibinigay na probabilidad ng kumpiyansa. Pangkalahatang kimika: aklat-aralin / A. V. Zholnin ... Mga terminong kemikal
Agwat ng kumpiyansa CI- Confidence interval, CI * davyaralny interval, CI * confidence interval interval ng sign value, na kinakalkula para sa c.l. parameter ng pamamahagi (hal. ang ibig sabihin ng halaga ng isang tampok) sa sample at may tiyak na posibilidad (hal. 95% para sa 95% ... Genetics. encyclopedic Dictionary
PAGTITIWALA NG PAGTITIWALA- ang konsepto na lumitaw kapag tinatantya ang parameter statistich. pamamahagi ayon sa pagitan ng mga halaga. D. i. para sa parameter q na tumutugma sa ibinigay na koepisyent. kumpiyansa P, ay katumbas ng ganoong pagitan (q1, q2) na para sa anumang pamamahagi ng posibilidad ng hindi pagkakapantay-pantay ... ... Pisikal na Encyclopedia
agwat ng kumpiyansa- - Mga paksa sa telekomunikasyon, mga pangunahing konsepto EN agwat ng kumpiyansa ... Handbook ng Teknikal na Tagasalin
agwat ng kumpiyansa- pasikliovimo intervalas statusas T sritis Standartizacija ir metrologija apibrėžtis Dydžio verčių intervalas, kuriame su pasirinktąja tikimybe yra matavimo rezultato vertė. atitikmenys: engl. confidence interval vok. Vertrauensbereich, m rus.… … Penkiakalbis aiskinamasis metrologijos terminų žodynas
agwat ng kumpiyansa- pasikliovimo intervalas statusas T sritis chemija apibrėžtis Dydžio verčių intervalas, kuriame su pasirinktąja tikimybe yra matavimo rezultatų vertė. atitikmenys: engl. confidence interval rus. lugar ng pagtitiwala; agwat ng kumpiyansa... Chemijos terminų aiskinamasis žodynas
Sa mga istatistika, mayroong dalawang uri ng mga pagtatantya: punto at pagitan. Pagtataya ng Punto ay isang solong sample na istatistika na ginagamit upang tantyahin ang isang parameter ng populasyon. Halimbawa, ang ibig sabihin ng sample ay isang puntong pagtatantya ng ibig sabihin ng populasyon, at ang sample na pagkakaiba-iba S2- punto ng pagtatantya ng pagkakaiba-iba ng populasyon σ2. ipinakita na ang sample mean ay isang walang pinapanigan na pagtatantya ng inaasahan ng populasyon. Ang sample mean ay tinatawag na walang pinapanigan dahil ang ibig sabihin ng lahat ng sample ay (na may parehong laki ng sample n) ay katumbas ng mathematical na inaasahan ng pangkalahatang populasyon.
Upang ang sample na pagkakaiba-iba S2 naging walang pinapanigan na estimator ng pagkakaiba-iba ng populasyon σ2, ang denominator ng sample na variance ay dapat itakda na katumbas ng n – 1 , ngunit hindi n. Sa madaling salita, ang pagkakaiba-iba ng populasyon ay ang average ng lahat ng posibleng pagkakaiba-iba ng sample.
Kapag tinatantya ang mga parameter ng populasyon, dapat tandaan na ang mga sample na istatistika tulad ng , depende sa mga partikular na sample. Upang isaalang-alang ang katotohanang ito, upang makuha pagtatantya ng pagitan ang matematikal na inaasahan ng pangkalahatang populasyon ay sinusuri ang pamamahagi ng sample na paraan (para sa higit pang mga detalye, tingnan). Ang itinayong agwat ay nailalarawan sa pamamagitan ng isang tiyak na antas ng kumpiyansa, na kung saan ay ang posibilidad na ang tunay na parameter ng pangkalahatang populasyon ay natantiya nang tama. Maaaring gamitin ang mga katulad na agwat ng kumpiyansa upang tantiyahin ang proporsyon ng isang feature R at ang pangunahing ibinahagi na masa ng pangkalahatang populasyon.
Mag-download ng tala sa o format, mga halimbawa sa format
Pagbuo ng isang agwat ng kumpiyansa para sa mathematical na inaasahan ng pangkalahatang populasyon na may kilalang standard deviation
Pagbuo ng isang agwat ng kumpiyansa para sa proporsyon ng isang katangian sa pangkalahatang populasyon
Sa seksyong ito, ang konsepto ng isang agwat ng kumpiyansa ay pinalawak sa kategoryang data. Ito ay nagpapahintulot sa iyo na tantyahin ang bahagi ng katangian sa pangkalahatang populasyon R na may sample share RS= X/n. Tulad ng nabanggit, kung ang mga halaga nR at n(1 - p) lumampas sa numero 5, ang binomial distribution ay maaaring tantiyahin ng normal. Samakatuwid, upang tantyahin ang bahagi ng isang katangian sa pangkalahatang populasyon R posible na bumuo ng isang pagitan na ang antas ng kumpiyansa ay katumbas ng (1 - α)x100%.

saan pS- sample na bahagi ng tampok, katumbas ng X/n, ibig sabihin. ang bilang ng mga tagumpay na hinati sa laki ng sample, R- ang bahagi ng katangian sa pangkalahatang populasyon, Z ay ang kritikal na halaga ng standardized normal distribution, n- laki ng sample.
Halimbawa 3 Ipagpalagay natin na ang isang sample ay kinuha mula sa sistema ng impormasyon, na binubuo ng 100 mga invoice na nakumpleto noong nakaraang buwan. Sabihin nating mali ang 10 sa mga invoice na ito. Sa ganitong paraan, R= 10/100 = 0.1. Ang 95% na antas ng kumpiyansa ay tumutugma sa kritikal na halaga Z = 1.96.
Kaya, mayroong 95% na pagkakataon na sa pagitan ng 4.12% at 15.88% ng mga invoice ay naglalaman ng mga error.
Para sa isang ibinigay na laki ng sample, ang agwat ng kumpiyansa na naglalaman ng proporsyon ng katangian sa populasyon ay tila mas malawak kaysa sa isang tuluy-tuloy na random variable. Ito ay dahil ang mga sukat ng isang tuluy-tuloy na random na variable ay naglalaman ng mas maraming impormasyon kaysa sa mga sukat ng pang-kategoryang data. Sa madaling salita, ang kategoryang data na kumukuha lamang ng dalawang halaga ay naglalaman ng hindi sapat na impormasyon upang matantya ang mga parameter ng kanilang pamamahagi.
ATpagkalkula ng mga pagtatantya na nakuha mula sa isang may hangganang populasyon
Pagtataya ng inaasahan sa matematika. Salik ng pagwawasto para sa panghuling populasyon ( fpc) ay ginamit upang mabawasan karaniwang error sa oras. Kapag kinakalkula ang mga agwat ng kumpiyansa para sa mga pagtatantya ng parameter ng populasyon, inilalapat ang isang salik sa pagwawasto sa mga sitwasyon kung saan kinukuha ang mga sample nang walang kapalit. Kaya, ang pagitan ng kumpiyansa para sa inaasahan sa matematika, pagkakaroon ng antas ng kumpiyansa na katumbas ng (1 - α)x100%, ay kinakalkula ng formula:

Halimbawa 4 Upang ilarawan ang aplikasyon ng correction factor para sa isang limitadong populasyon, bumalik tayo sa problema ng pagkalkula ng confidence interval para sa average na halaga ng mga invoice na tinalakay sa Halimbawa 3 sa itaas. Ipagpalagay na ang isang kumpanya ay nag-isyu ng 5,000 invoice bawat buwan, at Xᅳ=110.27 USD, S= $28.95 N = 5000, n = 100, α = 0.05, t99 = 1.9842. Ayon sa formula (6) nakukuha natin:
Pagtatantya ng bahagi ng tampok. Kapag pumipili ng walang pagbabalik, ang agwat ng kumpiyansa para sa proporsyon ng tampok na may antas ng kumpiyansa na katumbas ng (1 - α)x100%, ay kinakalkula ng formula:

Mga agwat ng kumpiyansa at mga isyu sa etika
Kapag nagsa-sample ng isang populasyon at bumubuo ng mga istatistikal na inferences, madalas na lumitaw ang mga problema sa etika. Ang pangunahing isa ay kung paano nagkakasundo ang mga agwat ng kumpiyansa at mga pagtatantya ng punto ng mga sample na istatistika. Ang mga pagtatantya sa punto ng pag-publish nang hindi tinutukoy ang mga naaangkop na agwat ng kumpiyansa (karaniwan ay nasa 95% na antas ng kumpiyansa) at ang laki ng sample kung saan nagmula ang mga ito ay maaaring mapanlinlang. Ito ay maaaring magbigay sa user ng impresyon na ang pagtatantya ng punto ay eksaktong kailangan niya upang mahulaan ang mga katangian ng buong populasyon. Kaya, kinakailangang maunawaan na sa anumang pananaliksik, hindi punto, ngunit ang mga pagtatantya ng pagitan ay dapat ilagay sa unahan. Bilang karagdagan, ang espesyal na pansin ay dapat bayaran sa tamang pagpili ng mga laki ng sample.
Kadalasan, ang mga bagay ng statistical manipulations ay ang mga resulta opinyon botohan mga tao sa ilang mga isyung pampulitika. Kasabay nito, ang mga resulta ng survey ay inilalagay sa mga front page ng mga pahayagan, at ang error sample na pag-aaral at metodolohiya pagsusuri sa istatistika i-print sa isang lugar sa gitna. Upang patunayan ang bisa ng nakuha na mga pagtatantya ng punto, kinakailangang ipahiwatig ang laki ng sample batay sa kung saan nakuha ang mga ito, ang mga hangganan ng agwat ng kumpiyansa at antas ng kahalagahan nito.
Susunod na tala
Mga materyales mula sa aklat na Levin et al. Ginagamit ang mga istatistika para sa mga tagapamahala. - M.: Williams, 2004. - p. 448–462
Central limit theorem nagsasaad na para sa isang sapat na malaking sukat ng sample, ang sample na pamamahagi ng mga paraan ay maaaring tantiyahin sa pamamagitan ng isang normal na distribusyon. Ang ari-arian na ito ay hindi nakadepende sa uri ng pamamahagi ng populasyon.



