Eigenvalues at matrix vectors. Eigenvectors at eigenvalues ng isang linear operator
Ang eigenvector ng isang square matrix ay isa na, kapag pinarami ng isang ibinigay na matrix, ay nagreresulta sa isang collinear vector. Sa simpleng salita, kapag ang isang matrix ay pinarami ng eigenvector, ang huli ay nananatiling pareho, ngunit pinarami ng ilang numero.
Kahulugan
Ang eigenvector ay isang non-zero vector V, na, kapag pinarami ng isang square matrix M, ay nagiging sarili nito, na nadagdagan ng ilang bilang na λ. Sa algebraic notation, ganito ang hitsura:
M × V = λ × V,
kung saan ang λ ay isang eigenvalue ng matrix M.
Isaalang-alang natin ang isang numerical na halimbawa. Para sa kaginhawaan ng pagsulat, ang mga numero sa matrix ay paghiwalayin ng isang semicolon. Sabihin nating mayroon tayong matrix:
- M = 0; 4;
- 6; 10.
I-multiply natin ito sa isang column vector:
- V = -2;
Kapag nagpaparami ng matrix sa isang column vector, nakakakuha din tayo ng column vector. Sa mahigpit na wikang matematika, ang formula para sa pagpaparami ng 2 × 2 matrix sa isang column vector ay magiging ganito:
- M × V = M11 × V11 + M12 × V21;
- M21 x V11 + M22 x V21.
Ang ibig sabihin ng M11 ay ang elemento ng matrix M, na nakatayo sa unang hilera at unang hanay, at M22 - ang elementong matatagpuan sa pangalawang hilera at pangalawang hanay. Para sa aming matrix, ang mga elementong ito ay M11 = 0, M12 = 4, M21 = 6, M22 10. Para sa isang column vector, ang mga halagang ito ay V11 = –2, V21 = 1. Ayon sa formula na ito, nakukuha namin ang sumusunod resulta ng produkto ng isang square matrix ng isang vector:
- M × V = 0 × (-2) + (4) × (1) = 4;
- 6 × (-2) + 10 × (1) = -2.
Para sa kaginhawahan, isinusulat namin ang column vector sa isang hilera. Kaya, pinarami namin ang square matrix sa vector (-2; 1), na nagreresulta sa vector (4; -2). Malinaw, ito ay ang parehong vector na pinarami ng λ = -2. Ang Lambda sa kasong ito ay nagsasaad ng eigenvalue ng matrix.
Ang eigenvector ng isang matrix ay isang collinear vector, iyon ay, isang bagay na hindi nagbabago ng posisyon nito sa espasyo kapag ito ay pinarami ng isang matrix. Ang konsepto ng collinearity sa vector algebra ay katulad ng term ng parallelism sa geometry. Sa geometric na interpretasyon, ang mga collinear vector ay mga parallel na nakadirekta na mga segment na may iba't ibang haba. Mula noong panahon ng Euclid, alam natin na ang isang linya ay may walang katapusang bilang ng mga linya na kahanay nito, kaya lohikal na ipagpalagay na ang bawat matrix ay may walang katapusang bilang ng eigenvectors.
Mula sa nakaraang halimbawa, makikita na ang parehong (-8; 4), at (16; -8), at (32, -16) ay maaaring eigenvectors. Ang lahat ng ito ay mga collinear vector na tumutugma sa eigenvalue λ = -2. Kapag pina-multiply ang orihinal na matrix ng mga vector na ito, makakakuha pa rin tayo ng isang vector bilang resulta, na naiiba sa orihinal ng 2 beses. Iyon ang dahilan kung bakit, kapag nilulutas ang mga problema para sa paghahanap ng isang eigenvector, kinakailangan na maghanap lamang ng mga linearly independent na vector object. Kadalasan, para sa isang n × n matrix, mayroong n-th na bilang ng mga eigenvector. Ang aming calculator ay idinisenyo para sa pagsusuri ng mga second-order na square matrice, kaya halos palaging dalawang eigenvector ang makikita bilang isang resulta, maliban kung sila ay nag-tutugma.
Sa halimbawa sa itaas, alam namin nang maaga ang eigenvector ng orihinal na matrix at biswal na natukoy ang numero ng lambda. Gayunpaman, sa pagsasagawa, ang lahat ay nangyayari sa kabaligtaran: sa simula ay mayroon eigenvalues at pagkatapos lamang ang eigenvectors.
Algoritmo ng solusyon
Tingnan natin muli ang orihinal na matrix M at subukang hanapin ang parehong eigenvectors nito. Kaya ang matrix ay ganito ang hitsura:
- M = 0; 4;
- 6; 10.
Upang magsimula, kailangan nating matukoy ang eigenvalue λ, kung saan kailangan nating kalkulahin ang determinant ng sumusunod na matrix:
- (0 − λ); 4;
- 6; (10 − λ).
Ang matrix na ito nakuha sa pamamagitan ng pagbabawas ng hindi kilalang λ mula sa mga elemento sa pangunahing dayagonal. Ang determinant ay tinutukoy ng karaniwang formula:
- detA = M11 × M21 − M12 × M22
- detA = (0 − λ) × (10 − λ) − 24
Dahil ang aming vector ay hindi dapat maging zero, kinuha namin ang nagresultang equation bilang linearly dependent at itinutumbas ang aming determinant detA sa zero.
(0 − λ) × (10 − λ) − 24 = 0
Buksan natin ang mga bracket at kunin ang katangian na equation ng matrix:
λ 2 − 10λ − 24 = 0
Ito ay pamantayan quadratic equation, na dapat lutasin sa mga tuntunin ng discriminant.
D \u003d b 2 - 4ac \u003d (-10) × 2 - 4 × (-1) × 24 \u003d 100 + 96 \u003d 196
Ang ugat ng discriminant ay sqrt(D) = 14, kaya λ1 = -2, λ2 = 12. Ngayon para sa bawat lambda value, kailangan nating maghanap ng eigenvector. Ipahayag natin ang mga coefficient ng system para sa λ = -2.
- M − λ × E = 2; 4;
- 6; 12.
Sa formula na ito, ang E ay ang identity matrix. Batay sa nakuha na matrix, bubuuin namin ang system linear na equation:
2x + 4y = 6x + 12y
kung saan ang x at y ay mga elemento ng eigenvector.
Kolektahin natin ang lahat ng X sa kaliwa at lahat ng Y sa kanan. Malinaw - 4x = 8y. Hatiin ang expression sa - 4 at makuha ang x = -2y. Ngayon ay matutukoy natin ang unang eigenvector ng matrix sa pamamagitan ng pagkuha ng anumang mga halaga ng mga hindi alam (tandaan ang tungkol sa infinity ng linearly dependent eigenvectors). Kunin natin ang y = 1, pagkatapos ay x = -2. Samakatuwid, ang unang eigenvector ay mukhang V1 = (–2; 1). Bumalik sa simula ng artikulo. Ito ang vector object na pinarami namin ang matrix upang ipakita ang konsepto ng isang eigenvector.
Ngayon hanapin natin ang eigenvector para sa λ = 12.
- M - λ × E = -12; 4
- 6; -2.
Bumuo tayo ng parehong sistema ng mga linear na equation;
- -12x + 4y = 6x − 2y
- -18x = -6y
- 3x=y.
Ngayon kunin natin ang x = 1, kaya y = 3. Kaya, ang pangalawang eigenvector ay parang V2 = (1; 3). Kapag pinarami ang orihinal na matrix sa pamamagitan ng binigay na vector, ang resulta ay palaging magiging parehong vector na pinarami ng 12. Kinukumpleto nito ang algorithm ng solusyon. Ngayon alam mo na kung paano manu-manong tukuyin ang isang eigenvector ng isang matrix.
- determinant;
- bakas, iyon ay, ang kabuuan ng mga elemento sa pangunahing dayagonal;
- ranggo, ibig sabihin, ang maximum na bilang ng mga linearly independent na row/column.
Gumagana ang programa ayon sa algorithm sa itaas, pinaliit ang proseso ng solusyon. Mahalagang ituro na sa programa ang lambda ay tinutukoy ng titik na "c". Tingnan natin ang isang numerical na halimbawa.
Halimbawa ng programa
Subukan nating tukuyin ang mga eigenvector para sa sumusunod na matrix:
- M=5; 13;
- 4; 14.
Ipasok natin ang mga halagang ito sa mga cell ng calculator at makuha ang sagot sa sumusunod na form:
- Ranggo ng matrix: 2;
- Matrix determinant: 18;
- Bakas ng matris: 19;
- Pagkalkula ng Eigenvector: c 2 − 19.00c + 18.00 (characteristic equation);
- Pagkalkula ng Eigenvector: 18 (unang halaga ng lambda);
- Pagkalkula ng Eigenvector: 1 (pangalawang halaga ng lambda);
- Sistema ng mga equation ng vector 1: -13x1 + 13y1 = 4x1 − 4y1;
- Vector 2 equation system: 4x1 + 13y1 = 4x1 + 13y1;
- Eigenvector 1: (1; 1);
- Eigenvector 2: (-3.25; 1).
Kaya, nakakuha kami ng dalawang linearly independent eigenvectors.
Konklusyon
Ang linear algebra at analytic geometry ay mga karaniwang paksa para sa sinumang freshman sa engineering. Malaking bilang ng ang mga vector at matrice ay nakakatakot, at madaling magkamali sa gayong masalimuot na mga kalkulasyon. Ang aming programa ay magbibigay-daan sa mga mag-aaral na suriin ang kanilang mga kalkulasyon o awtomatikong lutasin ang problema sa paghahanap ng eigenvector. Mayroong iba pang mga linear algebra calculators sa aming catalog, gamitin ang mga ito sa iyong pag-aaral o trabaho.
Sa matrix A, kung mayroong isang numero l tulad na AX = lX.
Sa kasong ito, ang numero l ay tinatawag eigenvalue operator (matrix A) na naaayon sa vector X.
Sa madaling salita, ang eigenvector ay isang vector na, sa ilalim ng pagkilos ng isang linear operator, ay nagiging isang collinear vector, i.e. multiply lang sa ilang numero. Sa kabaligtaran, ang mga hindi tamang vector ay mas mahirap ibahin ang anyo.
Isinulat namin ang kahulugan ng eigenvector bilang isang sistema ng mga equation:
Ilipat natin ang lahat ng termino sa kaliwang bahagi:

Ang huling sistema ay maaaring isulat sa matrix form tulad ng sumusunod:
(A - lE)X \u003d O
Ang resultang sistema ay palaging may zero na solusyon X = O. Ang mga ganitong sistema kung saan ang lahat ng libreng termino ay katumbas ng zero ay tinatawag homogenous. Kung ang matrix ng naturang sistema ay parisukat, at ang determinant nito ay hindi katumbas ng zero, kung gayon ayon sa mga formula ng Cramer, palagi kaming makakakuha ng isang natatanging solusyon - zero. Mapapatunayan na ang sistema ay may mga non-zero na solusyon kung at kung ang determinant ng matrix na ito ay katumbas ng zero, i.e.
|A - lE| =  = 0
= 0
Ang equation na ito na may hindi kilalang l ay tinatawag katangian equation (katangiang polinomyal) matrix A (linear operator).
Mapapatunayan na ang katangiang polynomial ng isang linear operator ay hindi nakasalalay sa pagpili ng batayan.
Halimbawa, hanapin natin eigenvalues at eigenvectors ng linear operator na ibinigay ng matrix А = .
Upang gawin ito, binubuo namin ang katangiang equation |А - lЕ| = ![]() \u003d (1 - l) 2 - 36 \u003d 1 - 2l + l 2 - 36 \u003d l 2 - 2l - 35 \u003d 0; D \u003d 4 + 140 \u003d 144; eigenvalues l 1 = (2 - 12)/2 = -5; l 2 \u003d (2 + 12) / 2 \u003d 7.
\u003d (1 - l) 2 - 36 \u003d 1 - 2l + l 2 - 36 \u003d l 2 - 2l - 35 \u003d 0; D \u003d 4 + 140 \u003d 144; eigenvalues l 1 = (2 - 12)/2 = -5; l 2 \u003d (2 + 12) / 2 \u003d 7.
Upang mahanap ang eigenvectors, nilulutas namin ang dalawang sistema ng mga equation
(A + 5E) X = O
(A - 7E) X = O
Para sa una sa kanila, ang pinalawak na matrix ay kukuha ng form
![]() ,
,
kung saan x 2 \u003d c, x 1 + (2/3) c \u003d 0; x 1 \u003d - (2/3) s, i.e. X (1) \u003d (- (2/3) s; s).
Para sa pangalawa sa kanila, ang pinalawak na matrix ay kukuha ng anyo
![]() ,
,
kung saan x 2 \u003d c 1, x 1 - (2/3) c 1 \u003d 0; x 1 \u003d (2/3) s 1, i.e. X (2) \u003d ((2/3) s 1; s 1).
Kaya, ang eigenvectors ng linear operator na ito ay lahat ng vectors ng form (-(2/3)c; c) na may eigenvalue (-5) at lahat ng vectors ng form ((2/3)c 1 ; c 1) na may eigenvalue 7 .
Mapapatunayan na ang matrix ng operator A sa batayan na binubuo ng mga eigenvector nito ay dayagonal at may anyo:
 ,
,
kung saan ako ang mga eigenvalues ng matrix na ito.
Totoo rin ang kabaligtaran: kung ang matrix A sa ilang batayan ay dayagonal, kung gayon ang lahat ng mga vector ng batayan na ito ay magiging eigenvectors ng matrix na ito.
Mapapatunayan din na kung ang isang linear na operator ay may n pairwise na natatanging eigenvalues, kung gayon ang mga katumbas na eigenvectors ay linearly independent, at ang matrix ng operator na ito sa kaukulang batayan ay may diagonal na anyo.
Ipaliwanag natin ito sa nakaraang halimbawa. Kunin natin ang mga di-zero na halaga c at c 1 , ngunit ang mga vector X (1) at X (2) ay linearly independent, i.e. magiging batayan. Halimbawa, hayaan ang c \u003d c 1 \u003d 3, pagkatapos ay X (1) \u003d (-2; 3), X (2) \u003d (2; 3).
I-verify natin ang linear na kalayaan ng mga vector na ito:
12 ≠ 0. Sa bagong batayan na ito, ang matrix A ay kukuha ng anyong A * = .
Upang i-verify ito, ginagamit namin ang formula A * = C -1 AC. Hanapin muna natin ang C -1.
C -1 = ![]() ;
;

Quadratic na mga anyo
parisukat na anyo f (x 1, x 2, xn) mula sa n mga variable ay tinatawag na kabuuan, ang bawat termino ay alinman sa parisukat ng isa sa mga variable, o ang produkto ng dalawang magkaibang mga variable, na kinuha sa isang tiyak na koepisyent: f (x 1 , x 2, xn) = ![]() (a ij = a ji).
(a ij = a ji).
Ang matrix A, na binubuo ng mga coefficient na ito, ay tinatawag matris parisukat na anyo. Ito'y palaging simetriko matrix (ibig sabihin, isang simetriko ng matrix tungkol sa pangunahing dayagonal, a ij = a ji).
Sa matrix notation, ang quadratic form ay may anyong f(X) = X T AX, kung saan
Sa totoo lang

Halimbawa, isulat natin ang quadratic form sa matrix form.
Upang gawin ito, nakahanap kami ng isang matrix ng isang parisukat na anyo. Ang mga elemento ng dayagonal nito ay katumbas ng mga coefficient sa mga parisukat ng mga variable, at ang natitirang mga elemento ay katumbas ng kalahati ng kaukulang mga coefficient ng quadratic form. kaya lang

Hayaang makuha ang matrix-column ng mga variable X sa pamamagitan ng nondegenerate linear transformation ng matrix-column Y, i.e. X = CY, kung saan ang C ay isang non-degenerate matrix ng order n. Pagkatapos ay ang quadratic form f(X) = X T AX = (CY) T A(CY) = (Y T C T)A(CY) = Y T (C T AC)Y.
Kaya, sa ilalim ng isang non-degenerate linear transformation C, ang matrix ng parisukat na anyo ay tumatagal ng anyo: A * = C T AC.
Halimbawa, hanapin natin ang quadratic form f(y 1, y 2) na nakuha mula sa quadratic form f(x 1, x 2) = 2x 1 2 + 4x 1 x 2 - 3x 2 2 sa pamamagitan ng linear transformation.

Ang quadratic form ay tinatawag kanonikal(Mayroon itong canonical view) kung ang lahat ng coefficients nito a ij = 0 para sa i ≠ j, i.e.
f(x 1, x 2, x n) = a 11 x 1 2 + a 22 x 2 2 + a nn x n 2 =.
Ang matrix nito ay dayagonal.
Teorama(ang patunay ay hindi ibinigay dito). Anumang parisukat na anyo ay maaaring gawing kanonikal na anyo gamit ang isang non-degenerate linear transformation.
Halimbawa, bawasan natin sa canonical form ang quadratic form
f (x 1, x 2, x 3) \u003d 2x 1 2 + 4x 1 x 2 - 3x 2 2 - x 2 x 3.
Upang gawin ito, pumili muna kami buong parisukat may variable x 1:
f (x 1, x 2, x 3) \u003d 2 (x 1 2 + 2x 1 x 2 + x 2 2) - 2x 2 2 - 3x 2 2 - x 2 x 3 \u003d 2 (x 1 + x 2) ) 2 - 5x 2 2 - x 2 x 3.
Ngayon pipiliin namin ang buong parisukat para sa variable x 2:
f (x 1, x 2, x 3) \u003d 2 (x 1 + x 2) 2 - 5 (x 2 2 + 2 * x 2 * (1/10) x 3 + (1/100) x 3 2 ) + (5/100) x 3 2 =
\u003d 2 (x 1 + x 2) 2 - 5 (x 2 - (1/10) x 3) 2 + (1/20) x 3 2.
Pagkatapos ay ang non-degenerate linear transformation y 1 \u003d x 1 + x 2, y 2 \u003d x 2 + (1/10) x 3 at y 3 \u003d x 3 ay nagdadala ng quadratic form na ito sa canonical form f (y 1 , y 2, y 3) = 2y 1 2 - 5y 2 2 + (1/20)y 3 2 .
Tandaan na ang kanonikal na anyo ng isang parisukat na anyo ay hindi malinaw na tinukoy (ang parehong parisukat na anyo ay maaaring bawasan sa kanonikal na anyo iba't ibang paraan). Gayunpaman, ang iba't ibang paraan Ang mga canonical form ay may bilang karaniwang katangian. Sa partikular, ang bilang ng mga termino na may positibong (negatibong) coefficient ng isang parisukat na anyo ay hindi nakasalalay sa kung paano binabawasan ang anyo sa form na ito (halimbawa, sa isinasaalang-alang na halimbawa ay palaging may dalawang negatibo at isang positibong koepisyent). Ang ari-arian na ito ay tinatawag na batas ng inertia ng mga parisukat na anyo.
I-verify natin ito sa pamamagitan ng pagbabawas ng parehong quadratic form sa canonical form sa ibang paraan. Simulan natin ang pagbabago sa variable x 2:
f (x 1, x 2, x 3) \u003d 2x 1 2 + 4x 1 x 2 - 3x 2 2 - x 2 x 3 \u003d -3x 2 2 - x 2 x 3 + 4x 1 x 2 + 2x 1 2 \u003d - 3(x 2 2 +
+ 2 * x 2 ((1/6) x 3 - (2/3) x 1) + ((1/6) x 3 - (2/3) x 1) 2) + 3 ((1/6) x 3 - (2/3) x 1) 2 + 2x 1 2 =
\u003d -3 (x 2 + (1/6) x 3 - (2/3) x 1) 2 + 3 ((1/6) x 3 + (2/3) x 1) 2 + 2x 1 2 \ u003d f (y 1, y 2, y 3) = -3y 1 2 -
+ 3y 2 2 + 2y 3 2, kung saan y 1 \u003d - (2/3) x 1 + x 2 + (1/6) x 3, y 2 \u003d (2/3) x 1 + (1/6 ) x 3 at y 3 = x 1 . Dito, isang negatibong koepisyent -3 sa y 1 at dalawang positibong coefficient 3 at 2 sa y 2 at y 3 (at gamit ang isa pang paraan, nakakuha kami ng negatibong koepisyent (-5) sa y 2 at dalawang positibong koepisyent: 2 sa y 1 at 1/20 para sa y 3).
Dapat ding tandaan na ang ranggo ng isang matrix ng isang parisukat na anyo, na tinatawag ang ranggo ng parisukat na anyo, ay katumbas ng bilang non-zero coefficients kanonikal na anyo at hindi nagbabago sa ilalim ng mga linear na pagbabago.
Ang quadratic form na f(X) ay tinatawag positibo (negatibo) tiyak, kung para sa lahat ng mga halaga ng mga variable na hindi sabay-sabay na katumbas ng zero, ito ay positibo, i.e. f(X) > 0 (negatibo, ibig sabihin.
f(X)< 0).
Halimbawa, ang quadratic form f 1 (X) \u003d x 1 2 + x 2 2 ay positive definite, dahil ay ang kabuuan ng mga parisukat, at ang parisukat na anyo f 2 (X) \u003d -x 1 2 + 2x 1 x 2 - x 2 2 ay negatibong tiyak, dahil kumakatawan ito ay maaaring katawanin bilang f 2 (X) \u003d - (x 1 - x 2) 2.
Sa karamihan ng mga praktikal na sitwasyon, medyo mas mahirap itatag ang sign-definiteness ng isang quadratic form, kaya isa sa mga sumusunod na theorems ang ginagamit para dito (binubalangkas namin ang mga ito nang walang mga patunay).
Teorama. Ang isang parisukat na anyo ay positibo (negatibo) tiyak kung at kung ang lahat ng eigenvalues ng matrix nito ay positibo (negatibo).
Teorama(Sylvester's criterion). Ang isang parisukat na anyo ay positibong tiyak kung at kung ang lahat ng pangunahing menor de edad ng matrix ng form na ito ay positibo.
Major (sulok) menor Ang k-th order ng matrix A ng n-th order ay tinatawag na determinant ng matrix, na binubuo ng mga unang k row at column ng matrix A ().
Tandaan na para sa mga negatibong tiyak na parisukat na anyo, ang mga palatandaan ng pangunahing mga menor de edad ay kahalili, at ang unang-sunod na menor ay dapat na negatibo.
Halimbawa, sinusuri namin ang quadratic form f (x 1, x 2) = 2x 1 2 + 4x 1 x 2 + 3x 2 2 para sa sign-definiteness.
![]() = (2 - l)*
= (2 - l)*
*(3 - l) - 4 \u003d (6 - 2l - 3l + l 2) - 4 \u003d l 2 - 5l + 2 \u003d 0; D = 25 - 8 = 17; ![]() . Samakatuwid, ang parisukat na anyo ay positibong tiyak.
. Samakatuwid, ang parisukat na anyo ay positibong tiyak.
Paraan 2. Ang pangunahing menor ng unang pagkakasunud-sunod ng matrix AD 1 = a 11 = 2 > 0. Ang pangunahing menor ng pangalawang order D 2 = = 6 - 4 = 2 > 0. Samakatuwid, ayon sa pamantayang Sylvester, ang parisukat na anyo ay positibong tiyak.
Sinusuri namin ang isa pang quadratic form para sa sign-definiteness, f (x 1, x 2) \u003d -2x 1 2 + 4x 1 x 2 - 3x 2 2.
Paraan 1. Bumuo tayo ng isang matrix ng quadratic form А = . Ang katangiang equation ay magkakaroon ng anyo ![]() = (-2 - l)*
= (-2 - l)*
*(-3 - l) - 4 = (6 + 2l + 3l + l 2) - 4 = l 2 + 5l + 2 = 0; D = 25 - 8 = 17; ![]() . Samakatuwid, ang parisukat na anyo ay negatibong tiyak.
. Samakatuwid, ang parisukat na anyo ay negatibong tiyak.
Paraan 2. Ang pangunahing minor ng unang order ng matrix A D 1 = a 11 =
= -2 < 0. Главный минор второго порядка D 2 = = 6 - 4 = 2 >0. Samakatuwid, ayon sa Sylvester criterion, ang parisukat na anyo ay negatibong tiyak (ang mga palatandaan ng pangunahing mga menor de edad ay kahalili, simula sa minus).
At bilang isa pang halimbawa, sinusuri namin ang quadratic form f (x 1, x 2) \u003d 2x 1 2 + 4x 1 x 2 - 3x 2 2 para sa sign-definiteness.
Paraan 1. Bumuo tayo ng isang matrix ng quadratic form А = . Ang katangiang equation ay magkakaroon ng anyo ![]() = (2 - l)*
= (2 - l)*
*(-3 - l) - 4 = (-6 - 2l + 3l + l 2) - 4 = l 2 + l - 10 = 0; D = 1 + 40 = 41; ![]() .
.
Ang isa sa mga numerong ito ay negatibo at ang isa ay positibo. Ang mga palatandaan ng eigenvalues ay iba. Samakatuwid, ang isang parisukat na anyo ay hindi maaaring maging negatibo o positibong tiyak, i.e. ang quadratic form na ito ay hindi sign-definite (maaari itong kumuha ng mga halaga ng anumang sign).
Paraan 2. Ang pangunahing minor ng unang order ng matrix A D 1 = a 11 = 2 > 0. Ang pangunahing minor ng pangalawang order D 2 = = -6 - 4 = -10< 0. Следовательно, по критерию Сильвестра квадратичная форма не является знакоопределенной (знаки главных миноров разные, при этом первый из них - положителен).
Paano i-paste mga pormula sa matematika sa website?
Kung sakaling kailanganin mong magdagdag ng isa o dalawang mathematical formula sa isang web page, kung gayon ang pinakamadaling paraan upang gawin ito ay tulad ng inilarawan sa artikulo: ang mga mathematical formula ay madaling naipasok sa site sa anyo ng mga larawan na awtomatikong nabubuo ng Wolfram Alpha. Bilang karagdagan sa pagiging simple, ang unibersal na paraan na ito ay makakatulong na mapabuti ang visibility ng site sa mga search engine. Ito ay gumagana nang mahabang panahon (at sa tingin ko ito ay gagana magpakailanman), ngunit ito ay luma na sa moral.
Kung patuloy kang gumagamit ng mga formula sa matematika sa iyong site, inirerekumenda kong gumamit ka ng MathJax, isang espesyal na library ng JavaScript na nagpapakita ng math notation sa mga web browser gamit ang MathML, LaTeX, o ASCIIMathML markup.
Mayroong dalawang paraan upang simulan ang paggamit ng MathJax: (1) gamit ang isang simpleng code, maaari mong mabilis na ikonekta ang isang MathJax script sa iyong site, na awtomatikong mai-load mula sa isang malayong server sa tamang oras (listahan ng mga server); (2) i-upload ang MathJax script mula sa isang malayuang server patungo sa iyong server at ikonekta ito sa lahat ng pahina ng iyong site. Ang pangalawang paraan ay mas kumplikado at nakakaubos ng oras at magbibigay-daan sa iyong mapabilis ang paglo-load ng mga pahina ng iyong site, at kung ang parent na MathJax server ay pansamantalang hindi magagamit sa ilang kadahilanan, hindi ito makakaapekto sa iyong sariling site sa anumang paraan. Sa kabila ng mga pakinabang na ito, pinili ko ang unang paraan, dahil ito ay mas simple, mas mabilis at hindi nangangailangan ng mga teknikal na kasanayan. Sundin ang aking halimbawa, at sa loob ng 5 minuto ay magagamit mo na ang lahat ng feature ng MathJax sa iyong website.
Maaari mong ikonekta ang script ng MathJax library mula sa isang malayuang server gamit ang dalawang opsyon sa code na kinuha mula sa pangunahing website ng MathJax o mula sa pahina ng dokumentasyon:
Kailangang kopyahin at i-paste ang isa sa mga opsyon sa code na ito sa code ng iyong web page, mas mabuti sa pagitan ng mga tag
At o pagkatapos mismo ng tag . Ayon sa unang opsyon, ang MathJax ay naglo-load nang mas mabilis at nagpapabagal sa pahina nang mas kaunti. Ngunit awtomatikong sinusubaybayan at nilo-load ng pangalawang opsyon ang pinakabagong bersyon ng MathJax. Kung ilalagay mo ang unang code, kakailanganin itong i-update sa pana-panahon. Kung i-paste mo ang pangalawang code, ang mga pahina ay maglo-load nang mas mabagal, ngunit hindi mo kailangang patuloy na subaybayan ang mga update sa MathJax.Ang pinakamadaling paraan upang ikonekta ang MathJax ay nasa Blogger o WordPress: sa control panel ng site, magdagdag ng widget na idinisenyo upang magpasok ng third-party na JavaScript code, kopyahin ang una o pangalawang bersyon ng load code na ipinakita sa itaas dito, at ilagay ang widget nang mas malapit. sa simula ng template (sa pamamagitan ng paraan, ito ay hindi sa lahat ng kailangan , dahil ang MathJax script ay load asynchronously). Iyon lang. Ngayon matutunan ang MathML, LaTeX, at ASCIIMathML markup syntax at handa ka nang mag-embed ng mga math formula sa iyong mga web page.
Ang anumang fractal ay binuo ayon sa isang tiyak na panuntunan, na patuloy na inilalapat walang limitasyong halaga minsan. Ang bawat ganoong oras ay tinatawag na isang pag-ulit.
Ang umuulit na algorithm para sa paggawa ng isang Menger sponge ay medyo simple: ang orihinal na cube na may gilid 1 ay hinati ng mga eroplanong parallel sa mga mukha nito sa 27 pantay na cube. Ang isang gitnang kubo at 6 na kubo na katabi nito kasama ang mga mukha ay tinanggal mula dito. Ito ay lumiliko ang isang set na binubuo ng 20 natitirang mas maliliit na cubes. Ang paggawa ng pareho sa bawat isa sa mga cube na ito, nakakakuha kami ng isang set na binubuo ng 400 mas maliliit na cube. Ang pagpapatuloy ng prosesong ito nang walang katapusan, nakukuha namin ang Menger sponge.
Kahulugan 9.3. Vector X tinawag sariling vector matrice PERO kung may ganyang numero λ, na taglay ng pagkakapantay-pantay: PERO X= λ X, iyon ay, ang resulta ng pag-aaplay sa X linear transformation na ibinigay ng matrix PERO, ay ang multiplikasyon ng vector na ito sa numero λ . Ang numero mismo λ tinawag sariling numero matrice PERO.
Pagpapalit sa mga formula (9.3) x` j = λx j , nakakakuha kami ng isang sistema ng mga equation para sa pagtukoy ng mga coordinate ng eigenvector:
 . (9.5)
. (9.5)
Ang linear na ito homogenous na sistema magkakaroon lamang ng di-trivial na solusyon kung ang pangunahing determinant nito ay 0 (Cramer's rule). Sa pamamagitan ng pagsulat ng kundisyong ito sa anyo:

nakakakuha tayo ng equation para sa pagtukoy ng eigenvalues λ tinawag katangian equation. Sa madaling sabi, maaari itong ilarawan bilang mga sumusunod:
| A-λE | = 0, (9.6)
dahil ang kaliwang bahagi nito ay ang determinant ng matrix A-λE. Polinomyal na may kinalaman sa λ | A-λE| tinawag katangiang polinomyal matrices a.
Mga katangian ng katangiang polynomial:
1) Ang katangiang polynomial ng isang linear na pagbabago ay hindi nakasalalay sa pagpili ng batayan. Patunay. ![]() (tingnan ang (9.4)), ngunit
(tingnan ang (9.4)), ngunit ![]() Dahil dito, . Kaya, hindi nakasalalay sa pagpili ng batayan. Samakatuwid, at | A-λE| hindi nagbabago sa paglipat sa isang bagong batayan.
Dahil dito, . Kaya, hindi nakasalalay sa pagpili ng batayan. Samakatuwid, at | A-λE| hindi nagbabago sa paglipat sa isang bagong batayan.
2) Kung ang matrix PERO ang linear transformation ay simetriko(mga. a ij = isang ji), kung gayon ang lahat ng mga ugat ng katangian na equation (9.6) ay mga tunay na numero.
Mga katangian ng eigenvalues at eigenvectors:
1) Kung pipili tayo ng batayan mula sa eigenvectors x 1, x 2, x 3 naaayon sa eigenvalues λ 1 , λ 2 , λ 3 matrice PERO, pagkatapos sa batayan na ito ang linear transformation A ay may dayagonal na matrix:
 (9.7) Ang patunay ng property na ito ay sumusunod sa kahulugan ng eigenvectors.
(9.7) Ang patunay ng property na ito ay sumusunod sa kahulugan ng eigenvectors.
2) Kung ang pagbabagong-anyo eigenvalues PERO ay magkaiba, kung gayon ang mga eigenvector na naaayon sa kanila ay linearly independent.
3) Kung ang katangian polynomial ng matrix PERO ay may tatlong magkakaibang ugat, pagkatapos ay sa ilang batayan ang matris PERO ay may dayagonal na hugis.
Hanapin natin ang eigenvalues at eigenvectors ng matrix Gawin natin ang katangiang equation:  (1- λ
)(5 - λ
)(1 - λ
) + 6 - 9(5 - λ
) - (1 - λ
) - (1 - λ
) = 0, λ
³ - 7 λ
² + 36 = 0, λ
1 = -2, λ
2 = 3, λ
3 = 6.
(1- λ
)(5 - λ
)(1 - λ
) + 6 - 9(5 - λ
) - (1 - λ
) - (1 - λ
) = 0, λ
³ - 7 λ
² + 36 = 0, λ
1 = -2, λ
2 = 3, λ
3 = 6.
Hanapin ang mga coordinate ng eigenvector na tumutugma sa bawat nahanap na halaga λ. Mula sa (9.5) sumusunod na kung X (1) ={x 1 , x 2 , x 3) ay ang eigenvector na katumbas ng λ 1 = -2, pagkatapos
 ay isang collaborative ngunit hindi tiyak na sistema. Ang solusyon nito ay maaaring isulat bilang X (1)
={a,0,-a), kung saan ang a ay anumang numero. Sa partikular, kung kailangan mo iyon | x (1)
|=1, X (1)
=
ay isang collaborative ngunit hindi tiyak na sistema. Ang solusyon nito ay maaaring isulat bilang X (1)
={a,0,-a), kung saan ang a ay anumang numero. Sa partikular, kung kailangan mo iyon | x (1)
|=1, X (1)
=
Pagpapalit sa system (9.5) λ 2 =3, nakakakuha kami ng isang sistema para sa pagtukoy ng mga coordinate ng pangalawang eigenvector - x (2) ={y1,y2,y3}:
 , saan X (2)
={b,-b,b) o, ibinigay | x (2)
|=1, x (2)
=
, saan X (2)
={b,-b,b) o, ibinigay | x (2)
|=1, x (2)
= ![]()
Para sa λ 3 = 6 hanapin ang eigenvector x (3) ={z1, z2, z3}:
 , x (3)
={c,2c,c) o sa normalized na bersyon
, x (3)
={c,2c,c) o sa normalized na bersyon
x (3) = ![]() Ito ay makikita na X (1) X (2)
= ab-ab= 0, x (1) x (3)
= ac-ac= 0, x (2) x (3)
= bc- 2bc + bc= 0. Kaya, ang eigenvectors ng matrix na ito ay pairwise orthogonal.
Ito ay makikita na X (1) X (2)
= ab-ab= 0, x (1) x (3)
= ac-ac= 0, x (2) x (3)
= bc- 2bc + bc= 0. Kaya, ang eigenvectors ng matrix na ito ay pairwise orthogonal.
Lektura 10
Mga parisukat na anyo at ang kanilang koneksyon sa mga simetriko na matrice. Mga katangian ng eigenvectors at eigenvalues ng isang simetriko matrix. Pagbawas ng isang parisukat na anyo sa isang kanonikal na anyo.
Kahulugan 10.1.parisukat na anyo tunay na mga variable x 1, x 2,…, x n tinatawag ang isang polynomial ng pangalawang degree na may kinalaman sa mga variable na ito, na hindi naglalaman ng libreng termino at mga termino ng unang degree.
Mga halimbawa ng mga parisukat na anyo:
(n = 2),
(n = 3). (10.1)
Alalahanin ang kahulugan ng isang simetriko matrix na ibinigay sa huling lecture:
Kahulugan 10.2. Ang square matrix ay tinatawag simetriko, kung , iyon ay, kung ang mga elemento ng matrix ay simetriko na may paggalang sa pangunahing dayagonal ay pantay.
Mga katangian ng eigenvalues at eigenvectors ng isang simetriko matrix:
1) Ang lahat ng eigenvalues ng isang simetriko matrix ay totoo.
Patunay (para sa n = 2).
Hayaan ang matrix PERO mukhang:  . Gawin natin ang katangiang equation:
. Gawin natin ang katangiang equation:
(10.2) Hanapin natin ang discriminant:
Samakatuwid, ang equation ay mayroon lamang tunay na mga ugat.
2) Mga Eigenvector ang simetriko matrix ay orthogonal.
Patunay (para sa n= 2).
Ang mga coordinate ng eigenvectors at dapat matugunan ang mga equation.
". Ang unang bahagi ay binabalangkas ang mga probisyon na minimal na kinakailangan para sa pag-unawa sa chemometrics, at ang pangalawang bahagi ay naglalaman ng mga katotohanan na kailangan mong malaman para sa isang mas malalim na pag-unawa sa mga pamamaraan ng multivariate analysis. Ang pagtatanghal ay inilalarawan ng mga halimbawang ginawa sa isang Excel workbook Matrix.xls na kasama ng dokumentong ito.
Ang mga link sa mga halimbawa ay inilalagay sa teksto bilang mga bagay sa Excel. Ang mga halimbawang ito ay isang abstract na kalikasan; sila ay hindi nakatali sa mga problema ng analytical chemistry. Ang mga tunay na halimbawa ng paggamit ng matrix algebra sa chemometrics ay tinatalakay sa ibang mga teksto na nakatuon sa iba't ibang mga aplikasyon ng chemometric.
Karamihan sa mga sukat na isinagawa sa analytical chemistry ay hindi direkta ngunit hindi direkta. Nangangahulugan ito na sa eksperimento, sa halip na ang halaga ng nais na analyte C (konsentrasyon), isa pang halaga ang nakuha. x(signal) na nauugnay sa ngunit hindi katumbas ng C, i.e. x(C) ≠ C. Bilang isang tuntunin, ang uri ng pagtitiwala x(C) ay hindi kilala, ngunit sa kabutihang palad sa analytical chemistry karamihan sa mga sukat ay proporsyonal. Nangangahulugan ito na bilang ang konsentrasyon ng C in a beses, ang signal X ay tataas ng parehong halaga., i.e. x(a C) = isang x(C). Bilang karagdagan, ang mga signal ay additive din, kaya ang signal mula sa isang sample na naglalaman ng dalawang sangkap na may mga konsentrasyon ng C 1 at C 2 ay magiging ay katumbas ng kabuuan signal mula sa bawat bahagi, i.e. x(C1 + C2) = x(C1)+ x(C2). Ang proporsyonalidad at additivity ay magkasamang nagbibigay linearity. Maraming mga halimbawa ang maaaring ibigay upang ilarawan ang prinsipyo ng linearity, ngunit sapat na upang banggitin ang dalawa sa mga pinaka-kapansin-pansin na mga halimbawa - chromatography at spectroscopy. Ang pangalawang tampok na likas sa eksperimento sa analytical chemistry ay multichannel. Ang mga modernong kagamitan sa pagsusuri ay sabay-sabay na sumusukat ng mga signal para sa maraming mga channel. Halimbawa, ang intensity ng light transmission ay sinusukat para sa ilang mga wavelength nang sabay-sabay, i.e. saklaw. Samakatuwid, sa eksperimento kami ay nakikitungo sa iba't ibang mga signal x 1 , x 2 ,...., x n nagpapakilala sa hanay ng mga konsentrasyon C 1 ,C 2 , ..., C m ng mga sangkap na nasa sistemang pinag-aaralan.
kanin. 1 Spectra
Kaya, ang analytical na eksperimento ay nailalarawan sa pamamagitan ng linearity at multidimensionality. Samakatuwid, maginhawang isaalang-alang ang pang-eksperimentong data bilang mga vector at matrice at manipulahin ang mga ito gamit ang apparatus ng matrix algebra. Ang pagiging mabunga ng diskarteng ito ay inilalarawan ng halimbawang ipinakita sa , na nagpapakita ng tatlong spectra na kinuha para sa 200 wavelength mula 4000 hanggang 4796 cm–1. Una ( x 1) at pangalawa ( x 2) ang spectra ay nakuha para sa mga karaniwang sample kung saan ang mga konsentrasyon ng dalawang sangkap A at B ay kilala: sa unang sample [A] = 0.5, [B] = 0.1, at sa pangalawang sample [A] = 0.2, [ B] = 0.6. Ano ang masasabi tungkol sa isang bago, hindi kilalang sample, ang spectrum ng kung saan ay ipinahiwatig x 3 ?
Isaalang-alang ang tatlong pang-eksperimentong spectra x 1 , x 2 at x 3 bilang tatlong vector ng dimensyon 200. Gamit ang linear algebra, madaling maipakita iyon ng isa x 3 = 0.1 x 1 +0.3 x 2 , kaya ang pangatlong sample ay malinaw na naglalaman lamang ng mga sangkap A at B sa mga konsentrasyon [A] = 0.5×0.1 + 0.2×0.3 = 0.11 at [B] = 0.1×0.1 + 0.6×0.3 = 0.19.
1. Pangunahing impormasyon
1.1 Matrice
Matrix tinatawag na isang hugis-parihaba na talahanayan ng mga numero, halimbawa

kanin. 2 Matris
Ang mga matrice ay tinutukoy ng malalaking titik na naka-bold ( A), at ang kanilang mga elemento - na may kaukulang maliliit na titik na may mga indeks, i.e. a ij . Ang unang index ay binibilang ang mga hilera at ang pangalawang bilang ang mga hanay. Sa chemometrics, kaugalian na italaga ang pinakamataas na halaga ng index na may parehong titik tulad ng index mismo, ngunit sa malalaking titik. Samakatuwid, ang matrix A maaari ding isulat bilang ( a ij , i = 1,..., ako; j = 1,..., J). Para sa halimbawang matrix ako = 4, J= 3 at a 23 = −7.5.
Pares ng mga numero ako At J ay tinatawag na dimensyon ng matrix at tinutukoy bilang ako× J. Ang isang halimbawa ng isang matrix sa chemometrics ay isang set ng spectra na nakuha para sa ako mga sample sa J mga wavelength.
1.2. Ang pinakasimpleng operasyon na may mga matrice
Pwede ang matrices multiply sa mga numero. Sa kasong ito, ang bawat elemento ay pinarami ng numerong ito. Halimbawa -

kanin. 3 Pagpaparami ng matrix sa isang numero
Dalawang matrice ng parehong dimensyon ay maaaring maging element-wise tiklop At ibawas. Halimbawa,

kanin. 4 Pagdaragdag ng matris
Bilang resulta ng multiplikasyon sa isang numero at karagdagan, ang isang matrix ng parehong dimensyon ay nakuha.
Ang zero matrix ay isang matrix na binubuo ng mga zero. Ito ay itinalaga O. Obvious naman yun A+O = A, A−A = O at 0 A = O.
Pwede ang matrix transpose. Sa panahon ng operasyong ito, ang matrix ay binaligtad, i.e. ang mga row at column ay pinagpalit. Ang transposisyon ay ipinahiwatig ng isang gitling, A" o index A t . Kaya, kung A = {a ij , i = 1,..., ako; j = 1,...,J), pagkatapos A t = ( a ji , j = 1,...,J; i = 1,..., ako). Halimbawa

kanin. 5 Transposisyon ng matrix
Obvious naman na ( A t) t = A, (A+B) t = A t + B t .
1.3. Pagpaparami ng matrix
Pwede ang matrices magparami, ngunit kung mayroon lamang silang naaangkop na mga sukat. Kung bakit ganito ay magiging malinaw mula sa kahulugan. Produkto ng matrix A, sukat ako× K, at mga matrice B, sukat K× J, ay tinatawag na matrix C, sukat ako× J, na ang mga elemento ay mga numero
Kaya para sa produkto AB ito ay kinakailangan na ang bilang ng mga haligi sa kaliwang matrix A ay katumbas ng bilang ng mga hilera sa kanang matrix B. Halimbawa ng produkto ng matrix -
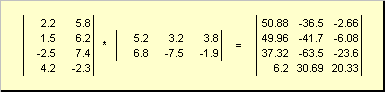
Fig.6 Produkto ng mga matrice
Ang matrix multiplication rule ay maaaring buuin bilang mga sumusunod. Upang mahanap ang isang elemento ng isang matrix C nakatayo sa intersection i-ika linya at j-th column ( c ij) dapat i-multiply ang elemento sa pamamagitan ng elemento i-ika row ng unang matrix A sa j-th column ng pangalawang matrix B at idagdag ang lahat ng mga resulta. Kaya sa halimbawang ipinakita, ang elemento mula sa ikatlong hilera at ang pangalawang hanay ay nakuha bilang kabuuan ng mga produkto na matalino sa elemento ng ikatlong hilera A at ikalawang hanay B

Fig.7 Elemento ng produkto ng matrices
Ang produkto ng mga matrice ay nakasalalay sa pagkakasunud-sunod, i.e. AB ≠ BA, kahit man lang para sa mga dimensional na dahilan. Ito raw ay non-commutative. Gayunpaman, ang produkto ng mga matrice ay nag-uugnay. Ibig sabihin nito ay ABC = (AB)C = A(BC). Bukod dito, ito rin ay distributive, i.e. A(B+C) = AB+AC. Obvious naman yun AO = O.
1.4. Mga parisukat na matrice
Kung ang bilang ng mga haligi ng isang matrix ay katumbas ng bilang ng mga hilera nito ( ako = J=N), kung gayon ang gayong matris ay tinatawag na parisukat. Sa seksyong ito, isasaalang-alang lamang natin ang mga naturang matrice. Sa mga matrice na ito, maaaring isa-isa ng isa ang mga matrice na may mga espesyal na katangian.
Nag-iisa matrix (tinutukoy ako at minsan E) ay isang matrix kung saan ang lahat ng mga elemento ay katumbas ng zero, maliban sa mga dayagonal, na katumbas ng 1, i.e.

Obvious naman AI = IA = A.
Ang matrix ay tinatawag dayagonal, kung ang lahat ng mga elemento nito, maliban sa mga dayagonal ( a ii) ay katumbas ng zero. Halimbawa
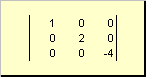
kanin. 8 Diagonal matrix
Ang matrix A tinawag ang tuktok tatsulok, kung ang lahat ng mga elemento nito na nakahiga sa ibaba ng dayagonal ay katumbas ng zero, i.e. a ij= 0, sa i>j. Halimbawa

kanin. 9 Upper triangular matrix
Ang mas mababang triangular matrix ay tinukoy nang katulad.
Ang matrix A tinawag simetriko, kung A t = A. Sa ibang salita a ij = a ji. Halimbawa

kanin. 10 Symmetric matrix
Ang matrix A tinawag orthogonal, kung
A t A = AA t = ako.
Ang matrix ay tinatawag normal kung
1.5. Bakas at determinant
Sumusunod parisukat na matris A(tinutukoy na Tr( A) o Sp( A)) ay ang kabuuan ng mga elementong dayagonal nito,
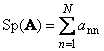
Halimbawa,

kanin. 11 Matrix na bakas
Obvious naman yun
Sp(α A) = α Sp( A) At
Sp( A+B) = Sp( A)+ Sp( B).
Maaari itong ipakita na
Sp( A) = Sp( A t), Sp( ako) = N,
at ganoon din
Sp( AB) = Sp( BA).
Ang isa pang mahalagang katangian ng isang square matrix ay ito determinant(tinutukoy ng det( A)). Ang kahulugan ng determinant sa pangkalahatang kaso ay medyo kumplikado, kaya magsisimula tayo sa pinakasimpleng opsyon - ang matrix A sukat (2×2). Pagkatapos
Para sa isang (3×3) matrix, ang determinant ay magiging katumbas ng
Sa kaso ng isang matrix ( N× N) ang determinant ay kinakalkula bilang kabuuan 1 2 3 ... N= N! mga termino, na ang bawat isa ay katumbas ng
![]()
Mga indeks k 1 , k 2 ,..., k N ay tinukoy bilang lahat ng posibleng ordered permutations r mga numero sa set (1, 2, ... , N). Ang pagkalkula ng determinant ng matrix ay isang kumplikadong pamamaraan, na sa pagsasanay ay isinasagawa gamit ang mga espesyal na programa. Halimbawa,

kanin. 12 Matrix determinant
Napansin lamang namin ang mga halatang katangian:
det( ako) = 1, det( A) = det( A t),
det( AB) = det( A)det( B).
1.6. Mga vector
Kung ang matrix ay may isang hanay lamang ( J= 1), pagkatapos ay tinatawag ang naturang bagay vector. Mas tiyak, isang column vector. Halimbawa
Ang mga matrice na binubuo ng isang hilera ay maaari ding isaalang-alang, halimbawa
![]()
Ang bagay na ito ay isa ring vector, ngunit row vector. Kapag nagsusuri ng data, mahalagang maunawaan kung aling mga vector ang ating kinakaharap - mga column o row. Kaya't ang spectrum na kinuha para sa isang sample ay maaaring ituring bilang isang row vector. Pagkatapos ang hanay ng mga spectral intensity sa ilang wavelength para sa lahat ng sample ay dapat ituring bilang isang column vector.
Ang dimensyon ng isang vector ay ang bilang ng mga elemento nito.
Malinaw na ang anumang column vector ay maaaring ma-transform sa isang row vector sa pamamagitan ng transposition, i.e.
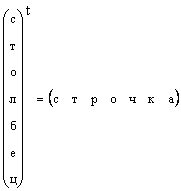
Sa mga kasong iyon kung saan ang anyo ng isang vector ay hindi partikular na tinukoy, ngunit isang vector lang ang sinabi, kung gayon ang ibig nilang sabihin ay isang column vector. Susunod din tayo sa panuntunang ito. Ang isang vector ay tinutukoy ng isang maliit na titik na direktang naka-bold na titik. Ang zero vector ay isang vector na lahat ng mga elemento ay katumbas ng zero. Ito ay ipinahiwatig 0 .
1.7. Ang pinakasimpleng operasyon na may mga vector
Ang mga vector ay maaaring idagdag at i-multiply sa mga numero sa parehong paraan tulad ng mga matrice. Halimbawa,

kanin. 13 Mga operasyon na may mga vector
Dalawang vector x At y tinawag collinear, kung may bilang na α na ganoon
1.8. Mga produkto ng mga vector
Dalawang vector ng parehong dimensyon N maaaring paramihin. Hayaang magkaroon ng dalawang vectors x = (x 1 , x 2 ,...,x N) t at y = (y 1 , y 2 ,...,y N) t . Ginagabayan ng panuntunan sa pagpaparami "hilera sa hanay", maaari tayong gumawa ng dalawang produkto mula sa mga ito: x t y At xy t . Unang gawain
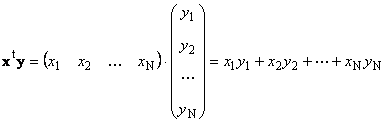
tinawag scalar o panloob. Ang resulta nito ay isang numero. Ginagamit din nito ang notasyon ( x,y)= x t y. Halimbawa,

kanin. 14 Panloob (scalar) na produkto
Pangalawang gawain
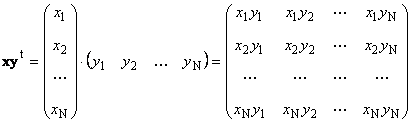
tinawag panlabas. Ang resulta nito ay isang dimension matrix ( N× N). Halimbawa,
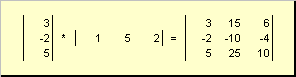
kanin. 15 Panlabas na produkto
Mga vector, produktong scalar na katumbas ng zero ay tinatawag orthogonal.
1.9. Normal na vector
Ang scalar product ng isang vector na may sarili nito ay tinatawag na scalar square. Ang halagang ito

tumutukoy sa isang parisukat haba vector x. Upang tukuyin ang haba (tinatawag ding ang nakasanayan vector) ginagamit ang notasyon
Halimbawa,
kanin. 16 Vector na pamantayan
Vector ng haba ng unit (|| x|| = 1) ay tinatawag na normalized. Nonzero vector ( x ≠ 0 ) ay maaaring gawing normal sa pamamagitan ng paghahati nito sa haba, i.e. x = ||x|| (x/||x||) = ||x|| e. Dito e = x/||x|| ay isang normalized na vector.
Ang mga vector ay tinatawag na orthonormal kung lahat sila ay normalized at pairwise orthogonal.
1.10. Anggulo sa pagitan ng mga vector
Ang scalar na produkto ay tumutukoy at iniksyonφ sa pagitan ng dalawang vector x At y
![]()
Kung ang mga vector ay orthogonal, kung gayon ang cosφ = 0 at φ = π/2, at kung sila ay collinear, kung gayon ang cosφ = 1 at φ = 0.
1.11. Vector na representasyon ng isang matrix
Ang bawat matris A laki ako× J ay maaaring kinakatawan bilang isang set ng mga vectors
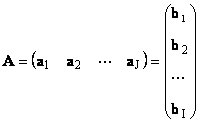
Narito ang bawat vector a j ay isang j-th column at row vector b i ay isang i-ika-row ng matrix A
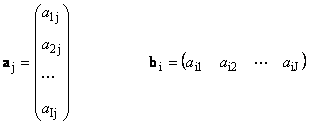
1.12. Mga vector na nakadepende sa linear
Mga vector ng parehong dimensyon ( N) ay maaaring idagdag at i-multiply sa isang numero, tulad ng mga matrice. Ang resulta ay isang vector ng parehong dimensyon. Hayaang magkaroon ng ilang mga vectors ng parehong dimensyon x 1 , x 2 ,...,x K at ang parehong bilang ng mga numero α α 1 , α 2 ,...,α K. Vector
y= α 1 x 1 + α 2 x 2 +...+α K x K
tinawag linear na kumbinasyon mga vector x k .
Kung mayroong mga hindi-zero na numerong α k ≠ 0, k = 1,..., K, Ano y = 0 , pagkatapos ay tulad ng isang set ng mga vectors x k tinawag nakadepende sa linear. Kung hindi, ang mga vector ay tinatawag na linearly independent. Halimbawa, mga vector x 1 = (2, 2) t at x 2 = (−1, −1) t ay linearly dependent, dahil x 1 +2x 2 = 0
1.13. Ranggo ng matrix
Isaalang-alang ang isang set ng K mga vector x 1 , x 2 ,...,x K mga sukat N. Ang ranggo ng sistemang ito ng mga vector ay ang pinakamataas na bilang ng mga linearly independent na mga vector. Halimbawa sa set
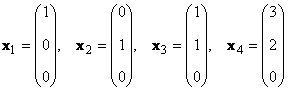
mayroon lamang dalawang linearly independent vectors, halimbawa x 1 at x 2 , kaya 2 ang ranggo nito.
Malinaw, kung mayroong higit pang mga vector sa set kaysa sa kanilang dimensyon ( K>N), kung gayon ang mga ito ay kinakailangang linearly na umaasa.
Ranggo ng matrix(tinutukoy ng ranggo( A)) ay ang ranggo ng sistema ng mga vectors na binubuo nito. Bagama't ang anumang matrix ay maaaring katawanin sa dalawang paraan (column vectors o row vectors), hindi ito nakakaapekto sa rank value, dahil
1.14. baligtad na matris
parisukat na matris A ay tinatawag na non-degenerate kung mayroon itong kakaiba reverse matris A-1 , tinutukoy ng mga kondisyon
AA −1 = A −1 A = ako.
Ang inverse matrix ay hindi umiiral para sa lahat ng matrice. Ang isang kinakailangan at sapat na kondisyon para sa hindi pagkabulok ay
det( A) ≠ 0 o ranggo( A) = N.
Ang matrix inversion ay isang kumplikadong pamamaraan kung saan mayroong mga espesyal na programa. Halimbawa,

kanin. 17 Pagbabaligtad ng matris
Nagbibigay kami ng mga formula para sa pinakasimpleng kaso - matrice 2 × 2
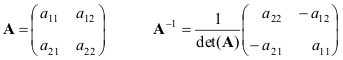
Kung matrices A At B ay non-degenerate, kung gayon
(AB) −1 = B −1 A −1 .
1.15. Pseudo-inverse matrix
Kung ang matris A ay degenerate at ang inverse matrix ay hindi umiiral, pagkatapos ay sa ilang mga kaso ay maaaring gamitin ng isa pseudo-inverse matrix, na tinukoy bilang tulad ng isang matrix A+ na
AA + A = A.
Ang pseudo-inverse matrix ay hindi lamang isa at ang anyo nito ay nakasalalay sa paraan ng pagtatayo. Halimbawa, para sa isang rectangular matrix, maaari mong gamitin ang Moore-Penrose method.
Kung ang bilang ng mga column ay mas mababa sa bilang ng mga row, kung gayon
A + =(A t A) −1 A t
Halimbawa,

kanin. 17a Pseudo matrix inversion
Kung ang bilang ng mga hanay mas maraming numero mga linya, pagkatapos
A + =A t ( AA t) −1
1.16. Multiplikasyon ng isang vector sa pamamagitan ng isang matrix
Vector x maaaring i-multiply sa isang matrix A angkop na sukat. Sa kasong ito, ang column vector ay pinarami sa kanan Ax, at ang vector string ay nasa kaliwa x t A. Kung ang sukat ng vector J, at ang dimensyon ng matrix ako× J pagkatapos ang resulta ay isang vector ng dimensyon ako. Halimbawa,

kanin. 18 Vector-Matrix Multiplication
Kung ang matris A- parisukat ( ako× ako), pagkatapos ay ang vector y = Ax ay may parehong sukat ng x. Obvious naman yun
A(α 1 x 1 + α 2 x 2) = α 1 Ax 1 + α 2 Ax 2 .
Samakatuwid ang mga matrice ay maaaring ituring bilang mga linear na pagbabagong-anyo ng mga vectors. Sa partikular x = x, baka = 0 .
2. Karagdagang impormasyon
2.1. Mga sistema ng linear equation
Hayaan A- laki ng matrix ako× J, ngunit b- dimensyon ng vector J. Isaalang-alang ang equation
Ax = b
may kinalaman sa vector x, mga sukat ako. Mahalaga, ito ay isang sistema ng ako linear equation na may J hindi kilala x 1 ,...,x J. Ang isang solusyon ay umiiral kung at kung lamang
ranggo( A) = ranggo( B) = R,
saan B ay ang augmented dimension matrix ako×( J+1) na binubuo ng matris A, nilagyan ng column b, B = (A b). Kung hindi, ang mga equation ay hindi pare-pareho.
Kung R = ako = J, kung gayon ang solusyon ay natatangi
x = A −1 b.
Kung R < ako, pagkatapos ay mayroong maraming iba't ibang mga solusyon na maaaring ipahayag sa mga tuntunin ng isang linear na kumbinasyon J−R mga vector. Sistema ng mga homogenous na equation Ax = 0 na may isang parisukat na matris A (N× N) ay may di-trivial na solusyon ( x ≠ 0 ) kung at kung det( A) = 0. Kung R= ranggo( A)<N, tapos meron N−R mga linearly independent na solusyon.
2.2. Bilinear at quadratic na mga anyo
Kung A ay isang parisukat na matris, at x At y- mga vector ng kaukulang dimensyon, pagkatapos ay ang scalar product ng form x t Ay tinawag bilinear ang hugis na tinukoy ng matrix A. Sa x = y pagpapahayag x t Ax tinawag parisukat anyo.
2.3. Positibong tiyak na matrice
parisukat na matris A tinawag positibong tiyak, kung para sa anumang nonzero vector x ≠ 0 ,
x t Ax > 0.
Ang negatibo (x t Ax < 0), hindi negatibo (x t Ax≥ 0) at hindi positibo (x t Ax≤ 0) ilang mga matrice.
2.4. Cholesky decomposition
Kung ang simetriko matrix A ay positibong tiyak, pagkatapos ay mayroong isang natatanging tatsulok na matrix U na may mga positibong elemento, kung saan
A = U t U.
Halimbawa,

kanin. 19 Cholesky decomposition
2.5. polar decomposition
Hayaan A ay isang nondegenerate square matrix ng dimensyon N× N. Tapos may kakaiba polar representasyon
A = SR,
saan S ay isang di-negatibong simetriko matrix, at R ay isang orthogonal matrix. matrice S At R maaaring malinaw na tukuyin:
S 2 = AA t o S = (AA t) ½ at R = S −1 A = (AA t) −½ A.
Halimbawa,
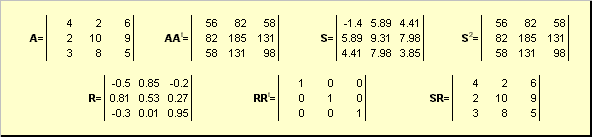
kanin. 20 Polar decomposition
Kung ang matris A ay degenerate, kung gayon ang agnas ay hindi natatangi - ibig sabihin: S mag-isa pa rin, pero R maaaring marami. Ang polar decomposition ay kumakatawan sa isang matrix A bilang kumbinasyon ng compression/stretch S at lumingon R.
2.6. Eigenvectors at eigenvalues
Hayaan A ay isang square matrix. Vector v tinawag sariling vector matrice A, kung
Av = λ v,
kung saan ang numero λ ay tinatawag eigenvalue matrice A. Kaya, ang pagbabagong-anyo na ginagawa ng matrix A higit sa vector v, ay nabawasan sa isang simpleng pag-uunat o compression na may salik na λ. Ang eigenvector ay tinutukoy hanggang sa multiplikasyon ng pare-parehong α ≠ 0, i.e. kung v ay isang eigenvector, pagkatapos ay α v ay isa ring eigenvector.
2.7. Eigenvalues
Sa matrix A, sukat ( N× N) ay hindi maaaring mas malaki kaysa sa N eigenvalues. Nabusog sila katangian equation
det( A − λ ako) = 0,
pagiging algebraic equation N-ika-utos. Sa partikular, para sa isang 2×2 matrix, ang katangiang equation ay may anyo
Halimbawa,

kanin. 21 Eigenvalues
Set ng eigenvalues λ 1 ,..., λ N matrice A tinawag spectrum A.
Ang spectrum ay may iba't ibang katangian. Sa partikular
det( A) = λ 1×...×λ N, Sp( A) = λ 1 +...+λ N.
Ang eigenvalues ng isang arbitrary na matrix ay maaaring kumplikadong mga numero, ngunit kung ang matrix ay simetriko ( A t = A), kung gayon ang mga eigenvalues nito ay totoo.
2.8. Mga Eigenvector
Sa matrix A, sukat ( N× N) ay hindi maaaring mas malaki kaysa sa N eigenvectors, bawat isa ay tumutugma sa sarili nitong halaga. Upang matukoy ang eigenvector v n kailangan mong lutasin ang isang sistema ng mga homogenous na equation
(A − λ n ako)v n = 0 .
Mayroon itong di-maliit na solusyon dahil det( a-λ n ako) = 0.
Halimbawa,

kanin. 22 Eigenvectors
Ang eigenvectors ng isang simetriko matrix ay orthogonal.



