Ano ang pagkakaiba ng random variable. Isang halimbawa ng paghahanap ng pagkakaiba
Ang pagpapakalat sa mga istatistika ay tinukoy bilang ang karaniwang paglihis ng mga indibidwal na halaga ng isang katangian na nakakuwadrado mula sa arithmetic mean. Isang karaniwang paraan upang kalkulahin ang mga squared deviations ng mga opsyon mula sa mean at pagkatapos ay i-average ang mga ito.
![]()
Sa pagsusuring pang-ekonomiya at istatistika, kaugalian na suriin ang pagkakaiba-iba ng isang tampok na pinakamadalas gamit ang karaniwang paglihis, na siyang square root ng variance.
 (3)
(3)
Nailalarawan nito ang ganap na pagbabagu-bago ng mga halaga ng variable na katangian at ipinahayag sa parehong mga yunit bilang mga variant. Sa mga istatistika, madalas na kinakailangan upang ihambing ang pagkakaiba-iba ng iba't ibang mga tampok. Para sa mga naturang paghahambing, ginagamit ang isang kamag-anak na tagapagpahiwatig ng pagkakaiba-iba, ang koepisyent ng pagkakaiba-iba.
Mga katangian ng pagpapakalat:
1) kung ibawas mo ang anumang numero mula sa lahat ng mga pagpipilian, hindi magbabago ang pagkakaiba;
2) kung ang lahat ng mga halaga ng variant ay hinati sa ilang numero b, ang pagkakaiba ay bababa ng b^2 beses, i.e.
3) kung kalkulahin mo ang average na parisukat ng mga deviations mula sa anumang numero na may hindi pantay na arithmetic mean, kung gayon ito ay mas malaki kaysa sa pagkakaiba. Sa kasong ito, sa pamamagitan ng isang mahusay na tinukoy na halaga sa bawat parisukat ng pagkakaiba sa pagitan ng average na halaga ng pos.
![]()
Ang pagkakaiba ay maaaring tukuyin bilang pagkakaiba sa pagitan ng mean squared at mean squared.
17. Mga pagkakaiba-iba ng grupo at intergroup. Panuntunan sa pagdaragdag ng pagkakaiba-iba
Kung ang istatistikal na populasyon ay nahahati sa mga grupo o mga bahagi ayon sa katangian na pinag-aaralan, kung gayon para sa naturang populasyon ang mga sumusunod na uri ng pagpapakalat ay maaaring kalkulahin: pangkat (pribado), average ng grupo (pribado), at intergroup.
Kabuuang pagkakaiba- sumasalamin sa pagkakaiba-iba ng isang katangian dahil sa lahat ng mga kundisyon at sanhi ng paggana sa isang partikular na istatistikal na populasyon. ![]()
Pagkakaiba-iba ng pangkat- ay katumbas ng ibig sabihin ng parisukat ng mga paglihis ng mga indibidwal na halaga ng katangian sa loob ng pangkat mula sa arithmetic mean ng pangkat na ito, na tinatawag na mean ng grupo. Sa kasong ito, ang average ng grupo ay hindi tumutugma sa kabuuang average para sa buong populasyon.
![]()
Ang pagkakaiba-iba ng pangkat ay sumasalamin sa pagkakaiba-iba ng isang katangian dahil lamang sa mga kundisyon at sanhi ng paggana sa loob ng pangkat.
Average na pagkakaiba-iba ng pangkat- ay tinukoy bilang ang weighted arithmetic mean ng mga pagpapakalat ng pangkat, na ang mga timbang ay ang mga volume ng mga pangkat.
pagkakaiba-iba sa pagitan ng pangkat- ay katumbas ng ibig sabihin ng parisukat ng mga paglihis ng ibig sabihin ng pangkat mula sa kabuuang mean.
Inilalarawan ng pagkakaiba-iba ng intergroup ang pagkakaiba-iba ng nagreresultang katangian dahil sa katangian ng pagpapangkat.
Mayroong tiyak na ugnayan sa pagitan ng mga uri ng pagkakaiba-iba na isinasaalang-alang: ang kabuuang pagkakaiba ay katumbas ng kabuuan ng average na pagkakaiba ng pangkat at intergroup.
Ang kaugnayang ito ay tinatawag na panuntunan sa pagdaragdag ng pagkakaiba.
18. Dynamic na serye at mga elementong bumubuo nito. Mga uri ng dynamic na serye.
Serye sa mga istatistika- ito ay mga digital na data na nagpapakita kung ang isang phenomenon ay nagbabago sa oras o espasyo at ginagawang posible na gumawa ng istatistikal na paghahambing ng mga phenomena kapwa sa proseso ng kanilang pag-unlad sa oras at sa iba't ibang anyo at mga uri ng proseso. Salamat sa ito, posible na makita ang mutual dependence ng phenomena.
Ang proseso ng pag-unlad ng paggalaw ng mga social phenomena sa oras sa mga istatistika ay karaniwang tinatawag na dinamika. Upang ipakita ang dynamics, ang mga serye ng mga dinamika (kronolohiko, temporal) ay binuo, na mga serye ng time-varying values ng isang statistical indicator (halimbawa, ang bilang ng mga nahatulan sa loob ng 10 taon), na matatagpuan sa magkakasunod-sunod. Ang kanilang mga sangkap na bumubuo ay ang mga numerical na halaga ng isang naibigay na tagapagpahiwatig at ang mga tuldok o mga punto sa oras na kanilang tinutukoy.
Ang pinakamahalagang katangian ng time series- ang kanilang sukat (volume, halaga) ng ito o ang hindi pangkaraniwang bagay na iyon, na nakamit sa isang tiyak na panahon o sa isang tiyak na sandali. Alinsunod dito, ang magnitude ng mga tuntunin ng serye ng mga dinamika ay ang antas nito. Makilala paunang, gitna at panghuling antas ng dynamic na serye. Unang antas ipinapakita ang halaga ng una, pangwakas - ang halaga ng huling miyembro ng serye. Average na antas kumakatawan sa average na kronolohikal na variational range at kinakalkula depende sa kung ang time series ay interval o instant.
Isa pang mahalagang katangian ng dynamic na serye- ang oras na lumipas mula sa una hanggang sa huling obserbasyon, o ang bilang ng mga naturang obserbasyon.
Mayroong iba't ibang uri ng serye ng oras, maaari silang maiuri ayon sa mga sumusunod na pamantayan.
1) Depende sa paraan ng pagpapahayag ng mga antas, ang serye ng mga dynamics ay nahahati sa serye ng mga absolute at derived indicator (relative at average na mga halaga).
2) Depende sa kung paano ipinapahayag ng mga antas ng serye ang estado ng phenomenon sa ilang partikular na punto ng oras (sa simula ng buwan, quarter, taon, atbp.) o ang halaga nito para sa ilang partikular na agwat ng oras (halimbawa, bawat araw, buwan, taon, atbp.) n.), makilala sa pagitan ng sandali at pagitan ng serye ng mga dinamika, ayon sa pagkakabanggit. Ang mga serye ng sandali sa analytical na gawain ng mga ahensyang nagpapatupad ng batas ay bihirang ginagamit.
Sa teorya ng mga istatistika, ang mga dinamika ay nakikilala din ayon sa ilang iba pang mga tampok ng pag-uuri: depende sa distansya sa pagitan ng mga antas - na may katumbas na mga antas at hindi pantay na mga antas sa oras; depende sa pagkakaroon ng pangunahing trend ng proseso sa ilalim ng pag-aaral - nakatigil at hindi nakatigil. Kapag sinusuri ang mga dynamic na serye, ang mga sumusunod na antas ng serye ay ipinakita bilang mga bahagi:
Y t \u003d TP + E (t)
kung saan ang TR ay isang deterministikong bahagi na tumutukoy sa pangkalahatang trend ng pagbabago sa paglipas ng panahon o isang trend.
Ang E (t) ay isang random na bahagi na nagdudulot ng pagbabagu-bago ng antas.
Pagpapakalat random variable ay isang sukatan ng pagkalat ng mga halaga ng dami na ito. Ang maliit na pagkakaiba-iba ay nangangahulugan na ang mga halaga ay naka-cluster malapit sa isa't isa. Ang isang malaking pagkakaiba ay nagpapahiwatig ng isang malakas na scatter ng mga halaga. Ang konsepto ng pagpapakalat ng isang random na variable ay ginagamit sa mga istatistika. Halimbawa, kung ihahambing mo ang pagkakaiba-iba ng mga halaga ng dalawang dami (tulad ng mga resulta ng mga obserbasyon ng mga pasyenteng lalaki at babae), maaari mong subukan ang kahalagahan ng ilang variable. Ginagamit din ang pagkakaiba-iba kapag gumagawa ng mga istatistikal na modelo, dahil ang maliit na pagkakaiba ay maaaring maging senyales na ikaw ay nag-overfitting sa mga halaga.Mga hakbang
Sample na Pagkalkula ng Variance
-
Itala ang mga sample na halaga. Sa karamihan ng mga kaso, mga sample lang ng ilang partikular na populasyon ang available sa mga statistician. Halimbawa, bilang panuntunan, hindi sinusuri ng mga istatistika ang halaga ng pagpapanatili ng populasyon ng lahat ng mga kotse sa Russia - sinusuri nila ang isang random na sample ng ilang libong mga kotse. Ang ganitong sample ay makakatulong na matukoy ang average na gastos sa bawat kotse, ngunit malamang, ang resultang halaga ay malayo sa tunay.
- Halimbawa, suriin natin ang bilang ng mga bun na ibinebenta sa isang cafe sa loob ng 6 na araw, na kinuha sa random na pagkakasunud-sunod. Ang sample ay may sumusunod na anyo: 17, 15, 23, 7, 9, 13. Isa itong sample, hindi populasyon, dahil wala kaming data sa mga ibinebentang bun para sa bawat araw na bukas ang cafe.
- Kung binigyan ka ng isang populasyon at hindi isang sample ng mga halaga, lumaktaw sa susunod na seksyon.
-
Isulat ang formula para sa pagkalkula ng sample variance. Ang pagpapakalat ay isang sukatan ng pagkalat ng mga halaga ng ilang dami. Kung mas malapit ang halaga ng pagpapakalat sa zero, mas malapit ang mga halaga ay pinagsama-sama. Kapag nagtatrabaho sa isang sample ng mga halaga, gamitin ang sumusunod na formula upang kalkulahin ang pagkakaiba:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2)) ay ang pagpapakalat. Ang dispersion ay sinusukat sa square units.
- x i (\displaystyle x_(i))- bawat halaga sa sample.
- x i (\displaystyle x_(i)) kailangan mong ibawas ang xᅳ, parisukat ito, at pagkatapos ay idagdag ang mga resulta.
- xᅳ – sample mean (sample mean).
- n ay ang bilang ng mga halaga sa sample.
-
Kalkulahin ang sample mean. Ito ay tinutukoy bilang xᅳ. Ang sample mean ay nakalkula tulad ng isang normal na arithmetic mean: idagdag ang lahat ng mga halaga sa sample, at pagkatapos ay hatiin ang resulta sa bilang ng mga halaga sa sample.
- Sa aming halimbawa, idagdag ang mga halaga sa sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
Ngayon hatiin ang resulta sa bilang ng mga halaga sa sample (sa aming halimbawa ay mayroong 6): 84 ÷ 6 = 14.
Halimbawang ibig sabihin xᅳ = 14. - Ang sample mean ay ang sentral na halaga kung saan ipinamamahagi ang mga halaga sa sample. Kung ang mga halaga sa sample cluster sa paligid ng sample ay nangangahulugan, kung gayon ang pagkakaiba ay maliit; kung hindi, ang pagpapakalat ay malaki.
- Sa aming halimbawa, idagdag ang mga halaga sa sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Ibawas ang sample mean sa bawat value sa sample. Ngayon kalkulahin ang pagkakaiba x i (\displaystyle x_(i))- xᅳ, saan x i (\displaystyle x_(i))- bawat halaga sa sample. Ang bawat resulta ay nagpapahiwatig ng antas ng paglihis ng isang partikular na halaga mula sa sample mean, iyon ay, kung gaano kalayo ang halagang ito mula sa sample mean.
- Sa aming halimbawa:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- xᅳ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Ang kawastuhan ng mga resultang nakuha ay madaling i-verify, dahil ang kanilang kabuuan ay dapat na katumbas ng zero. Ito ay nauugnay sa kahulugan ng average na halaga, dahil mga negatibong halaga(mga distansya mula sa karaniwan hanggang sa mas maliliit na halaga) ay ganap na na-offset ng mga positibong halaga (mga distansya mula sa karaniwan hanggang sa mas malalaking halaga).
- Sa aming halimbawa:
-
Tulad ng nabanggit sa itaas, ang kabuuan ng mga pagkakaiba x i (\displaystyle x_(i))- Dapat ay katumbas ng zero ang xᅳ. Ibig sabihin nito ay average na pagkakaiba-iba ay palaging katumbas ng zero, na hindi nagbibigay ng anumang ideya tungkol sa pagkalat ng mga halaga ng isang tiyak na dami. Upang malutas ang problemang ito, parisukat ang bawat pagkakaiba x i (\displaystyle x_(i))- xᅳ. Magreresulta ito sa pagkuha mo lamang mga positibong numero, na kapag idinagdag ay hindi kailanman magbibigay ng 0.
- Sa aming halimbawa:
(x 1 (\displaystyle x_(1))-x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2)))-x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Natagpuan mo ang parisukat ng pagkakaiba - x̅) 2 (\displaystyle ^(2)) para sa bawat halaga sa sample.
- Sa aming halimbawa:
-
Kalkulahin ang kabuuan ng mga squared differences. Iyon ay, hanapin ang bahagi ng formula na nakasulat tulad nito: ∑[( x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))]. Dito ang sign na Σ ay nangangahulugang ang kabuuan ng mga parisukat na pagkakaiba para sa bawat halaga x i (\displaystyle x_(i)) sa sample. Nahanap mo na ang mga squared differences (x i (\displaystyle (x_(i)))-x̅) 2 (\displaystyle ^(2)) para sa bawat halaga x i (\displaystyle x_(i)) sa sample; ngayon idagdag lamang ang mga parisukat na ito.
- Sa aming halimbawa: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Hatiin ang resulta sa n - 1, kung saan ang n ay ang bilang ng mga halaga sa sample. Ilang oras na ang nakalipas, upang kalkulahin ang sample na pagkakaiba, hinati lang ng mga istatistika ang resulta sa n; sa kasong ito, makukuha mo ang mean ng squared variance, na mainam para sa paglalarawan ng variance ng isang ibinigay na sample. Ngunit tandaan na ang anumang sample ay maliit na bahagi lamang. populasyon mga halaga. Kung kukuha ka ng ibang sample at gagawin ang parehong mga kalkulasyon, makakakuha ka ng ibang resulta. Sa lumalabas, ang paghahati sa n - 1 (sa halip na n lang) ay nagbibigay ng mas mahusay na pagtatantya ng pagkakaiba-iba ng populasyon, na siyang hinahanap mo. Ang paghahati sa n - 1 ay naging karaniwan, kaya ito ay kasama sa formula para sa pagkalkula ng sample na pagkakaiba.
- Sa aming halimbawa, ang sample ay may kasamang 6 na halaga, iyon ay, n = 6.
Sample na pagkakaiba = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- Sa aming halimbawa, ang sample ay may kasamang 6 na halaga, iyon ay, n = 6.
-
Ang pagkakaiba sa pagitan ng pagkakaiba at ang karaniwang paglihis. Tandaan na ang formula ay naglalaman ng isang exponent, kaya ang pagkakaiba ay sinusukat sa mga square unit ng nasuri na halaga. Minsan ang naturang halaga ay medyo mahirap gamitin; sa ganitong mga kaso, gamitin ang standard deviation, na katumbas ng parisukat na ugat mula sa pagpapakalat. Iyon ang dahilan kung bakit ang sample na pagkakaiba ay tinutukoy bilang s 2 (\displaystyle s^(2)), a karaniwang lihis mga sample - paano s (\displaystyle s).
- Sa aming halimbawa, ang sample na standard deviation ay: s = √33.2 = 5.76.
Pagkalkula ng pagkakaiba-iba ng populasyon
-
Suriin ang ilang hanay ng mga halaga. Kasama sa set ang lahat ng mga halaga ng dami na isinasaalang-alang. Halimbawa, kung pinag-aaralan mo ang edad ng mga residente ng rehiyon ng Leningrad, kung gayon ang populasyon ay kasama ang edad ng lahat ng mga residente ng rehiyong ito. Sa kaso ng pagtatrabaho sa isang pinagsama-samang, inirerekumenda na lumikha ng isang talahanayan at ipasok ang mga halaga ng pinagsama-samang ito. Isaalang-alang ang sumusunod na halimbawa:
- Mayroong 6 na aquarium sa isang partikular na silid. Ang bawat aquarium ay naglalaman ng sumusunod na bilang ng mga isda:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- Mayroong 6 na aquarium sa isang partikular na silid. Ang bawat aquarium ay naglalaman ng sumusunod na bilang ng mga isda:
-
Isulat ang formula para sa pagkalkula ng pagkakaiba-iba ng populasyon. Dahil kasama sa set ang lahat ng value ng isang tiyak na dami, pinapayagan ka ng formula sa ibaba na makuha eksaktong halaga pagkakaiba-iba ng populasyon. Upang makilala ang pagkakaiba ng populasyon mula sa sample na pagkakaiba (na isang pagtatantya lamang), gumagamit ang mga istatistika ng iba't ibang mga variable:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n
- σ 2 (\displaystyle ^(2))- pagkakaiba-iba ng populasyon (basahin bilang "sigma squared"). Ang dispersion ay sinusukat sa square units.
- x i (\displaystyle x_(i))- bawat halaga sa pinagsama-samang.
- Ang Σ ay ang tanda ng kabuuan. Iyon ay, para sa bawat halaga x i (\displaystyle x_(i)) ibawas ang μ, parisukat ito, at pagkatapos ay idagdag ang mga resulta.
- μ ay ang ibig sabihin ng populasyon.
- n ay ang bilang ng mga halaga sa pangkalahatang populasyon.
-
Kalkulahin ang ibig sabihin ng populasyon. Kapag nagtatrabaho sa pangkalahatang populasyon, ang average na halaga nito ay tinutukoy bilang μ (mu). Ang ibig sabihin ng populasyon ay kinakalkula bilang karaniwang ibig sabihin ng aritmetika: idagdag ang lahat ng mga halaga sa populasyon, at pagkatapos ay hatiin ang resulta sa bilang ng mga halaga sa populasyon.
- Tandaan na ang mga average ay hindi palaging kinakalkula bilang arithmetic mean.
- Sa aming halimbawa, ang ibig sabihin ng populasyon ay: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Ibawas ang ibig sabihin ng populasyon sa bawat halaga sa populasyon. Kung mas malapit ang halaga ng pagkakaiba sa zero, mas malapit ang partikular na halaga sa ibig sabihin ng populasyon. Hanapin ang pagkakaiba sa pagitan ng bawat halaga sa populasyon at ang ibig sabihin nito, at makikita mo ang unang pagtingin sa pamamahagi ng mga halaga.
- Sa aming halimbawa:
x 1 (\displaystyle x_(1))- μ = 5 - 10.5 = -5.5
x 2 (\displaystyle x_(2))- μ = 5 - 10.5 = -5.5
x 3 (\displaystyle x_(3))- μ = 8 - 10.5 = -2.5
x 4 (\displaystyle x_(4))- μ = 12 - 10.5 = 1.5
x 5 (\displaystyle x_(5))- μ = 15 - 10.5 = 4.5
x 6 (\displaystyle x_(6))- μ = 18 - 10.5 = 7.5
- Sa aming halimbawa:
-
Square bawat resulta na makukuha mo. Ang mga halaga ng pagkakaiba ay parehong positibo at negatibo; kung ilalagay mo ang mga halagang ito sa isang linya ng numero, magsisinungaling sila sa kanan at kaliwa ng ibig sabihin ng populasyon. Hindi ito angkop para sa pagkalkula ng pagkakaiba, dahil positibo at mga negatibong numero bayaran ang bawat isa. Samakatuwid, parisukat ang bawat pagkakaiba upang makakuha ng mga eksklusibong positibong numero.
- Sa aming halimbawa:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) para sa bawat halaga ng populasyon (mula i = 1 hanggang i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), saan x n (\displaystyle x_(n)) ay ang huling halaga sa populasyon. - Upang kalkulahin ang average na halaga ng mga resulta na nakuha, kailangan mong hanapin ang kanilang kabuuan at hatiin ito sa n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / n
- Ngayon isulat natin ang paliwanag sa itaas gamit ang mga variable: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n at kumuha ng formula para sa pagkalkula ng pagkakaiba-iba ng populasyon.
- Sa aming halimbawa:
Ang pahinang ito ay naglalarawan ng isang karaniwang halimbawa ng paghahanap ng pagkakaiba, maaari mo ring tingnan ang iba pang mga gawain para sa paghahanap nito
Halimbawa 1. Pagpapasiya ng pangkat, average ng pangkat, sa pagitan ng pangkat at kabuuang pagkakaiba
Halimbawa 2. Paghahanap ng variance at coefficient ng variation sa isang grouping table
Halimbawa 3. Paghahanap ng pagkakaiba sa discrete na serye
Halimbawa 4. Mayroon kaming sumusunod na data para sa isang pangkat ng 20 mga mag-aaral sa pagsusulatan. Kailangang magtayo serye ng pagitan distribusyon ng feature, kalkulahin ang mean value ng feature at pag-aralan ang variance nito
Bumuo tayo ng interval grouping. Tukuyin natin ang saklaw ng pagitan sa pamamagitan ng formula:
![]()
kung saan ang X max ay ang maximum na halaga ng feature ng pagpapangkat;
Ang X min ay ang pinakamababang halaga ng feature ng pagpapangkat;
n ay ang bilang ng mga pagitan:
Tinatanggap namin ang n=5. Ang hakbang ay: h \u003d (192 - 159) / 5 \u003d 6.6
Gumawa tayo ng interval grouping

Para sa karagdagang mga kalkulasyon, bubuo kami ng isang auxiliary table:

X "i - ang gitna ng agwat. (halimbawa, ang gitna ng agwat 159 - 165.6 \u003d 162.3)
average na halaga ang paglaki ng mga mag-aaral ay tinutukoy ng formula ng arithmetic weighted average:

Tinutukoy namin ang pagpapakalat sa pamamagitan ng formula:
Ang formula ay maaaring ma-convert tulad nito:

Mula sa formula na ito ay sinusundan iyon ang pagkakaiba ay ang pagkakaiba sa pagitan ng ibig sabihin ng mga parisukat ng mga opsyon at ang parisukat at ang ibig sabihin.
Pagpapakalat sa serye ng pagkakaiba-iba na may pantay na pagitan ayon sa paraan ng mga sandali ay maaaring kalkulahin sa sumusunod na paraan gamit ang pangalawang pag-aari ng pagpapakalat (paghahati sa lahat ng mga pagpipilian sa halaga ng pagitan). Kahulugan ng pagkakaiba-iba, na kinakalkula sa pamamagitan ng paraan ng mga sandali, ayon sa sumusunod na pormula ay mas kaunting oras.

kung saan ang i ay ang halaga ng pagitan;
A - conditional zero, na kung saan ay maginhawa upang gamitin ang gitna ng agwat na may pinakamataas na dalas;
m1 ay ang parisukat ng sandali ng unang pagkakasunud-sunod;
m2 - sandali ng pangalawang pagkakasunud-sunod
pagkakaiba-iba ng tampok (kung sa istatistikal na populasyon ang katangian ay nagbabago sa paraang mayroon lamang dalawang magkaparehong eksklusibong mga opsyon, kung gayon ang ganitong pagkakaiba-iba ay tinatawag na alternatibo) ay maaaring kalkulahin ng formula:

Ang pagpapalit sa dispersion formula na ito q = 1- p, nakukuha natin:

Mga uri ng pagpapakalat
Kabuuang pagkakaiba sinusukat ang pagkakaiba-iba ng isang katangian sa kabuuan ng populasyon sa ilalim ng impluwensya ng lahat ng mga salik na nagdudulot ng pagkakaiba-iba na ito. Ito ay katumbas ng mean square ng mga deviations ng mga indibidwal na value ng feature x mula sa kabuuang mean value x at maaaring tukuyin bilang simpleng variance o weighted variance.
Pagkakaiba-iba sa loob ng pangkat nagpapakilala ng random na pagkakaiba-iba, i.e. bahagi ng pagkakaiba-iba, na dahil sa impluwensya ng hindi natukoy na mga salik at hindi nakadepende sa trait-factor na pinagbabatayan ng pagpapangkat. Ang nasabing pagkakaiba-iba ay katumbas ng mean square ng mga paglihis ng mga indibidwal na halaga ng isang tampok sa loob ng pangkat X mula sa arithmetic mean ng pangkat at maaaring kalkulahin bilang isang simpleng pagkakaiba-iba o bilang isang timbang na pagkakaiba-iba.
Sa ganitong paraan, mga hakbang sa pagkakaiba-iba sa loob ng pangkat pagkakaiba-iba ng isang katangian sa loob ng isang pangkat at tinutukoy ng formula:

kung saan xi - average ng grupo;
ni ay ang bilang ng mga yunit sa pangkat.
Halimbawa, ang mga pagkakaiba-iba ng intra-grupo na kailangang matukoy sa gawain ng pag-aaral ng impluwensya ng mga kwalipikasyon ng mga manggagawa sa antas ng produktibidad ng paggawa sa isang tindahan ay nagpapakita ng mga pagkakaiba-iba sa output sa bawat grupo na dulot ng lahat ng posibleng mga kadahilanan (teknikal na kondisyon ng kagamitan, pagkakaroon ng mga kasangkapan at materyales, edad ng mga manggagawa, lakas ng paggawa, atbp.), maliban sa mga pagkakaiba sa kategorya ng kwalipikasyon (sa loob ng grupo, lahat ng manggagawa ay may parehong kwalipikasyon).
Magkalkula tayoMSEXCELvariance at standard deviation ng sample. Kinakalkula din namin ang pagkakaiba-iba ng isang random na variable kung ang pamamahagi nito ay kilala.
Isaalang-alang muna pagpapakalat, pagkatapos karaniwang lihis.
Sample na pagkakaiba
Sample na pagkakaiba (sample na pagkakaiba-iba,samplepagkakaiba-iba) ay nagpapakilala sa pagkalat ng mga halaga sa array na may kaugnayan sa .
Ang lahat ng 3 formula ay katumbas ng matematika.
Makikita sa unang formula na sample na pagkakaiba-iba ay ang kabuuan ng mga squared deviations ng bawat value sa array mula sa karaniwan hinati sa laki ng sample na minus 1.
pagpapakalat mga sample ang DISP() function ay ginagamit, eng. ang pangalan ng VAR, i.e. VARIance. Mula noong MS EXCEL 2010, inirerekumenda na gamitin ang analogue na DISP.V() , eng. ang pangalang VARS, i.e. Sample na Pagkakaiba. Bilang karagdagan, simula sa bersyon ng MS EXCEL 2010, mayroong isang DISP.G () function, eng. Pangalan ng VARP, ibig sabihin. VARIance ng populasyon na kinakalkula pagpapakalat para sa populasyon. Ang buong pagkakaiba ay bumaba sa denominator: sa halip na n-1 tulad ng DISP.V() , DISP.G() ay mayroon lamang n sa denominator. Bago ang MS EXCEL 2010, ginamit ang VARP() function upang kalkulahin ang pagkakaiba-iba ng populasyon.
Sample na pagkakaiba
=SQUARE(Sample)/(COUNT(Sample)-1)
=(SUMSQ(Sample)-COUNT(Sample)*AVERAGE(Sample)^2)/ (COUNT(Sample)-1)- ang karaniwang formula
=SUM((Sample -AVERAGE(Sample))^2)/ (COUNT(Sample)-1) –
Sample na pagkakaiba ay katumbas ng 0 lamang kung ang lahat ng mga halaga ay katumbas ng bawat isa at, nang naaayon, ay pantay ibig sabihin ng halaga. Kadalasan, mas malaki ang halaga pagpapakalat, mas malaki ang pagkalat ng mga halaga sa array.
Sample na pagkakaiba ay pagtatantya ng punto pagpapakalat distribusyon ng random variable kung saan ang sample. Tungkol sa construction mga pagitan ng kumpiyansa kapag nagsusuri pagpapakalat mababasa sa artikulo.
Pagkakaiba-iba ng isang random na variable
Upang makalkula pagpapakalat random variable, kailangan mong malaman ito.
Para sa pagpapakalat Ang random variable X ay kadalasang gumagamit ng notasyong Var(X). Pagpapakalat ay katumbas ng parisukat ng paglihis mula sa mean E(X): Var(X)=E[(X-E(X)) 2 ]
pagpapakalat kinakalkula ng formula:

kung saan ang x i ay ang halaga na maaaring kunin ng random variable, at ang μ ay ang average na halaga (), р(x) ay ang posibilidad na ang random variable ay kukuha ng halagang x.
Kung ang random variable ay mayroong , kung gayon pagpapakalat kinakalkula ng formula:

Dimensyon pagpapakalat tumutugma sa parisukat ng yunit ng pagsukat ng mga orihinal na halaga. Halimbawa, kung ang mga halaga sa sample ay mga sukat ng bigat ng bahagi (sa kg), kung gayon ang dimensyon ng pagkakaiba ay magiging kg 2 . Ito ay maaaring mahirap bigyang-kahulugan, samakatuwid, upang makilala ang pagkalat ng mga halaga, isang halaga na katumbas ng square root ng pagpapakalat – karaniwang lihis.
Ilang mga ari-arian pagpapakalat:
Var(X+a)=Var(X), kung saan ang X ay isang random na variable at ang a ay isang pare-pareho.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2=E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Ginagamit ang dispersion property na ito sa artikulo tungkol sa linear regression.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), kung saan ang X at Y ay mga random na variable, ang Cov(X;Y) ay ang covariance ng mga random na variable na ito.
Kung ang mga random na variable ay independyente, kung gayon ang kanilang covariance ay 0, at samakatuwid Var(X+Y)=Var(X)+Var(Y). Ang pag-aari na ito ng pagkakaiba ay ginagamit sa output.
Ipakita natin na para sa mga independiyenteng dami Var(X-Y)=Var(X+Y). Sa katunayan, Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Ang pag-aari na ito ng pagkakaiba ay ginagamit sa plot .
Sample na standard deviation
Sample na standard deviation ay isang sukatan kung gaano kalawak ang pagkakalat ng mga halaga sa sample ay nauugnay sa kanilang .
Sa pamamagitan ng kahulugan, karaniwang lihis katumbas ng square root ng pagpapakalat:

Karaniwang lihis hindi isinasaalang-alang ang magnitude ng mga halaga sa sampling, ngunit ang antas lamang ng pagkakalat ng mga halaga sa kanilang paligid gitna. Kumuha tayo ng isang halimbawa upang ilarawan ito.
Kalkulahin natin ang standard deviation para sa 2 sample: (1; 5; 9) at (1001; 1005; 1009). Sa parehong mga kaso, s=4. Malinaw na ang ratio ng standard deviation sa mga halaga ng array ay makabuluhang naiiba para sa mga sample. Para sa mga ganitong kaso, gamitin Ang koepisyent ng pagkakaiba-iba(Coefficient of Variation, CV) - ratio karaniwang lihis sa karaniwan aritmetika, ipinahayag bilang isang porsyento.
Sa MS EXCEL 2007 at mga naunang bersyon para sa pagkalkula Sample na standard deviation ang function na =STDEV() ay ginagamit, eng. ang pangalang STDEV, i.e. karaniwang lihis. Mula noong MS EXCEL 2010, inirerekomendang gamitin ang analogue nito = STDEV.B () , eng. pangalan STDEV.S, ibig sabihin. Halimbawang STandard Deviation.
Bilang karagdagan, simula sa bersyon ng MS EXCEL 2010, mayroong isang function na STDEV.G () , eng. pangalan STDEV.P, ibig sabihin. Population STandard Deviation na kinakalkula karaniwang lihis para sa populasyon. Ang buong pagkakaiba ay napupunta sa denominator: sa halip na n-1 tulad ng STDEV.V() , STDEV.G() ay mayroon lamang n sa denominator.
Karaniwang lihis maaari ding direktang kalkulahin mula sa mga formula sa ibaba (tingnan ang halimbawang file)
=SQRT(SQUADROTIV(Sample)/(COUNT(Sample)-1))
=SQRT((SUMSQ(Sample)-COUNT(Sample)*AVERAGE(Sample)^2)/(COUNT(Sample)-1))
Iba pang mga hakbang sa pagpapakalat
Ang SQUADRIVE() function ay kinakalkula gamit ang umm ng mga squared deviations ng mga halaga mula sa kanilang gitna. Ibabalik ng function na ito ang parehong resulta gaya ng formula =VAR.G( Sample)*SURIIN( Sample), saan Sample- isang sanggunian sa isang hanay na naglalaman ng hanay ng mga sample na halaga (). Ang mga kalkulasyon sa QUADROTIV() function ay ginawa ayon sa formula:

Ang SROOT() function ay isa ring sukatan ng scatter ng isang set ng data. Ang SIROTL() function ay kinakalkula ang average ng mga ganap na halaga ng mga paglihis ng mga halaga mula sa gitna. Ibabalik ng function na ito ang parehong resulta gaya ng formula =SUMPRODUCT(ABS(Sample-AVERAGE(Sample)))/COUNT(Sample), saan Sample- isang reference sa isang hanay na naglalaman ng hanay ng mga sample na halaga.
Ang mga kalkulasyon sa function na SROOTKL () ay ginawa ayon sa formula:

Pagkalat sa mga istatistika ay matatagpuan bilang mga indibidwal na halaga ng tampok sa parisukat ng . Depende sa paunang data, ito ay tinutukoy ng simple at may timbang na mga formula ng variance:
1. (para sa hindi nakagrupong data) ay kinakalkula ng formula:
2. Natimbang na pagkakaiba-iba (para sa isang serye ng variation):
 kung saan ang n ay ang dalas (repeatability factor X)
kung saan ang n ay ang dalas (repeatability factor X)
Isang halimbawa ng paghahanap ng pagkakaiba
Ang pahinang ito ay naglalarawan ng isang karaniwang halimbawa ng paghahanap ng pagkakaiba, maaari mo ring tingnan ang iba pang mga gawain para sa paghahanap nito
Halimbawa 1. Mayroon kaming sumusunod na data para sa isang pangkat ng 20 mga mag-aaral sa pagsusulatan. Kinakailangang bumuo ng isang serye ng pagitan ng pamamahagi ng tampok, kalkulahin ang ibig sabihin ng halaga ng tampok at pag-aralan ang pagkakaiba nito
 Bumuo tayo ng interval grouping. Tukuyin natin ang saklaw ng pagitan sa pamamagitan ng formula:
Bumuo tayo ng interval grouping. Tukuyin natin ang saklaw ng pagitan sa pamamagitan ng formula:
![]() kung saan ang X max ay ang maximum na halaga ng feature ng pagpapangkat;
kung saan ang X max ay ang maximum na halaga ng feature ng pagpapangkat;
Ang X min ay ang pinakamababang halaga ng feature ng pagpapangkat;
n ay ang bilang ng mga pagitan:
Tinatanggap namin ang n=5. Ang hakbang ay: h \u003d (192 - 159) / 5 \u003d 6.6
Gumawa tayo ng interval grouping
 Para sa karagdagang mga kalkulasyon, bubuo kami ng isang auxiliary table:
Para sa karagdagang mga kalkulasyon, bubuo kami ng isang auxiliary table:
 Ang X'i ay ang gitna ng pagitan. (halimbawa, ang gitna ng pagitan 159 - 165.6 = 162.3)
Ang X'i ay ang gitna ng pagitan. (halimbawa, ang gitna ng pagitan 159 - 165.6 = 162.3)
Ang average na paglaki ng mga mag-aaral ay tinutukoy ng formula ng arithmetic weighted average:
 Tinutukoy namin ang pagpapakalat sa pamamagitan ng formula:
Tinutukoy namin ang pagpapakalat sa pamamagitan ng formula:
Ang formula ng pagkakaiba ay maaaring ma-convert bilang mga sumusunod:
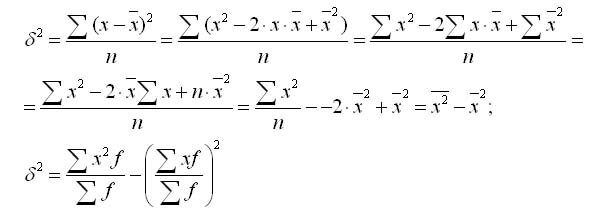
Mula sa formula na ito ay sinusundan iyon ang pagkakaiba ay ang pagkakaiba sa pagitan ng ibig sabihin ng mga parisukat ng mga opsyon at ang parisukat at ang ibig sabihin.
Pagkakaiba-iba sa serye ng pagkakaiba-iba na may pantay na pagitan ayon sa paraan ng mga sandali ay maaaring kalkulahin sa sumusunod na paraan gamit ang pangalawang pag-aari ng pagpapakalat (paghahati sa lahat ng mga pagpipilian sa halaga ng pagitan). Kahulugan ng pagkakaiba-iba, na kinakalkula sa pamamagitan ng paraan ng mga sandali, ayon sa sumusunod na pormula ay mas kaunting oras.

kung saan ang i ay ang halaga ng pagitan;
A - conditional zero, na kung saan ay maginhawa upang gamitin ang gitna ng agwat na may pinakamataas na dalas;
m1 ay ang parisukat ng sandali ng unang pagkakasunud-sunod;
m2 - sandali ng pangalawang pagkakasunud-sunod
(kung sa istatistikal na populasyon ang katangian ay nagbabago sa paraang mayroon lamang dalawang magkaparehong eksklusibong mga opsyon, kung gayon ang ganitong pagkakaiba-iba ay tinatawag na alternatibo) ay maaaring kalkulahin ng formula:

Ang pagpapalit sa dispersion formula na ito q = 1- p, nakukuha natin:

Mga uri ng pagpapakalat
Kabuuang pagkakaiba sinusukat ang pagkakaiba-iba ng isang katangian sa kabuuan ng populasyon sa ilalim ng impluwensya ng lahat ng mga salik na nagdudulot ng pagkakaiba-iba na ito. Ito ay katumbas ng mean square ng mga deviations ng mga indibidwal na value ng feature x mula sa kabuuang mean value x at maaaring tukuyin bilang simpleng variance o weighted variance.
nagpapakilala ng random na pagkakaiba-iba, i.e. bahagi ng pagkakaiba-iba, na dahil sa impluwensya ng hindi natukoy na mga salik at hindi nakadepende sa trait-factor na pinagbabatayan ng pagpapangkat. Ang nasabing pagkakaiba-iba ay katumbas ng mean square ng mga paglihis ng mga indibidwal na halaga ng isang tampok sa loob ng pangkat X mula sa arithmetic mean ng pangkat at maaaring kalkulahin bilang isang simpleng pagkakaiba-iba o bilang isang timbang na pagkakaiba-iba.
Sa ganitong paraan, mga hakbang sa pagkakaiba-iba sa loob ng pangkat pagkakaiba-iba ng isang katangian sa loob ng isang pangkat at tinutukoy ng formula:

kung saan xi - average ng grupo;
ni ay ang bilang ng mga yunit sa pangkat.
Halimbawa, ang mga pagkakaiba-iba ng intra-grupo na kailangang matukoy sa gawain ng pag-aaral ng impluwensya ng mga kwalipikasyon ng mga manggagawa sa antas ng produktibidad ng paggawa sa isang tindahan ay nagpapakita ng mga pagkakaiba-iba sa output sa bawat grupo na dulot ng lahat ng posibleng mga kadahilanan (teknikal na kondisyon ng kagamitan, pagkakaroon ng mga kasangkapan at materyales, edad ng mga manggagawa, lakas ng paggawa, atbp.), maliban sa mga pagkakaiba sa kategorya ng kwalipikasyon (sa loob ng grupo, lahat ng manggagawa ay may parehong kwalipikasyon).
Ang average ng mga pagkakaiba-iba sa loob ng pangkat ay sumasalamin sa random, ibig sabihin, ang bahagi ng pagkakaiba-iba na naganap sa ilalim ng impluwensya ng lahat ng iba pang mga kadahilanan, maliban sa kadahilanan ng pagpapangkat. Ito ay kinakalkula ng formula:

Inilalarawan nito ang sistematikong pagkakaiba-iba ng nagresultang katangian, na dahil sa impluwensya ng trait-factor na pinagbabatayan ng pagpapangkat. Ito ay katumbas ng ibig sabihin ng parisukat ng mga paglihis ng ibig sabihin ng grupo mula sa pangkalahatang mean. Ang pagkakaiba-iba ng intergroup ay kinakalkula ng formula:

Panuntunan sa pagdaragdag ng pagkakaiba-iba sa mga istatistika
Ayon kay panuntunan sa pagdaragdag ng pagkakaiba ang kabuuang pagkakaiba ay katumbas ng kabuuan ng average ng mga pagkakaiba-iba ng intragroup at intergroup:
![]()
Ang kahulugan ng panuntunang ito ay ang kabuuang pagkakaiba-iba na nangyayari sa ilalim ng impluwensya ng lahat ng mga salik ay katumbas ng kabuuan ng mga pagkakaiba-iba na lumitaw sa ilalim ng impluwensya ng lahat ng iba pang mga salik at ang pagkakaiba-iba na lumitaw dahil sa pangkat na kadahilanan.
Gamit ang formula para sa pagdaragdag ng mga pagkakaiba-iba, matutukoy natin sa pamamagitan ng dalawa kilalang mga pagkakaiba-iba ang pangatlong hindi alam, pati na rin upang hatulan ang lakas ng impluwensya ng tampok na pagpapangkat.
Mga Katangian ng Dispersion
1. Kung ang lahat ng mga halaga ng katangian ay nabawasan (nadagdagan) ng parehong pare-parehong halaga, kung gayon ang pagkakaiba ay hindi magbabago mula dito.
2. Kung ang lahat ng mga halaga ng katangian ay nabawasan (nadagdagan) ng parehong bilang ng beses n, ang pagkakaiba ay naaayon sa pagbaba (pagtaas) ng n^2 beses.



