Pagtataya sa pamamagitan ng exponential smoothing (ES, exponential smoothing). Pagtataya batay sa exponential smoothing method
Hanggang sa Pagtataya NGAYON! mas magandang modelo Exponential smoothing (ES) makikita mo sa tsart sa ibaba. Sa X axis - ang numero ng item, sa Y axis - porsyento ng pagpapabuti sa kalidad ng hula. Paglalarawan ng modelo, isang detalyadong pag-aaral, ang mga resulta ng mga eksperimento, basahin sa ibaba.
Paglalarawan ng modelo
Paraan ng pagtataya exponential smoothing ay isa sa pinaka mga simpleng paraan pagtataya. Ang isang hula ay maaari lamang makuha para sa isang panahon sa unahan. Kung ang pagtataya ay isinasagawa sa mga tuntunin ng mga araw, pagkatapos ay isang araw lamang sa unahan, kung linggo, pagkatapos ay isang linggo.
Para sa paghahambing, ang pagtataya ay isinagawa nang mas maaga sa isang linggo para sa 8 linggo.
Ano ang exponential smoothing?
Hayaan ang hilera MULA SA kumakatawan sa orihinal na serye ng mga benta para sa pagtataya
C(1)- unang linggong benta MULA SA(2) sa pangalawa at iba pa.

Figure 1. Mga benta sa pamamagitan ng linggo, serye MULA SA
Gayundin, isang hilera S kumakatawan sa isang exponentially smoothed serye ng mga benta. Ang coefficient α ay mula sa zero hanggang isa. Ito ay lumabas bilang mga sumusunod, narito ang isang punto sa oras (araw, linggo)
S (t+1) = S(t) + α *(С(t) - S(t))
Ang malalaking halaga ng pare-parehong pag-smoothing α ay nagpapabilis sa pagtugon ng forecast sa pagtalon sa naobserbahang proseso, ngunit maaaring humantong sa hindi mahuhulaan na mga outlier, dahil halos wala na ang smoothing.
Sa unang pagkakataon pagkatapos ng pagsisimula ng mga obserbasyon, pagkakaroon lamang ng isang resulta ng mga obserbasyon C (1) kapag ang forecast S (1) hindi, at imposible pa ring gumamit ng formula (1), bilang isang forecast S (2) dapat kumuha ng C (1) .
Ang formula ay madaling maisulat muli sa ibang anyo:
S (t+1) = (1 -α )* S (t) +α * MULA SA (t).
Kaya, sa isang pagtaas sa smoothing constant, ang bahagi ng kamakailang mga benta ay tumataas, at ang bahagi ng smoothed nakaraang mga benta ay bumababa.
Ang pare-parehong α ay pinili sa empirically. Karaniwan, maraming mga pagtataya ang ginagawa para sa iba't ibang mga constant at ang pinakamainam na pare-pareho ay pinipili sa mga tuntunin ng napiling pamantayan.
Maaaring ang criterion ay ang katumpakan ng pagtataya para sa mga nakaraang panahon.
Sa aming pag-aaral, isinasaalang-alang namin ang mga exponential smoothing na modelo kung saan kinukuha ng α ang mga halaga (0.2, 0.4, 0.6, 0.8). Para sa paghahambing sa Pagtataya NGAYON! para sa bawat produkto, ginawa ang mga pagtataya para sa bawat α, at pinili ang pinakatumpak na hula. Sa katotohanan, ang sitwasyon ay magiging mas kumplikado, ang gumagamit, na hindi alam nang maaga ang katumpakan ng forecast, ay kailangang magpasya sa coefficient α, kung saan ang kalidad ng forecast ay lubos na nakasalalay. Narito ang isang mabisyo na bilog.
malinaw

Figure 2. α =0.2 , ang antas ng exponential smoothing ay mataas, ang mga tunay na benta ay hindi gaanong isinasaalang-alang

Figure 3. α =0.4 , ang antas ng exponential smoothing ay karaniwan, ang mga tunay na benta ay isinasaalang-alang sa average na antas
Makikita mo kung paano habang tumataas ang pare-parehong α, ang makinis na serye ay higit na tumutugma sa mga tunay na benta, at kung may mga outlier o anomalya, makakakuha tayo ng napaka hindi tumpak na hula.

Figure 4. α =0.6 , ang antas ng exponential smoothing ay mababa, ang mga tunay na benta ay isinasaalang-alang nang malaki
Makikita natin na sa α=0.8, halos eksaktong inuulit ng serye ang orihinal, na nangangahulugang ang hula ay may kaugaliang panuntunan na "ang parehong halaga ay ibebenta tulad ng kahapon"
Dapat pansinin na dito ay ganap na imposibleng tumuon sa error ng approximation sa orihinal na data. Makakamit mo ang perpektong tugma, ngunit makakuha ng hindi katanggap-tanggap na hula.

Figure 5. α = 0.8 , ang antas ng exponential smoothing ay napakababa, ang mga tunay na benta ay lubos na isinasaalang-alang
Mga halimbawa ng pagtataya
Ngayon tingnan natin ang mga hula na ginawa gamit ang iba't ibang mga halaga ng α. Tulad ng makikita mula sa Figures 6 at 7, mas malaki ang smoothing coefficient, mas tumpak na inuulit nito ang mga tunay na benta na may pagkaantala ng isang hakbang, ang forecast. Ang ganitong pagkaantala ay maaaring maging kritikal, kaya hindi mo maaaring piliin lamang ang maximum na halaga ng α. Kung hindi, mapupunta tayo sa isang sitwasyon kung saan sasabihin natin na eksaktong magkano ang ibebenta gaya ng naibenta noong nakaraang panahon.

Figure 6. Prediction ng exponential smoothing method para sa α=0.2

Figure 7. Prediction ng exponential smoothing method para sa α=0.6
Tingnan natin kung ano ang mangyayari kapag α = 1.0. Alalahanin na S - hinulaang (smoothed) benta, C - tunay na benta.
S (t+1) = (1 -α )* S (t) +α * MULA SA (t).
S (t+1) = MULA SA (t).
Ang mga benta sa araw na t+1 ay hinuhulaan na katumbas ng mga benta sa nakaraang araw. Samakatuwid, ang pagpili ng isang pare-pareho ay dapat na lapitan nang matalino.
Paghahambing sa Pagtataya NGAYON!
Ngayon isaalang-alang ang pamamaraang ito pagtataya laban sa Pagtataya NGAYON!. Ang paghahambing ay isinagawa sa 256 na mga produkto na may iba't ibang mga benta, na may panandalian at pangmatagalang seasonality, na may "masamang" benta at mga kakulangan, mga stock at iba pang mga outlier. Para sa bawat produkto, isang pagtataya ang ginawa gamit ang exponential smoothing model, para sa iba't ibang α, ang pinakamahusay ay pinili at inihambing sa forecast gamit ang Forecast NGAYON!
Sa talahanayan sa ibaba, makikita mo ang halaga ng error sa pagtataya para sa bawat item. Ang error dito ay itinuturing bilang RMSE. Ito ang ugat ng karaniwang lihis hula mula sa katotohanan. Sa halos pagsasalita, ipinapakita nito kung gaano karaming mga yunit ng mga kalakal ang nalihis namin sa hula. Ang pagpapabuti ay nagpapakita ng kung ilang porsyento ang Pagtataya NGAYON! mas maganda kung positive ang number, at mas malala kung negative. Sa Figure 8, ang x-axis ay nagpapakita ng mga kalakal, ang y-axis ay nagpapahiwatig kung magkano ang Pagtataya NGAYON! mas mahusay kaysa sa hula ng exponential smoothing. Gaya ng nakikita mo mula sa graph na ito, Pagtataya NGAYON! halos palaging doble ang taas at halos hindi na mas masahol pa. Sa pagsasagawa, nangangahulugan ito na ang paggamit ng Pagtataya NGAYON! ay magbibigay-daan upang hatiin ang mga stock o bawasan ang mga kakulangan.
PhD sa Economics, Direktor para sa Agham at Pag-unlad ng CJSC "KIS"
Exponential smoothing na paraan
Pagbuo ng bago at pagsusuri ng kilala mga teknolohiya sa pamamahala, na nagbibigay-daan upang madagdagan ang kahusayan ng pamamahala ng negosyo, ay nagiging partikular na nauugnay para sa mga negosyong Ruso sa kasalukuyang panahon. Ang isa sa mga pinakasikat na tool ay ang sistema ng pagbabadyet, na batay sa pagbuo ng badyet ng negosyo na may kasunod na kontrol sa pagpapatupad. Ang badyet ay isang balanseng panandaliang komersyal, produksyon, pinansiyal at pang-ekonomiyang mga plano para sa pagpapaunlad ng organisasyon. Ang badyet ng kumpanya ay naglalaman ng mga target na kinakalkula batay sa data ng pagtataya. Ang pinakamahalagang pagtataya sa pagbabadyet para sa anumang negosyo ay ang pagtataya ng mga benta. Sa mga nakaraang artikulo, isang pagsusuri ng mga additive at multiplicative na modelo ay isinagawa at ang tinatayang dami ng benta para sa mga sumusunod na panahon ay kinakalkula.
Kapag sinusuri ang serye ng oras, ginamit ang moving average na paraan, kung saan ang lahat ng data, anuman ang panahon ng kanilang paglitaw, ay pantay. May isa pang paraan kung saan ang mga timbang ay itinalaga sa data, ang mas kamakailang data ay binibigyan ng mas timbang kaysa sa naunang data.
Ang exponential smoothing na paraan, hindi tulad ng moving average na paraan, ay maaari ding gamitin para sa mga panandaliang pagtataya ng trend sa hinaharap para sa isang yugto sa hinaharap at awtomatikong itinatama ang anumang hula sa liwanag ng mga pagkakaiba sa pagitan ng aktwal at hinulaang resulta. Iyon ang dahilan kung bakit ang pamamaraan ay may malinaw na kalamangan kaysa sa naunang isinasaalang-alang.
Ang pangalan ng pamamaraan ay nagmula sa katotohanan na ito ay gumagawa ng exponentially weighted moving averages sa buong serye ng oras. Sa exponential smoothing, ang lahat ng mga nakaraang obserbasyon ay isinasaalang-alang - ang nauna ay isinasaalang-alang na may pinakamataas na timbang, ang nauna - na may bahagyang mas mababa, ang pinakamaagang obserbasyon ay nakakaapekto sa resulta na may pinakamababang istatistikal na timbang.
Ang algorithm para sa pagkalkula ng mga exponentially smoothed na halaga sa anumang punto sa serye ng i ay batay sa tatlong dami:
ang aktwal na halaga ng Ai sa isang naibigay na punto sa row i,
hula sa isang punto sa seryeng Fi
ilang paunang natukoy na koepisyent ng smoothing W, pare-pareho sa buong serye.
Ang bagong hula ay maaaring isulat bilang:
Pagkalkula ng exponentially smoothed values
Sa praktikal na paggamit ng exponential smoothing method, dalawang problema ang lumitaw: ang pagpili ng smoothing factor (W), na higit na nakakaapekto sa mga resulta, at ang pagpapasiya ng paunang kondisyon (Fi). Sa isang banda, para makinis random deviations dapat bawasan ang halaga. Sa kabilang banda, upang madagdagan ang bigat ng mga bagong sukat, kailangan mong dagdagan.
Bagaman, sa prinsipyo, ang W ay maaaring kumuha ng anumang halaga mula sa hanay na 0< W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка).
Ang pagpili ng smoothing constant factor ay subjective. Ang mga analyst ng karamihan sa mga kumpanya ay gumagamit ng kanilang sarili tradisyonal na kahulugan W. Kaya, ayon sa nai-publish na data sa analytical department ng Kodak, ang halaga ng 0.38 ay tradisyonal na ginagamit, at sa Ford Motors ito ay 0.28 o 0.3.
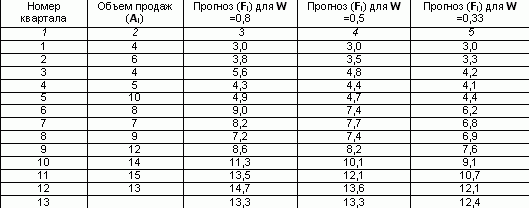
Ang manu-manong pagkalkula ng exponential smoothing ay nangangailangan ng napakalaking halaga ng monotonous na trabaho. Halimbawa, kalkulahin natin ang tinatayang dami para sa ika-13 quarter, kung mayroong data ng mga benta para sa huling 12 quarter, gamit ang simpleng exponential smoothing na paraan.
Ipagpalagay na para sa unang quarter ang forecast ng benta ay 3. At hayaan ang smoothing factor na W = 0.8.
Punan ang ikatlong hanay sa talahanayan, palitan para sa bawat kasunod na quarter ang halaga ng nauna ayon sa formula:
Para sa 2 quarters F2 = 0.8 * 4 (1-0.8) * 3 = 3.8
Para sa 3rd quarter F3 =0.8*6 (1-0.8)*3.8 =5.6
Katulad nito, ang isang smoothed value ay kinakalkula para sa coefficient na 0.5 at 0.33.
Pagkalkula ng Pagtataya sa Pagbebenta
Ang forecast para sa dami ng benta sa W = 0.8 para sa ika-13 quarter ay 13.3 libong rubles.
Ang data na ito ay maaaring ipakita sa graphical na anyo:

Exponential Smoothing
04/02/2011 - Ang pagnanais ng tao na iangat ang tabing ng hinaharap at mahulaan ang takbo ng mga kaganapan ay may parehong mahabang kasaysayan tulad ng kanyang mga pagtatangka na maunawaan ang mundo. Malinaw na ang medyo malakas na mahahalagang motibo (teoretikal at praktikal) ay sumasailalim sa interes sa hula. Ang pagtataya ay nagsisilbing pinakamahalagang paraan para sa pagsubok ng mga siyentipikong teorya at hypotheses. Ang kakayahang mahulaan ang hinaharap ay isang mahalagang bahagi ng kamalayan, kung wala ang buhay ng tao mismo ay imposible.
Ang konsepto ng "pagtataya" (mula sa Greek. prognosis - foresight, prediction) ay nangangahulugan ng proseso ng pagbuo ng probabilistikong paghuhusga tungkol sa estado ng isang phenomenon o proseso sa hinaharap, ito ay ang kaalaman sa kung ano ang hindi pa, ngunit kung ano ang maaaring dumating sa malapit o malayong hinaharap.
Ang nilalaman ng hula ay mas kumplikado kaysa sa hula. Sa isang banda, sinasalamin nito ang pinaka-malamang na estado ng bagay, at sa kabilang banda, tinutukoy nito ang mga paraan at paraan upang makamit ang ninanais na resulta. Sa batayan ng impormasyong nakuha sa isang predictive na paraan, ang ilang mga desisyon ay ginawa upang makamit ang ninanais na layunin.
Dapat pansinin na ang dinamika ng mga prosesong pang-ekonomiya sa modernong kondisyon nailalarawan sa pamamagitan ng kawalang-tatag at kawalan ng katiyakan, na nagpapahirap sa paggamit ng mga tradisyonal na pamamaraan ng pagtataya.
Exponential Smoothing at Prediction Models nabibilang sa klase ng mga pamamaraan ng adaptive na pagtataya, ang pangunahing katangian kung saan ay ang kakayahang patuloy na isaalang-alang ang ebolusyon ng mga dinamikong katangian ng mga prosesong pinag-aaralan, umangkop sa dinamikong ito, na nagbibigay, sa partikular, ang mas malaki ang timbang at ang mas mataas ang halaga ng impormasyon ng mga magagamit na obserbasyon, mas malapit ang mga ito sa kasalukuyang sandali sa oras . Ang kahulugan ng termino ay nagbibigay-daan sa iyo ang adaptive forecasting na i-update ang mga pagtataya na may kaunting pagkaantala at paggamit ng medyo simpleng mga pamamaraan sa matematika.
Ang exponential smoothing method ay malayang natuklasan kayumanggi(Brown R.G. Statistical forecasting para sa inventory control, 1959) at Holt(Holt C.C. Forecasting Seasonal and Trends by Exponentially Weighted Moving Averages, 1957). Ang exponential smoothing, tulad ng moving average na paraan, ay gumagamit ng mga nakaraang halaga ng serye ng oras para sa pagtataya.
Ang kakanyahan ng exponential smoothing na paraan ay ang serye ng oras ay pinapakinis gamit ang weighted moving average, kung saan ang mga timbang ay sumusunod sa exponential law. Ang isang weighted moving average na may exponentially distributed weights ay nagpapakilala sa halaga ng proseso sa dulo ng smoothing interval, iyon ay, ito ay ang average na katangian ng mga huling antas ng serye. Ito ang ari-arian na ginagamit para sa pagtataya.
Ang normal na exponential smoothing ay inilalapat kapag walang trend o seasonality sa data. Sa kasong ito, ang hula ay isang weighted average ng lahat ng available na nakaraang mga halaga ng serye; sa kasong ito, ang mga timbang ay bumababa nang geometriko sa paglipas ng panahon habang lumilipat tayo sa nakaraan (paatras). Samakatuwid (hindi tulad ng moving average na paraan) walang punto kung saan ang mga timbang ay masira, ibig sabihin, zero. Ang isang pragmatically malinaw na modelo ng simpleng exponential smoothing ay maaaring isulat tulad ng sumusunod (lahat ng mga formula ng artikulo ay maaaring ma-download mula sa link na ibinigay):
Ipakita natin ang exponential na katangian ng pagbaba sa mga bigat ng mga halaga ng serye ng oras - mula sa kasalukuyan hanggang sa nakaraan, mula sa nakaraan hanggang sa nakaraan-nakaraan, at iba pa:
Kung ang formula ay inilapat nang recursively, ang bawat bagong smoothed value (na isa ring hula) ay kalkulahin bilang weighted average ng kasalukuyang obserbasyon at ang smoothed series. Malinaw, ang resulta ng smoothing ay depende sa adaptation parameter alpha. Maaari itong bigyang-kahulugan bilang isang kadahilanan ng diskwento na nagpapakilala sa sukatan ng pagbabawas ng data sa bawat yunit ng oras. Bukod dito, ang impluwensya ng data sa forecast ay bumababa nang malaki sa "edad" ng data. Depende sa impluwensya ng data sa forecast sa iba't ibang coefficient alpha ipinapakita sa Figure 1.

Figure 1. Depende sa impluwensya ng data sa forecast para sa iba't ibang adaptation coefficient
Dapat tandaan na ang halaga ng smoothing parameter ay hindi maaaring katumbas ng 0 o 1, dahil sa kasong ito ang mismong ideya ng exponential smoothing ay tinanggihan. Kaya kung alpha katumbas ng 1, pagkatapos ay ang hinulaang halaga F t+1 tumutugma sa kasalukuyang halaga ng row Xt, habang ang exponential model ay may posibilidad sa pinakasimpleng "muwang-muwang" na modelo, iyon ay, sa kasong ito, ang pagtataya ay isang ganap na walang kuwentang proseso. Kung ang alpha katumbas ng 0, pagkatapos ay ang paunang halaga ng pagtataya F0 (paunang halaga) ay sabay na magiging isang pagtataya para sa lahat ng kasunod na mga sandali ng serye, iyon ay, ang pagtataya sa kasong ito ay magmumukhang isang regular na pahalang na linya.
Gayunpaman, isaalang-alang natin ang mga variant ng smoothing parameter na malapit sa 1 o 0. Kaya, kung alpha malapit sa 1, pagkatapos ay ang mga nakaraang obserbasyon ng serye ng oras ay halos ganap na hindi pinansin. Kung alpha malapit sa 0, pagkatapos ay binabalewala ang kasalukuyang mga obserbasyon. Mga halaga alpha sa pagitan ng 0 at 1 ay nagbibigay ng mga intermediate na resulta. Ayon sa ilang mga may-akda, ang pinakamainam na halaga alpha ay nasa hanay mula 0.05 hanggang 0.30. Gayunpaman, kung minsan alpha, higit sa 0.30 ay nagbibigay ng mas mahusay na hula.
Sa pangkalahatan, mas mahusay na suriin ang pinakamainam alpha batay sa raw data (gamit ang grid search), sa halip na gumamit ng mga artipisyal na rekomendasyon. Gayunpaman, kung ang halaga alpha, mas malaki sa 0.3 ang nagpapaliit ng bilang ng mga espesyal na pamantayan, ito ay nagpapahiwatig na ang isa pang diskarte sa pagtataya (gamit ang isang trend o seasonality) ay nakakapagbigay ng mas tumpak na mga resulta. Upang mahanap ang pinakamainam na halaga alpha(iyon ay, pag-minimize ng mga espesyal na pamantayan) ay ginagamit quasi-Newtonian likelihood-maximization algorithm(probability), na mas mahusay kaysa sa karaniwang enumeration sa grid.
Isulat muli natin ang equation (1) sa anyo ng alternatibong variant na nagbibigay-daan sa atin na suriin kung paano "natututo" ang exponential smoothing model mula sa mga nakaraang pagkakamali nito:
Ang equation (3) ay malinaw na nagpapakita na ang pagtataya para sa panahon t+1 maaaring magbago sa direksyon ng pagtaas, kung sakaling lumampas sa aktwal na halaga ng serye ng oras sa panahon t higit sa halaga ng pagtataya, at kabaliktaran, ang pagtataya para sa panahon t+1 dapat bawasan kung X t mas mababa sa F t.
Tandaan na kapag gumagamit ng exponential smoothing method mahalagang isyu palaging ang pagpapasiya ng mga paunang kundisyon (paunang forecast value F0). Ang proseso ng pagpili ng paunang halaga ng smoothed series ay tinatawag na initialization ( pagsisimula), o, sa madaling salita, “nagpapainit” (“ nagpapainit”) mga modelo. Ang punto ay ang paunang halaga ng smoothed na proseso ay maaaring makabuluhang makaapekto sa forecast para sa mga kasunod na obserbasyon. Sa kabilang banda, ang impluwensya ng pagpili ay bumababa sa haba ng serye at nagiging hindi kritikal para sa napakalaking bilang ng mga obserbasyon. Si Brown ang unang nagmungkahi ng paggamit ng average ng time series bilang panimulang halaga. Iminumungkahi ng ibang mga may-akda na gamitin ang unang aktwal na halaga ng serye ng oras bilang paunang pagtataya.
Sa kalagitnaan ng huling siglo, iminungkahi ni Holt na palawigin ang simpleng exponential smoothing model sa pamamagitan ng pagsasama ng growth factor ( paglago kadahilanan), o kung hindi man ang trend ( salik ng kalakaran). Bilang resulta, ang modelo ng Holt ay maaaring isulat bilang mga sumusunod:
Pinapayagan ka ng pamamaraang ito na isaalang-alang ang presensya sa data linear na kalakaran. Nang maglaon, iminungkahi ang iba pang mga uri ng uso: exponential, damped, atbp.
Mga taglamig iminungkahi na pagbutihin ang modelo ng Holt sa mga tuntunin ng posibilidad na ilarawan ang impluwensya ng mga seasonal na kadahilanan (Winters P.R. Forecasting Sales sa pamamagitan ng Exponentially Weighted Moving Averages, 1960).
Sa partikular, pinalawak pa niya ang modelo ng Holt sa pamamagitan ng pagsasama ng karagdagang equation na naglalarawan sa pag-uugali pana-panahong bahagi(sangkap). Ang sistema ng mga equation ng Winters model ay ang mga sumusunod:
Ang fraction sa unang equation ay nagsisilbing ibukod ang seasonality mula sa orihinal na serye. Pagkatapos ng pagbubukod ng seasonality (ayon sa paraan ng seasonal decomposition Censusako) gumagana ang algorithm sa "purong" data, kung saan walang mga pana-panahong pagbabago. Lumilitaw na ang mga ito sa panghuling pagtataya (15), kapag ang "malinis" na pagtataya, na kinakalkula halos ng pamamaraan ng Holt, ay pinarami ng seasonal na bahagi ( index ng seasonality).
Paksa 3. Pagpapadulas at pagtataya ng mga serye ng oras batay sa mga modelo ng uso
|
pakay ang pag-aaral ng paksang ito ay ang paglikha ng isang pangunahing batayan para sa pagsasanay ng mga tagapamahala sa espesyalidad 080507 sa larangan ng pagbuo ng mga modelo ng iba't ibang mga gawain sa larangan ng ekonomiya, ang pagbuo ng isang sistematikong diskarte sa pagtatakda at paglutas ng mga problema sa pagtataya sa mga mag-aaral. . Ang iminungkahing kurso ay magpapahintulot sa mga espesyalista na mabilis na umangkop sa Praktikal na trabaho, ito ay mas mahusay na mag-navigate sa pang-agham at teknikal na impormasyon at literatura sa espesyalidad, upang gumawa ng mas kumpiyansa na mga desisyon na lumabas sa trabaho. Pangunahing mga gawain Ang pag-aaral ng paksa ay: ang mga mag-aaral na nakakakuha ng malalim na teoretikal na kaalaman sa aplikasyon ng mga modelo ng pagtataya, pagkakaroon ng matatag na kasanayan sa pagsasagawa ng gawaing pananaliksik, ang kakayahang malutas ang mga kumplikadong pang-agham na problema na nauugnay sa mga modelo ng pagbuo, kabilang ang mga multidimensional, ang kakayahang lohikal na pag-aralan ang resultang nakuha at tukuyin ang mga paraan upang makahanap ng mga katanggap-tanggap na solusyon. |
|
|
Tama na simpleng paraan ang pagtukoy sa mga uso sa pag-unlad ay ang pagpapakinis ng serye ng oras, ibig sabihin, ang pagpapalit ng mga aktwal na antas ng mga kinakalkula na may mas maliit na mga pagkakaiba-iba kaysa sa orihinal na data. Ang kaukulang pagbabago ay tinatawag pagsasala. Isaalang-alang natin ang ilang mga paraan ng pagpapakinis.
3.1. simpleng mga average
Ang layunin ng pagpapakinis ay bumuo ng isang modelo ng pagtataya para sa mga hinaharap na panahon batay sa mga nakaraang obserbasyon. Sa pamamaraan ng mga simpleng average, ang mga halaga ng variable ay kinuha bilang paunang data Y sa mga punto sa oras t, at ang halaga ng pagtataya ay tinutukoy bilang isang simpleng average para sa susunod na yugto ng panahon. Ang formula ng pagkalkula ay may form

saan n bilang ng mga obserbasyon.
Sa kaso kapag ang isang bagong obserbasyon ay magagamit, ang bagong natanggap na hula ay dapat ding isaalang-alang para sa pagtataya para sa susunod na panahon. Kapag ginagamit ang pamamaraang ito, ang pagtataya ay isinasagawa sa pamamagitan ng pag-average ng lahat ng nakaraang data, gayunpaman, ang kawalan ng naturang pagtataya ay ang kahirapan ng paggamit nito sa mga modelo ng trend.
3.2. Moving average na paraan
Ang pamamaraang ito ay batay sa pagkatawan sa serye bilang isang kabuuan ng isang medyo maayos na trend at isang random na bahagi. Ang pamamaraan ay batay sa ideya ng pagkalkula ng teoretikal na halaga batay sa isang lokal na pagtatantya. Upang bumuo ng isang pagtatantya ng trend sa isang punto t sa pamamagitan ng mga halaga ng serye mula sa pagitan ng oras kalkulahin ang teoretikal na halaga ng serye. Ang pinaka-kalat na kalat sa pagsasanay ng smoothing serye ay ang kaso kapag ang lahat ng mga timbang para sa mga elemento ng agwat ay pantay sa isa't isa. Para sa kadahilanang ito, ang pamamaraang ito ay tinatawag moving average na pamamaraan, dahil kapag ang pamamaraan ay naisakatuparan, isang window na may lapad ng (2 m + 1) sa buong hilera. Ang lapad ng window ay karaniwang kinukuha na kakaiba, dahil ang teoretikal na halaga ay kinakalkula para sa gitnang halaga: ang bilang ng mga termino k = 2m + 1 na may parehong bilang ng mga antas sa kaliwa at kanan ng sandali t.
Ang formula para sa pagkalkula ng moving average sa kasong ito ay tumatagal ng form:

Ang dispersion ng moving average ay tinukoy bilang σ 2 /k, kung saan saan σ2 nagsasaad ng pagkakaiba-iba ng mga orihinal na termino ng serye, at k smoothing interval, kaya mas malaki ang smoothing interval, mas malakas ang average ng data at mas mababago ang trend. Kadalasan, ginagawa ang smoothing sa tatlo, lima at pitong miyembro ng orihinal na serye. Sa kasong ito, ang mga sumusunod na tampok ng moving average ay dapat isaalang-alang: kung isasaalang-alang namin ang isang serye na may mga pana-panahong pagbabagu-bago ng isang pare-pareho ang haba, pagkatapos ay kapag smoothing batay sa paglipat ng average na may isang smoothing interval katumbas ng o isang maramihang ng panahon. , ang mga pagbabago ay ganap na maaalis. Kadalasan, ang pagpapakinis batay sa isang moving average ay nagpapabago ng serye nang napakalakas na ang natukoy na kalakaran sa pag-unlad ay ipinapakita lamang sa karamihan sa mga pangkalahatang tuntunin, at mas maliit, ngunit mahalaga para sa mga detalye ng pagsusuri (mga alon, liko, atbp.) mawala; pagkatapos ng pagpapakinis, ang maliliit na alon ay maaaring magbago ng direksyon kung minsan sa kabaligtaran na "mga hukay" na lumilitaw sa halip na "mga taluktok", at kabaliktaran. Ang lahat ng ito ay nangangailangan ng pag-iingat sa paggamit ng isang simpleng moving average at pinipilit ang isa na maghanap ng mas banayad na paraan ng paglalarawan.
Ang moving average na paraan ay hindi nagbibigay ng mga halaga ng trend para sa una at huli m mga miyembro ng hilera. Ang pagkukulang na ito ay lalong kapansin-pansin sa kaso kapag ang haba ng hilera ay maliit.
3.3. Exponential Smoothing
Exponential Average y t ay isang halimbawa ng isang asymmetric weighted moving average na isinasaalang-alang ang antas ng pagtanda ng data: "mas lumang" impormasyon na may mas kaunting timbang ay pumapasok sa formula upang kalkulahin ang smoothed na halaga ng antas ng serye
Dito exponential mean na pinapalitan ang naobserbahang halaga ng serye y t(Kasama sa pagpapakinis ang lahat ng data na natanggap hanggang sa kasalukuyang sandali t), α smoothing parameter na nagpapakilala sa bigat ng kasalukuyang (pinakabago) na pagmamasid; 0< α <1.
Ang pamamaraan ay ginagamit upang mahulaan ang hindi nakatigil na serye ng oras na may mga random na pagbabago sa antas at slope. Habang lumalayo tayo mula sa kasalukuyang sandali ng panahon patungo sa nakaraan, ang bigat ng kaukulang termino ng serye ay mabilis na bumababa (exponentially) at halos hindi na magkaroon ng anumang epekto sa halaga ng .
Madaling makita na ang huling kaugnayan ay nagbibigay-daan sa amin na magbigay ng sumusunod na interpretasyon ng exponential average: kung hula ng halaga ng serye y t, kung gayon ang pagkakaiba ay ang error sa pagtataya. Kaya ang hula para sa susunod na punto sa oras t+1 isinasaalang-alang kung ano ang naging kilala sa sandaling ito t error sa pagtataya.
Pagpipilian sa pagpapakinis α ay isang salik sa pagtimbang. Kung α malapit sa pagkakaisa, kung gayon ang pagtataya ay makabuluhang isinasaalang-alang ang laki ng pagkakamali ng huling pagtataya. Para sa maliliit na halaga α ang hinulaang halaga ay malapit sa nakaraang hula. Ang pagpili ng smoothing parameter ay isang medyo kumplikadong problema. Ang mga pangkalahatang pagsasaalang-alang ay ang mga sumusunod: ang pamamaraan ay mabuti para sa paghula ng sapat na maayos na serye. Sa kasong ito, ang isa ay maaaring pumili ng isang smoothing constant sa pamamagitan ng pagliit ng one-step-ahead na error sa paghula na tinantya mula sa huling ikatlong bahagi ng serye. Ang ilang mga eksperto ay hindi inirerekomenda ang paggamit ng malalaking halaga ng smoothing parameter. Sa fig. 3.1 ay nagpapakita ng isang halimbawa ng isang smoothed series gamit ang exponential smoothing method para sa α= 0,1.

kanin. 3.1. Ang resulta ng exponential smoothing sa α
=0,1
(1 orihinal na serye; 2 pinakinis na serye; 3 nalalabi)
3.4. Exponential Smoothing
batay sa trend (Holt method)
Isinasaalang-alang ng pamamaraang ito ang lokal na linear na trend na umiiral sa serye ng oras. Kung mayroong isang pataas na trend sa serye ng oras, pagkatapos kasama ang isang pagtatantya ng kasalukuyang antas, isang pagtatantya ng slope ay kinakailangan din. Sa pamamaraan ng Holt, ang mga halaga ng antas at slope ay direktang pinapakinis sa pamamagitan ng paggamit ng iba't ibang mga constant para sa bawat isa sa mga parameter. Nagbibigay-daan sa iyo ang mga smoothing constant na matantya ang kasalukuyang antas at slope, na pinipino ang mga ito sa tuwing may gagawing mga bagong obserbasyon.
Ang paraan ng Holt ay gumagamit ng tatlong mga formula ng pagkalkula:
- Exponentially Smoothed Series (Kasalukuyang Pagtantya ng Antas)
(3.2) |
- Pagsusuri ng kalakaran
(3.3) |
- Pagtataya para sa R mga panahon sa hinaharap
|
(3.4) |
saan α, β smoothing constants mula sa pagitan.
Ang equation (3.2) ay katulad ng Equation (3.1) para sa simpleng exponential smoothing maliban sa trending term. pare-pareho β kailangan para maayos ang pagtatantya ng trend. Sa forecast equation (3.3), ang pagtatantya ng trend ay pinarami ng bilang ng mga panahon R, kung saan nakabatay ang hula, at pagkatapos ay idinagdag ang produktong ito sa kasalukuyang antas ng pinakinis na data.
Permanente α at β ay pinili nang suhetibo o sa pamamagitan ng pagliit ng error sa hula. Ang mas malaking halaga ng mga timbang ay kinuha, ang mas mabilis na tugon sa patuloy na mga pagbabago ay magaganap at ang data ay magiging mas makinis. Ang mas maliliit na timbang ay ginagawang mas flat ang istraktura ng mga pinakinis na halaga.
Sa fig. Ang 3.2 ay nagpapakita ng isang halimbawa ng pagpapakinis ng isang serye gamit ang paraan ng Holt para sa mga halaga α at β katumbas ng 0.1.

kanin. 3.2. Holt smoothing resulta
sa α
= 0,1
at β
= 0,1
3.5. Exponential Smoothing na may Trend at Seasonal Variation (Winters Method)
Kung may mga pana-panahong pagbabago sa istraktura ng data, ang tatlong-parameter na exponential smoothing na modelo na iminungkahi ni Winters ay ginagamit upang bawasan ang mga error sa pagtataya. Ang diskarte na ito ay isang extension ng nakaraang modelo ng Holt. Upang isaalang-alang ang mga pana-panahong pagkakaiba-iba, isang karagdagang equation ang ginagamit dito, at ang paraang ito ay ganap na inilalarawan ng apat na equation:
- Exponentially Smoothed Series
|
(3.5) |

- Pagsusuri ng kalakaran
(3.6) |
- Pagsusuri ng seasonality
|
(3.7) |
 .
.
- Pagtataya para sa R mga panahon sa hinaharap
(3.8) |
saan α, β, γ patuloy na pagpapakinis para sa antas, takbo at pana-panahon, ayon sa pagkakabanggit; s- ang tagal ng panahon ng seasonal fluctuation.
Itinatama ng equation (3.5) ang smoothed series. Sa equation na ito, isinasaalang-alang ng termino ang seasonality sa orihinal na data. Matapos isaalang-alang ang seasonality at trend sa mga equation (3.6), (3.7), ang mga pagtatantya ay pinakinis, at isang pagtataya ay ginawa sa equation (3.8).
Tulad ng sa nakaraang pamamaraan, ang mga timbang α, β, γ maaaring mapili nang subjective o sa pamamagitan ng pagliit ng error sa hula. Bago ilapat ang equation (3.5), kinakailangan upang matukoy ang mga paunang halaga para sa smoothed series L t, uso T t, seasonality coefficients S t. Karaniwan, ang paunang halaga ng smoothed series ay kinukuha na katumbas ng unang obserbasyon, pagkatapos ay ang trend ay zero, at ang mga seasonal coefficient ay itinakda na katumbas ng isa.
Sa fig. Ang 3.3 ay nagpapakita ng isang halimbawa ng pagpapakinis ng isang serye gamit ang pamamaraang Winters.

kanin. 3.3. Ang resulta ng pagpapakinis ng paraan ng Winters
sa α
= 0,1
;β
= 0.1; γ = 0.1(1- orihinal na hilera; 2 pinakinis na hilera; 3 nalalabi)
3.6. Pagtataya batay sa mga modelo ng trend
Kadalasan, ang mga serye ng oras ay may linear na trend (trend). Kung ipagpalagay ang isang linear na trend, kailangan mong bumuo ng isang tuwid na linya na pinakatumpak na magpapakita ng pagbabago sa dynamics sa panahon na isinasaalang-alang. Mayroong ilang mga pamamaraan para sa pagbuo ng isang tuwid na linya, ngunit ang pinaka-layunin mula sa isang pormal na punto ng view ay isang konstruksiyon batay sa pagliit ng kabuuan ng mga negatibo at positibong paglihis ng mga paunang halaga ng serye mula sa isang tuwid na linya.
Isang tuwid na linya sa isang two-coordinate system (x, y) maaaring tukuyin bilang ang intersection point ng isa sa mga coordinate sa at ang anggulo ng pagkahilig sa axis X. Ang equation para sa tulad ng isang tuwid na linya ay magiging ganito ![]() saan a- intersection point; b nakatabinging anggulo.
saan a- intersection point; b nakatabinging anggulo.
Upang maipakita ng tuwid na linya ang kurso ng dinamika, kinakailangan upang mabawasan ang kabuuan ng mga vertical deviations. Kapag ginagamit bilang isang criterion para sa pagtatantya ng pagliit ng isang simpleng kabuuan ng mga paglihis, ang resulta ay hindi magiging napakahusay, dahil ang mga negatibo at positibong paglihis ay magkakansela sa isa't isa. Ang pag-minimize sa kabuuan ng mga ganap na halaga ay hindi rin humahantong sa mga kasiya-siyang resulta, dahil ang mga pagtatantya ng parameter sa kasong ito ay hindi matatag, mayroon ding mga paghihirap sa pagkalkula sa pagpapatupad ng naturang pamamaraan ng pagtatantya. Samakatuwid, ang pinakakaraniwang ginagamit na pamamaraan ay upang mabawasan ang kabuuan ng mga squared deviations, o hindi bababa sa parisukat na pamamaraan(MNK).
Dahil ang mga serye ng mga paunang halaga ay may mga pagbabago-bago, ang modelo ng serye ay maglalaman ng mga error, ang mga parisukat na dapat mabawasan

kung saan y naobserbahan ko ang halaga; y i * mga teoretikal na halaga ng modelo; numero ng pagmamasid.
Kapag nagmomodelo ng trend ng orihinal na serye ng oras gamit ang isang linear na trend, ipagpalagay namin iyon
Hinahati ang unang equation sa pamamagitan ng n, dumating kami sa susunod
![]()
Ang pagpapalit ng resultang expression sa pangalawang equation ng system (3.10), para sa coefficient b* makuha namin:

3.7. Pagsusuri ng pagkakasya ng modelo
Bilang halimbawa, sa fig. Ang 3.4 ay nagpapakita ng isang graph ng linear regression sa pagitan ng kapangyarihan ng kotse X at ang gastos nito sa.

kanin. 3.4. Linear regression plot
Ang equation para sa kasong ito ay: sa=1455,3 + 13,4 X. Ang visual na pagsusuri ng figure na ito ay nagpapakita na para sa isang bilang ng mga obserbasyon mayroong mga makabuluhang deviations mula sa theoretical curve. Ang natitirang graph ay ipinapakita sa Fig. 3.5.

kanin. 3.5. Tsart ng nalalabi
Ang pagsusuri sa mga natitirang linya ng regression ay maaaring magbigay ng isang kapaki-pakinabang na sukatan kung gaano kahusay na ipinapakita ng tinantyang regression ang totoong data. Ang isang mahusay na regression ay isa na nagpapaliwanag ng isang malaking halaga ng pagkakaiba-iba at, sa kabaligtaran, ang isang masamang regression ay hindi sinusubaybayan ang isang malaking halaga ng pagbabagu-bago sa orihinal na data. Malinaw na malinaw na ang anumang karagdagang impormasyon ay magpapahusay sa modelo, ibig sabihin, bawasan ang hindi maipaliwanag na bahagi ng pagkakaiba-iba ng variable. sa. Upang pag-aralan ang regression, ibubulok namin ang pagkakaiba sa mga bahagi. Obvious naman yun
Ang huling termino ay magiging katumbas ng zero, dahil ito ang kabuuan ng mga natitira, kaya dumating tayo sa sumusunod na resulta
saan SS0, SS1, SS2 tukuyin ang kabuuan, regression at natitirang kabuuan ng mga parisukat, ayon sa pagkakabanggit.
Ang regression sum ng mga parisukat ay sumusukat sa bahagi ng pagkakaiba na ipinaliwanag ng isang linear na relasyon; natitirang bahagi ng dispersion, hindi ipinaliwanag ng isang linear na pag-asa.
Ang bawat isa sa mga kabuuan na ito ay nailalarawan sa pamamagitan ng katumbas na bilang ng mga antas ng kalayaan (HR), na tumutukoy sa bilang ng mga yunit ng data na independyente sa bawat isa. Sa madaling salita, ang rate ng puso ay nauugnay sa bilang ng mga obserbasyon n at ang bilang ng mga parameter na kinakalkula mula sa kabuuan ng mga parameter na ito. Sa kasong isinasaalang-alang, upang makalkula SS0 isang pare-pareho lamang (average na halaga) ang tinutukoy, samakatuwid ang tibok ng puso para sa SS0 magiging (n– 1), rate ng puso para sa SS 2 - (n - 2) at tibok ng puso para sa SS 1 magiging n - (n - 1)=1, dahil mayroong n - 1 pare-parehong puntos sa equation ng regression. Tulad ng mga kabuuan ng mga parisukat, ang mga rate ng puso ay nauugnay sa
![]()
Ang mga kabuuan ng mga parisukat na nauugnay sa agnas ng pagkakaiba, kasama ang kaukulang mga rate ng puso, ay maaaring ilagay sa tinatawag na talahanayan ng pagsusuri ng pagkakaiba (ANOVA ANalysis Of VAriance table) (Talahanayan 3.1).
Talahanayan 3.1
talahanayan ng ANOVA
Pinagmulan |
Kabuuan ng mga parisukat |
Gitnang parisukat |
|
Regression |
SS2/ (n-2) |
Gamit ang ipinakilala na pagdadaglat para sa mga kabuuan ng mga parisukat, tinutukoy namin koepisyent ng determinasyon bilang ang ratio ng regression sum ng mga parisukat sa kabuuang kabuuan ng mga parisukat bilang
|
(3.13) |
Ang coefficient of determination ay sumusukat sa proporsyon ng variability sa isang variable Y, na maaaring ipaliwanag gamit ang impormasyon tungkol sa pagkakaiba-iba ng malayang baryabol x. Ang determination coefficient ay nagbabago mula sa zero kapag X hindi nakakaapekto Y, sa isa kapag ang pagbabago Y ganap na ipinaliwanag sa pamamagitan ng pagbabago x.
3.8. Regression Forecast Model
Ang pinakamahusay na hula ay ang may pinakamaliit na pagkakaiba. Sa aming kaso, ang mga karaniwang hindi bababa sa mga parisukat ay gumagawa ng pinakamahusay na hula sa lahat ng mga pamamaraan na nagbibigay ng walang pinapanigan na mga pagtatantya batay sa mga linear na equation. Ang error sa pagtataya na nauugnay sa pamamaraan ng pagtataya ay maaaring magmula sa apat na mapagkukunan.
Una, ang random na katangian ng mga additive error na pinangangasiwaan ng linear regression ay nagsisiguro na ang forecast ay lilihis mula sa mga tunay na halaga kahit na ang modelo ay wastong tinukoy at ang mga parameter nito ay tiyak na kilala.
Pangalawa, ang proseso ng pagtatantya mismo ay nagpapakilala ng isang error sa pagtatantya ng mga parameter na bihira silang maging katumbas ng mga tunay na halaga, bagama't sila ay katumbas ng mga ito sa karaniwan.
Pangatlo, sa kaso ng isang conditional forecast (sa kaso ng hindi kilalang eksaktong mga halaga ng mga independiyenteng variable), ang error ay ipinakilala sa pagtataya ng mga paliwanag na variable.
Ikaapat, maaaring lumitaw ang error dahil hindi tumpak ang detalye ng modelo.
Bilang resulta, ang mga pinagmumulan ng error ay maaaring uriin bilang mga sumusunod:
- ang likas na katangian ng variable;
- ang likas na katangian ng modelo;
- ang error na ipinakilala ng pagtataya ng mga independiyenteng random na variable;
- error sa pagtutukoy.
Isasaalang-alang namin ang isang walang kundisyong pagtataya, kapag ang mga independyenteng variable ay madali at tumpak na hinulaan. Sinisimulan namin ang aming pagsasaalang-alang sa problema sa kalidad ng pagtataya sa ipinares na equation ng regression.
![]()
Ang pahayag ng problema sa kasong ito ay maaaring mabalangkas tulad ng sumusunod: ano ang magiging pinakamahusay na pagtataya y T+1, sa kondisyon na sa modelo y = a + bx mga pagpipilian a at b eksaktong tinantiya, at ang halaga xT+1 kilala.
Pagkatapos ang hinulaang halaga ay maaaring tukuyin bilang
Ang error sa pagtataya ay magiging
![]() .
.
Ang error sa pagtataya ay may dalawang katangian:
Ang resultang pagkakaiba ay minimal sa lahat ng posibleng pagtatantya batay sa mga linear na equation.
Bagaman a at b ay kilala, lumilitaw ang error sa pagtataya dahil sa katotohanang iyon sa T+1 maaaring hindi magsinungaling sa linya ng regression dahil sa isang error ε T+1, pagsunod sa isang normal na distribusyon na may zero mean at variance σ2. Upang suriin ang kalidad ng forecast, ipinakilala namin ang normalized na halaga

Ang 95% na agwat ng kumpiyansa ay maaaring tukuyin tulad ng sumusunod:

saan β 0.05 dami ng normal na distribusyon.
Ang mga hangganan ng 95% na pagitan ay maaaring tukuyin bilang
Tandaan na sa kasong ito ang lapad ng agwat ng kumpiyansa ay hindi nakasalalay sa halaga X, at ang mga hangganan ng pagitan ay mga tuwid na linya parallel sa mga linya ng regression.
Mas madalas, kapag gumagawa ng isang linya ng regression at sinusuri ang kalidad ng forecast, kinakailangang suriin hindi lamang ang mga parameter ng regression, kundi pati na rin ang pagkakaiba-iba ng error sa forecast. Maaaring ipakita na sa kasong ito ang pagkakaiba-iba ng error ay nakasalalay sa halaga (), kung saan ang ibig sabihin ng halaga ng malayang variable. Bilang karagdagan, kung mas mahaba ang serye, mas tumpak ang hula. Bumababa ang error sa pagtataya kung ang value ng X T+1 ay malapit sa mean value ng independent variable, at, sa kabaligtaran, kapag lumalayo sa mean value, nagiging hindi gaanong tumpak ang forecast. Sa fig. Ipinapakita ng 3.6 ang mga resulta ng hula gamit ang linear regression equation para sa 6 na agwat ng oras sa unahan kasama ang mga agwat ng kumpiyansa.

kanin. 3.6. Linear Regression Prediction
Gaya ng makikita sa fig. 3.6, ang linya ng regression na ito ay hindi naglalarawan nang maayos sa orihinal na data: mayroong malaking pagkakaiba-iba na nauugnay sa angkop na linya. Ang kalidad ng modelo ay maaari ding hatulan ng mga nalalabi, na, na may kasiya-siyang modelo, ay dapat na ipamahagi nang humigit-kumulang ayon sa normal na batas. Sa fig. Ang 3.7 ay nagpapakita ng graph ng mga residual, na binuo gamit ang probability scale.

Fig.3.7. Tsart ng nalalabi
Kapag gumagamit ng ganoong sukat, ang data na sumusunod sa normal na batas ay dapat na nasa isang tuwid na linya. Tulad ng sumusunod mula sa figure, ang mga punto sa simula at pagtatapos ng panahon ng pagmamasid ay medyo lumihis mula sa isang tuwid na linya, na nagpapahiwatig ng isang hindi sapat na mataas na kalidad ng napiling modelo sa anyo ng isang linear regression equation.
Sa mesa. Ipinapakita ng talahanayan 3.2 ang mga resulta ng pagtataya (ikalawang column) kasama ang 95% na agwat ng kumpiyansa (ibabang pangatlo at pang-apat na column sa itaas, ayon sa pagkakabanggit).
Talahanayan 3.2
Mga resulta ng pagtataya

3.9. Multivariate na modelo ng regression
Sa multivariate regression, ang data para sa bawat kaso ay kinabibilangan ng mga halaga ng dependent variable at bawat independent variable. Dependent variable y ay isang random na variable na nauugnay sa mga independiyenteng variable sa pamamagitan ng sumusunod na relasyon:
kung saan ang mga coefficient ng regression ay matutukoy; ε bahagi ng error na naaayon sa paglihis ng mga halaga ng dependent variable mula sa totoong ratio (pinapalagay na ang mga error ay independyente at may normal na distribusyon na may zero mean at hindi kilalang pagkakaiba-iba σ ).
Para sa isang naibigay na dataset, ang mga pagtatantya ng mga coefficient ng regression ay matatagpuan gamit ang least squares na paraan. Kung ang mga pagtatantya ng OLS ay tinutukoy ng , ang kaukulang regression function ay magiging ganito:
Ang mga nalalabi ay mga pagtatantya ng bahagi ng error at katulad ng mga nalalabi sa kaso ng simpleng linear regression.
Ang pagtatasa ng istatistika ng isang multivariate na modelo ng regression ay isinasagawa katulad ng pagsusuri ng isang simpleng linear regression. Ginagawang posible ng mga karaniwang pakete ng mga programang pang-istatistika na makakuha ng mga pagtatantya ng hindi bababa sa mga parisukat para sa mga parameter ng modelo, mga pagtatantya ng kanilang mga karaniwang error. Gayundin, maaari mong makuha ang halaga t-statistics upang suriin ang kahalagahan ng mga indibidwal na termino ng modelo ng regression at ang halaga F-mga istatistika upang subukan ang kahalagahan ng pag-asa sa regression.
Ang anyo ng paghahati ng mga kabuuan ng mga parisukat sa kaso ng multivariate regression ay katulad ng expression (3.13), ngunit ang ratio para sa rate ng puso ay ang mga sumusunod
Muli naming idiniin iyon n ay ang dami ng mga obserbasyon, at k bilang ng mga variable sa modelo. Ang kabuuang pagkakaiba ng dependent variable ay binubuo ng dalawang bahagi: ang variance na ipinaliwanag ng mga independent variable sa pamamagitan ng regression function at ang unexplained variance.
Ang Table ANOVA para sa kaso ng multivariate regression ay magkakaroon ng form na ipinapakita sa Table. 3.3.
Talahanayan 3.3
talahanayan ng ANOVA
Pinagmulan |
Kabuuan ng mga parisukat |
Gitnang parisukat |
|
Regression |
SS2/ (n-k-1) |
Bilang isang halimbawa ng multivariate regression, gagamitin namin ang data mula sa Statistica package (data file Kahirapan.Sta) Ang data na ipinakita ay batay sa isang paghahambing ng mga resulta ng 1960 at 1970 censuses. para sa random na sample ng 30 bansa. Ang mga pangalan ng bansa ay nailagay bilang mga pangalan ng string, at ang mga pangalan ng lahat ng mga variable sa file na ito ay nakalista sa ibaba:
POP_CHNG pagbabago ng populasyon para sa 1960-1970;
N_EMPLD ang bilang ng mga taong nagtatrabaho sa agrikultura;
PT_POOR na porsyento ng mga pamilyang nabubuhay sa ilalim ng linya ng kahirapan;
TAX_RATE rate ng buwis;
PT_PHONE na porsyento ng mga apartment na may telepono;
PT_RURAL na porsyento ng populasyon sa kanayunan;
AGE gitnang edad.
Bilang dependent variable, pipiliin namin ang feature Pt_Mahina, at bilang independiyente - lahat ng iba pa. Ang mga nakalkulang coefficient ng regression sa pagitan ng mga napiling variable ay ibinibigay sa Talahanayan. 3.4
Talahanayan 3.4
Regression Coefficients

Ipinapakita ng talahanayang ito ang mga coefficient ng regression ( AT) at standardized regression coefficients ( beta). Sa tulong ng mga coefficient AT ang anyo ng equation ng regression ay nakatakda, na sa kasong ito ay may anyo:
Ang pagsasama sa kanang bahagi lamang ng mga variable na ito ay dahil sa katotohanang ang mga feature na ito lang ang may probability value R mas mababa sa 0.05 (tingnan ang ikaapat na hanay ng Talahanayan 3.4).
Bibliograpiya
- Basovsky L. E. Pagtataya at pagpaplano sa mga kondisyon ng merkado. - M .: Infra - M, 2003.
- Box J., Jenkins G. Pagsusuri ng serye ng oras. Isyu 1. Pagtataya at pamamahala. – M.: Mir, 1974.
- Borovikov V. P., Ivchenko G. I. Pagtataya sa Statistica system sa kapaligiran ng Windows. - M.: Pananalapi at istatistika, 1999.
- Duke W. Pagproseso ng data sa isang PC sa mga halimbawa. - St. Petersburg: Peter, 1997.
- Ivchenko B. P., Martyshchenko L. A., Ivantsov I. B. Microeconomics ng impormasyon. Bahagi 1. Paraan ng pagsusuri at pagtataya. - St. Petersburg: Nordmed-Izdat, 1997.
- Krichevsky M. L. Panimula sa mga artipisyal na neural network: Proc. allowance. - St. Petersburg: St. Petersburg. estado marine tech. un-t, 1999.
- Soshnikova L. A., Tamashevich V. N., Uebe G. et al. Multivariate statistical analysis sa economics. – M.: Unity-Dana, 1999.
Ang isang simple at lohikal na malinaw na modelo ng serye ng oras ay may sumusunod na anyo:
saan b ay isang pare-pareho, at ε - random na error. pare-pareho b medyo matatag sa bawat agwat ng oras, ngunit maaari ring magbago nang dahan-dahan sa paglipas ng panahon. Isa sa mga intuitive na paraan upang kunin ang isang halaga b mula sa data ay ang paggamit ng moving average smoothing, kung saan ang mga pinakabagong obserbasyon ay mas natimbang kaysa sa mga penultimate, ang mga penultimate ay mas natimbang kaysa sa mga penultimate, at iba pa. Simple exponential smoothing lang yan. Dito, ang exponentially decreasing weights ay itinalaga sa mas lumang mga obserbasyon, habang, hindi katulad ng moving average, lahat ng nakaraang obserbasyon ng serye ay isinasaalang-alang, at hindi lamang ang mga nahulog sa isang partikular na window. Ang eksaktong formula para sa simpleng exponential smoothing ay:
Kapag ang formula na ito ay inilapat nang recursively, ang bawat bagong smoothed value (na isa ring hula) ay kinakalkula bilang weighted average ng kasalukuyang obserbasyon at ang smoothed series. Malinaw, ang resulta ng smoothing ay depende sa parameter α . Kung ang α ay 1, ang mga nakaraang obserbasyon ay ganap na binabalewala. Kung ang a ay 0, ang kasalukuyang mga obserbasyon ay binabalewala. Mga halaga α sa pagitan ng 0 at 1 ay nagbibigay ng mga intermediate na resulta. Ipinakita ng mga empirical na pag-aaral na ang isang simpleng exponential smoothing ay kadalasang nagbibigay ng medyo tumpak na hula.
Sa pagsasagawa, kadalasang inirerekomenda na kunin α mas mababa sa 0.30. Gayunpaman, ang pagpili ng mas mataas sa 0.30 kung minsan ay nagbibigay ng mas tumpak na hula. Nangangahulugan ito na mas mahusay na tantyahin ang pinakamainam na halaga α sa totoong data kaysa gumamit ng mga pangkalahatang rekomendasyon.
Sa pagsasagawa, ang pinakamainam na parameter ng smoothing ay madalas na hinahanap gamit ang isang grid search procedure. Ang posibleng hanay ng mga halaga ng parameter ay nahahati sa isang grid na may isang tiyak na hakbang. Halimbawa, isaalang-alang ang isang grid ng mga halaga mula sa α =0.1 hanggang α = 0.9 na may hakbang na 0.1. Pagkatapos ay pinili ang halaga α , kung saan ang kabuuan ng mga parisukat (o ibig sabihin ng mga parisukat) ng mga nalalabi (mga sinusunod na halaga ay binawasan ang mga hula bawat hakbang pasulong) ay minimal.
Ang Microsoft Excel ay nagbibigay ng Exponential Smoothing function, na karaniwang ginagamit upang pakinisin ang mga antas ng isang empirical time series batay sa simpleng exponential smoothing na paraan. Para tawagan ang function na ito, piliin ang Tools - Data Analysis mula sa menu bar. Magbubukas ang window ng Data Analysis sa screen, kung saan dapat mong piliin ang Exponential smoothing value. Bilang resulta, lilitaw ang isang dialog box. Exponential Smoothing ipinapakita sa fig. 11.5.

Sa dialog box ng Exponential Smoothing, halos pareho ang mga parameter na itinakda tulad ng sa Moving Average na dialog box na tinalakay sa itaas.
1. Input Range (Input data) - sa field na ito, isang hanay ng mga cell na naglalaman ng mga halaga ng parameter na pinag-aaralan ay ipinasok.
2. Mga Label (Mga Label) - ang flag ng opsyong ito ay nakatakda kung ang unang hilera (column) sa saklaw ng input ay naglalaman ng pamagat. Kung nawawala ang header, dapat i-clear ang checkbox. Sa kasong ito, awtomatikong mabubuo ang mga karaniwang pangalan para sa data ng saklaw ng output.
3. Damping factor - ilagay ang halaga ng napiling exponential smoothing factor sa field na ito α . Ang default na halaga ay α = 0,3.
4. Mga opsyon sa output - sa pangkat na ito, bilang karagdagan sa pagtukoy ng hanay ng mga cell para sa output data sa Output Range field, maaari mo ring hilingin na awtomatikong mag-plot ng isang graph, kung saan kailangan mong suriin ang pagpipiliang Output ng Tsart, at kalkulahin ang pamantayan mga error sa pamamagitan ng pagsuri sa opsyong Standard Errors.
Gamitin natin ang function Exponential Smoothing upang muling malutas ang problema sa itaas, ngunit gamit ang paraan ng simpleng exponential smoothing. Ang mga napiling halaga ng mga parameter ng smoothing ay ipinapakita sa fig. 11.5. Sa fig. Ipinapakita ng 11.6 ang kinakalkula na mga tagapagpahiwatig, at sa fig. 11.7 - naka-plot na mga graph.